Pipeline modulare per il processamento di Big Data
Nel mondo dei Big Data, anche un’operazione apparentemente semplice come leggere dei dati e salvarli può rivelarsi complessa.
La richiesta
Una delle sfide più importanti che ci siamo trovati ad affrontare durante la collaborazione, ormai di lunga data, con NextRoll è stata quella della gestione di un volume di dati molto importante. NextRoll è infatti la società dietro alla piattaforma di digital marketing e growth marketing AdRoll. Con oltre 150 miliardi di offerte per aste pubblicitarie al giorno, ciascuna delle quali da processare entro 100 millisecondi, NextRoll deve affrontare problematiche sia di Big Data che di processing real-time.
I problemi da affrontare
Nel mondo dei Big Data, anche un’operazione apparentemente semplice come leggere dei dati e salvarli, eventualmente modificando dei valori in base a logiche applicative, può rivelarsi complessa e avere un costo decisamente importante. Era quindi necessario adottare un tool che rispondesse pienamente ai requisiti del business e che avesse alte prestazioni e costi di esercizio bassi.
Nella vita, ogni tanto, serve anche l’occasione giusta, e questa si è presentata nel 2016, quando un nostro team Develer è volato a San Francisco per un incontro. Voci narrano di riunioni serrate tra il CTO di NextRoll e il CTO di Develer, e dopo una settimana l’idea era pronta a vedere la luce.
La soluzione
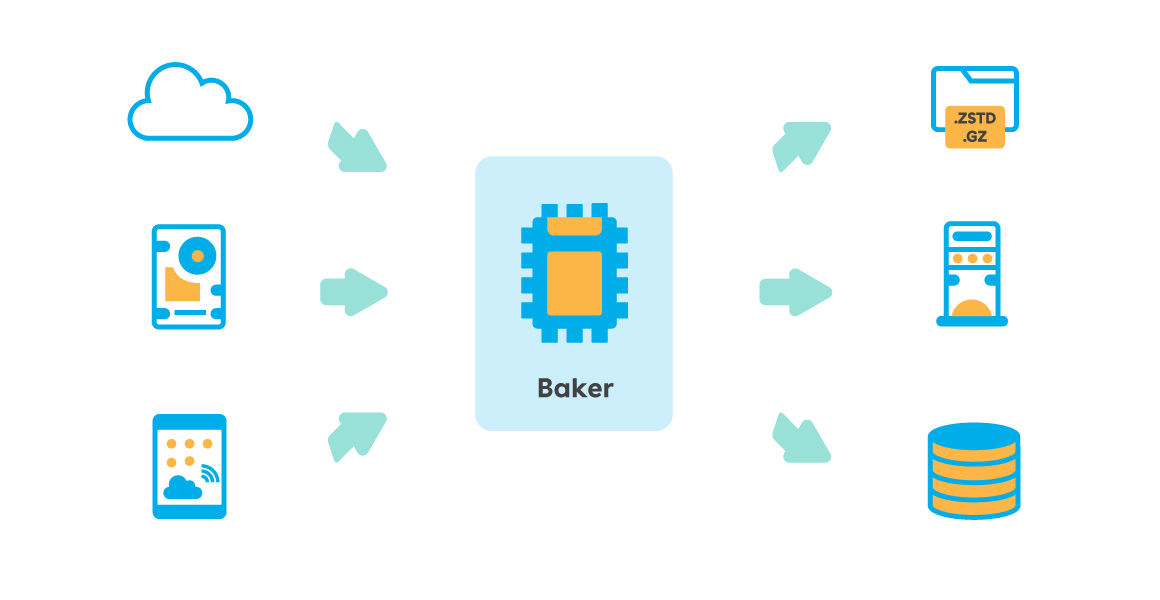
Con il tempo quell’idea è germogliata e si è trasformata in un prodotto usato ormai da anni in varie parti dell’infrastruttura NextRoll: Baker (getbaker.io).
Baker è una pipeline modulare scritta in Go per il processamento di Big Data: legge dati provenienti da una o più sorgenti, li trasforma a seconda delle più disparate esigenze e li scrive su un’altra destinazione. Grazie alla varietà di input e output messi a disposizione (l’elenco completo può essere trovato all’indirizzo https://getbaker.io/docs/components/), Baker può essere usato in un gran numero di casi e contesti.
Il design di Baker è stato pensato fin dall’inizio specificatamente per raggiungere alte prestazioni e il suo approccio ispirato alla filosofia Linux “Do One Thing and Do It Well” (https://en.wikipedia.org/wiki/Unix_philosophy) fa sì che faccia solo una cosa specifica, ma al meglio delle sue possibilità. Per questo si occupa esclusivamente di leggere, processare e scrivere dati e non include, ad esempio, logiche per distribuire il carico tra più istanze.
L’architettura di Baker è concepita per sfruttare appieno il parallelismo offerto dalle moderne CPU: le sue pipeline possono processare concorrentemente i record letti, e persino la lettura dalla sorgente o la scrittura sulla destinazione possono essere, quando supportate, parallelizzate.
