Ensuring the reliability of an embedded Linux system
Introduction
Over the past decade, Linux has steadily gained ground in the industrial world, fueled by Moore’s Law: increasingly powerful processors have become available at ever more competitive prices.
The advent of build systems like Buildroot and Yocto—which make it possible to create a complete embedded Linux system with just a few clicks—has further accelerated this adoption. Today, nearly every manufacturer of embedded processors and microcontrollers offers some form of support for Linux integration.
In this article, we’ll look at a key challenge for embedded systems in the field: how to ensure that they remain operational in (almost) any scenario.
Challenges for Systems in the Field
One of the most crucial features of any industrial system is reliability—the ability to maintain normal operations over time, especially in the face of unexpected events like failures, anomalies, or human error.
Several issues can arise over a system’s lifetime that may impact its functionality. Some of these problems are even inherent to the way the system is built and operated. Common examples include:
- Hardware issues due to design flaws, component degradation, or memory corruption
- Software bugs or misconfigurations that compromise stability
- Unexpected events such as power loss or incorrect handling by users
These issues often come to light during system updates. Updating an embedded system is rarely optional—it’s often necessary to:
- Fix bugs discovered during operation
- Address security vulnerabilities introduced by third-party components
- Add features that were not part of the original specification
However, updates can also introduce their own problems. If not managed correctly, they can leave the system in an inconsistent state, rendering it non-functional—or worse, causing erratic or dangerous behavior. Even a successful update may cause unforeseen issues if no fallback mechanism is in place.
In such cases, the only solution is manual intervention to restore the system—an option that might be costly or even impossible, especially if the device is deployed in the field or embedded in a product. This is why it’s essential to design systems with built-in safeguards and recovery mechanisms.
Read-Only Root Filesystems
A common first step toward system reliability is mounting the root file system as read-only. This simple but effective strategy helps protect against file system corruption caused by power failures or software bugs.
In this setup, all writable data—such as logs and application data—is stored on a separate writable partition. While this approach doesn’t prevent all failures, it offers a solid foundation and is often combined with other techniques described below.
Dual-Partition Systems
Maintaining multiple copies of the system on the same storage device is another widely used technique. It helps protect against corruption of the system partition, especially when:
- The system is often shut down by cutting power
- System updates modify the root partition
- The device is difficult to access physically for maintenance
Benefits of this approach include:
- Low implementation cost (no extra hardware needed)
- Minimal custom software requirements (basic partition switching logic)
- No additional maintenance burden
This mechanism is usually implemented in the second-stage bootloader (e.g. U-Boot or Barebox for ARM platforms), which can manage partitions and file systems.
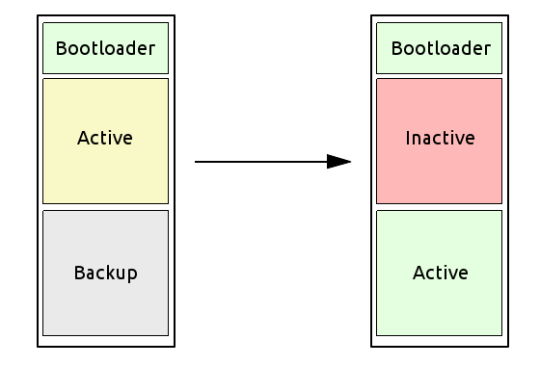
The storage (typically flash or eMMC) is split into two partitions:
- One contains the active file system used at boot time
- The other serves as a backup, kept in a consistent state
At boot, the bootloader checks the status of the active partition. If the check fails, the system switches to the backup partition.
Several techniques can be used to validate the active partition:
- A status file stored in a known location
- Bootloader environment variables accessible from both Linux and the bootloader
- A small dedicated status partition
- An external memory device (e.g., EEPROM)
Limitations:
- Does not protect against hardware failures in the storage device (single point of failure)
Provides limited recovery—only from one failure event - Halves available storage space
Systems with Multiple Storage Devices
To overcome the limitations of dual-partition systems, the next step is to store the backup system on a separate memory device. This brings two major advantages:
- The main storage is fully available for the primary system
- Redundancy across devices eliminates the single point of failure
There are two main approaches:
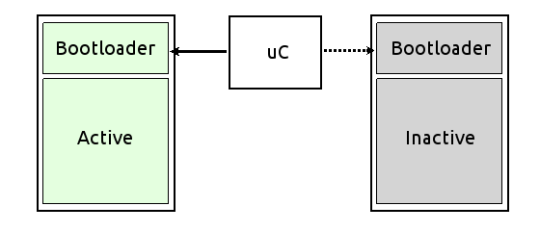
Full system copy
The backup memory contains a complete system image. Both memories are usually of the same type, and the bootloader selects one at boot.
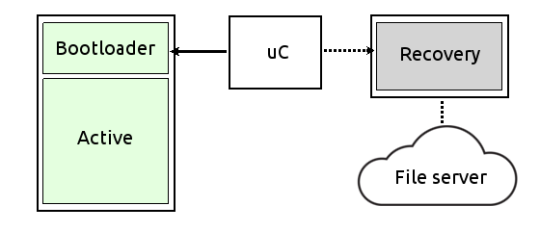
Minimal recovery system
The backup memory holds a small, compressed system image that’s loaded into RAM and executed at boot. Its job is to restore the main partition, for example by downloading a clean system image from a remote server. These memories are typically smaller and connected via SPI or similar low-speed buses.
Pros and Cons
- The first approach increases hardware cost and complexity
- The second saves on hardware but requires a more sophisticated recovery infrastructure and software stack
Looking for a Linux embedded course?
Discover our courses
Remote Recovery Systems
An evolution of the previous model moves the entire recovery process into the bootloader itself. Instead of booting a minimal recovery system from a separate memory, the bootloader is responsible for restoring the main system by:
- Formatting the main partition
- Downloading a new system image from a server
- Decompressing and, if needed, decrypting the image
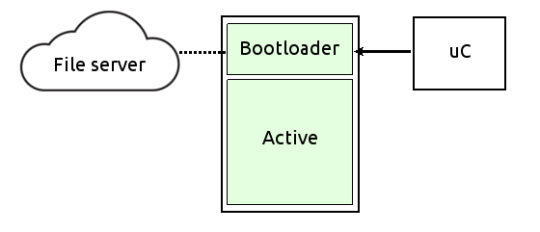
This approach simplifies hardware design but adds requirements for the bootloader, which must support:
- Network hardware
- A full TCP/IP stack
- Protocols such as HTTP or FTP, plus authentication (e.g., SSL, Basic Auth)
- Image decompression and decryption
Conclusion
There are many ways to improve the reliability of embedded Linux systems, each with trade-offs in complexity, cost, and capabilities. The techniques discussed here are some of the most common but by no means exhaustive.
The best approach depends on your specific hardware and software environment, the system’s intended use, and the level of fault tolerance required. Carefully evaluating these factors will help you build robust systems that keep running—no matter what happens in the field.