Modular pipeline for Big Data processing
In the world of Big Data, even an apparently simple operation such as reading data and saving it, can prove to be complex.
The request
One of the greatest challenges we have ever faced during our long-standing collaboration with NextRoll was managing a very large volume of data. NextRoll is in fact the company behind the digital marketing and growth marketing platform AdRoll. With over 150 billion advertising auction bids per day, each to be processed within 100 milliseconds, NextRoll faces both big data and real-time processing challenges.
Challenges faced
In the world of Big Data, even an apparently simple operation such as reading data and saving it, possibly modifying values based on application logic, can prove to be complex and have a decidedly important cost. It was therefore necessary to adopt a tool that fully meets the requirements of the business and that has high performance and low operating costs.
Sometimes in life you also need the right opportunity and this came about in 2016, when one of our Develer teams flew to San Francisco for a meeting. Rumour has it that close meetings were held between NextRoll’s CTO and Develer’s CTO, and after a week the idea was set to be launched.
The solution
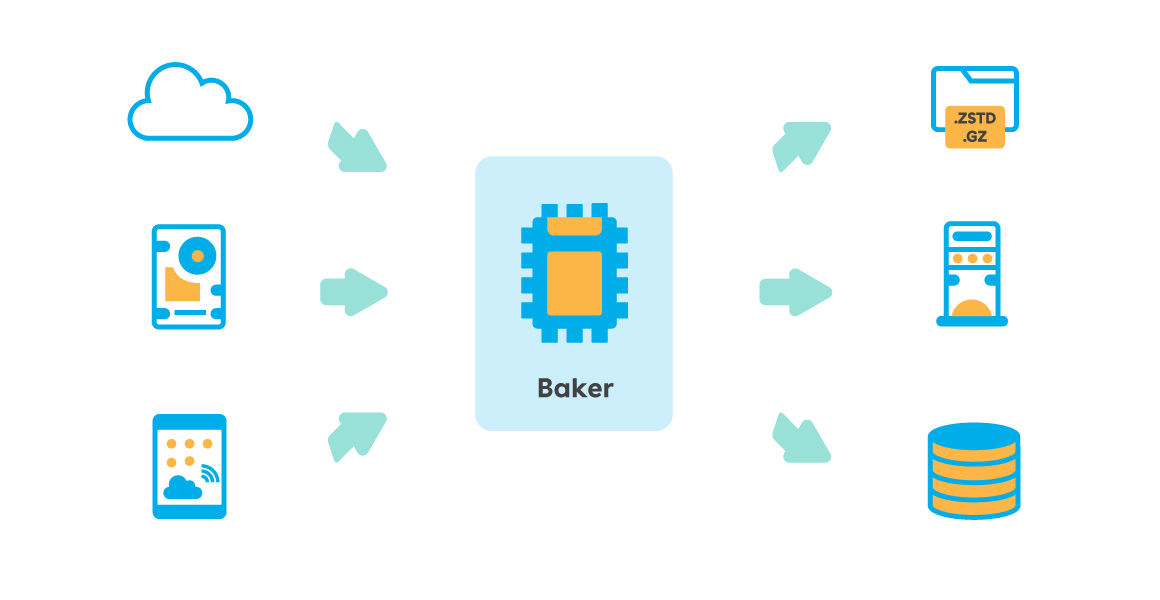
Over time that idea has germinated and transformed into a product that has been used for years in various parts of the NextRoll infrastructure: Baker (getbaker.io).
Baker is a modular pipeline written in Go for Big Data processing: it reads data from one or more sources, transforms it according to a wide variety of needs and writes it to another destination. Thanks to the variety of inputs and outputs available (the full list can be found at https://getbaker.io/docs/components/), Baker can be used in a large number of cases and contexts.