È stata prestata particolare attenzione a ridurre il più possibile il numero di allocazioni di memoria, in modo da mantenere al minimo il costo del garbage collector. Il risultato di questa accurata progettazione è stato davvero ottimo e adesso Baker è in grado di processare milioni di record con un uso di memoria limitatissimo (nell’ordine di pochi gigabyte anche per le pipeline più complesse).
OMFG (One-minute file generator) – Un caso reale di utilizzo
L’infrastruttura di NextRoll è responsabile sia della produzione che del consumo di PetaByte di dati, organizzati in quelle che vengono chiamate loglines (ovvero dei record in forma di CSV specifici ed ottimizzati).
Tali loglines vengono scritte ad altissima velocità su un servizio di streaming di AWS chiamato Amazon Kinesis, dal quale vengono lette da più consumatori aventi esigenze differenti. Ma leggere da Kinesis può essere complicato quando si ha a che fare con più regioni, un alto volume di traffico e non è accettabile perdere dati in caso di downtime.
Per questo motivo, anni fa NextRoll creò OMFG (One Minute File Generator), un servizio nato con l’obiettivo di leggere le loglines da Kinesis ed organizzarle in file compressi contenenti un minuto di dati. Questi file da un minuto sono salvati su S3 in modo da essere disponibili per tutti quei servizi a valle che hanno bisogno di dati “quasi real time”.
La prima versione di OMFG, scritta in Java, venne sviluppata utilizzando Apache Storm e divenne nel tempo costosa e instabile, non tanto per colpa di Storm, quanto più per la presenza di codice vecchio e poco mantenuto. A carico di Storm, invece, bisogna dire che era molto esoso in termini di risorse e aveva quindi costi notevoli.
Per queste ragioni elencate, è stato quindi deciso di sostituire Storm con Baker.
Uno dei costi principali della soluzione basata su Storm era che questa andava a leggere da un’unica regione AWS gli stream Kinesis distribuiti su 5 regioni. Con Baker abbiamo quindi deciso di adottare un’infrastruttura distribuita, con una o più istanze di Baker per ogni regione dove fosse presente uno stream Kinesis. I dati potevano quindi essere letti nella stessa regione dove venivano prodotti (senza costi) e spostati poi in forma compressa sulla regione di destinazione (us-west-2). Per abbattere ulteriormente i costi, abbiamo infine utilizzato istanze di tipo “spot”, molto più economiche, seppur un po’ più complesse da gestire.
Il risultato finale è stato quello di un servizio molto stabile e con costi operativi inferiori dell’85% rispetto alla precedente versione (approfondimento nel blog Nextroll).
Le richieste
- Sviluppare Baker utilizzandolo per migliorare l’infrastruttura tecnologica di NextRoll
- Rilasciare Baker come open-source
- Occuparsi della gestione generale del progetto e della sua manutenzione
Cosa ha fatto Develer
- Analisi dei requisiti e delle criticità di una serie di servizi di NextRoll
- Ri-progettazione di questi servizi, usando Baker
- Sviluppo, deploy e manutenzione del software
- Rilascio di Baker sotto licenza open-source
Risultati
- Grandi risultati in termini di affidabilità dei servizi gestiti.
- Ottime capacità di intervento su problemi grazie a tool di gestione dell’infrastruttura molto evoluti
- Enormi risparmi
In quale modo l’open source ha aiutato il progetto
Baker è stato scritto utilizzando una tecnologia Open Source come Go, è rilasciato con MIT License e i sorgenti sono scaricabili da GitHub
Le potenziali applicazioni
Baker nasce come applicazione Big Data in ambito cloud (e, in particolare, per Amazon AWS). Nonostante ciò, Baker è un binario e non un servizio, progettato per essere altamente efficiente e parsimonioso in termini di risorse. È capace, inoltre, di essere eseguito su tutti gli OS principali. Stante la sua origine, l’ambito cloud è quello in cui sicuramente può brillare, ma altrettanto utili potrebbero rivelarsi suoi utilizzi in ambito server, ad esempio per processare dei log di un server, o in ambito embedded, per il processing dei dati acquisiti direttamente sulla board.
Soluzioni per Big Data
Cerchi un partner per lo sviluppo di applicazioni Big Data?
Il cliente
NextRoll, una società fondata come Startup nel 2007 a San Francisco, è oggi uno dei maggiori player mondiali nel campo delle piattaforme tecnologiche di marketing. Da allora, NextRoll ha aiutato migliaia di aziende ad utilizzare dati, infrastrutture e machine learning per la propria crescita.
Staff
“Integrandosi perfettamente con gli altri team di AdRoll, Develer ha contribuito a raggiungere i nostri obiettivi chiave con le stesse performance del nostro personale interno. I loro metodi di onboarding, la puntualità nelle consegne e l’impegno verso la visione di AdRoll continuano a rafforzare la collaborazione”