Baker’s design was conceived right from the start specifically to achieve high performance and its philosophy-inspired approach Linux “Do One Thing and Do It Well” (https://en.wikipedia.org/wiki/Unix_philosophy) ensures it does only one specific thing, but to the best of its ability. For this reason it deals exclusively with reading, processing and writing data and does not include, for example, logics to distribute the load between multiple instances.
Baker’s architecture is designed to take full advantage of the parallelism offered by modern CPUs: its pipelines can concurrently process read records, and even reading from the source or writing to the destination can, when supported, be parallelised.
Particular attention was paid to reducing the number of memory allocations as far as possible in order to minimise the cost of the garbage collector. The result of this careful design was truly outstanding and now Baker is able to process millions of records with very limited memory use (in the order of a few gigabytes even for the most complex pipelines).
OMFG (One-minute file generator) – A real use case
NextRoll’s infrastructure is responsible for both the production and consumption of PetaByte data, organised in what are called loglines (i.e. records in the form of specific and optimised CSVs).
These loglines are written at very high speed on an AWS streaming service called Amazon Kinesis, from where they are read by multiple consumers with a variety of needs. But reading from Kinesis can be tricky when dealing with multiple regions and in the event of high traffic volume. Added to this, the loss of data in the event of downtime is not acceptable.
For this reason, years ago NextRoll created OMFG (One Minute File Generator), a service created with the aim of reading the loglines from Kinesis and organising them into compressed files containing one minute of data. These one-minute files are saved on S3 in order to be available for all those downstream services that need “near real time” data.
The first version of OMFG, written in Java, was developed using Apache Storm and over time became expensive and unstable, not so much because of Storm, but more because of the presence of old and poorly maintained code. In terms of the drawbacks of Storm, however, it must be stated that it was very expensive from the point of view of resources and therefore had considerable costs.
For these reasons listed, it was therefore decided to replace Storm with Baker.
One of the main costs of the Storm-based solution was that it read Kinesis streams spread across 5 regions from a single AWS region. With Baker we therefore decided to adopt a distributed infrastructure, with one or more Baker instances for each region where a Kinesis stream was present. The data could then be read in the same region where it was produced (at no cost) and then moved in compressed form to the destination region (us-west-2). To further reduce costs, we finally used “spot” type instances, much cheaper, albeit slightly more complex to manage.
The final result was that of a very stable service and with 85% lower operating costs compared to the previous version (find out more in the NextRoll Blog)
Requirements
- To develop Baker using it to improve NextRoll’s technology infrastructure
- To release Baker as open-source
- To oversee the general management of the project and its maintenance
What did Develer do?
- Analysis of the requirements and of the criticalities of a series of NextRoll services
- The re-designing of these services, using Baker
- Software development, deployment and maintenance
- Release of Baker under an open-source licence
Results
- Amazing results in terms of reliability of managed services.
- Excellent ability to act on problems thanks to highly advanced infrastructure management tools
- Huge savings
How open source helped the project
Baker was written using Open Source technology such as Go. It is released with MIT License and the sources are downloadable from GitHub https://github.com/adroll/baker
Potential applications
Baker was conceived as a Big Data application in the cloud (and, in particular, for Amazon AWS). Despite this, Baker is a binary and not a service, designed to be highly efficient and resource-efficient. It is also capable of running on all major OSes. Given its origin, the area of the cloud is the one in which it can undoubtedly shine but its uses in the server field could be equally useful, for example to process server logs, or for embedded purposes, for the processing of data acquired directly on the board.
Big Data solutions
Looking for a Big Data application development partner?
The client
NextRoll, a company founded as a Startup in 2007 in San Francisco, is now one of the world’s largest players in the marketing technology platform field. Since then, NextRoll has built and improved data, infrastructure, and machine learning that powers growth for thousands of companies worldwide.
Staff
“By seamlessly integrating with other AdRoll teams, Develer helped achieve key objectives by performing to the same expectations as full-time employees. Their strong onboarding methods, reliable deliverables, and commitment to the AdRoll vision continue to strengthen the relationship”