Whether you love it or hate it, Go is a language that will be talked about for many years to come. One of the many reasons for its initial success lies in the tools that the language provides with regard to parallelism and concurrency. It’s worth taking a quick look at the three basic functions of Go in order to understand the concurrency model: goroutines, channels, and the select construct.
Serial programs in a parallel world
Writing software means solving problems. It often means doing so by putting one instruction after another in a serial manner, one concept at a time. Most of the code we write usually follows this routine.
The problem is that the world is not serial. Reality is intrinsically parallel. Multiple events happen simultaneously with effects that interfere with each other. More than a sequential line of actions, reality is a chaotic network of parallel situations. If we want to solve real problems, we need to come to terms with all of this.
Various tools have been studied over the years to handle parallelism: threads, mutexes, tasks, coroutines, etc. Nevertheless, Go addresses this concept and places it at the center of its design, and in doing so, tries to use more modern tools.
The most used application today is no longer a program launched by a user on a computer that is running on a CPU. The most widely used applications today are webapps.
That means that we’re talking about intrinsically parallel applications that operate the data of millions of users, distributed on multiple servers, with multiple services provided by multiple machines located in various parts of the world. Furthermore, the standard CPU of today is definitely a multicore CPU. This radical change deserves an important rethinking in terms of language tools. Concurrency becomes an essential element.
Concurrency is not parallelism
It might seem like a trivial question, but what we are actually talking about when we bring up parallelism and concurrency?
Concurrency is a design perspective. It’s the composition of things (often functions) that can be performed independently from each other. When we talk about concurrency, we are usually talking about how to design the code structure to handle simultaneous and concurrent executions.
Parallelism, instead, is the act of actually performing functions simultaneously. This often depends on hardware characteristics (single-core vs multi-core) and the operating system—characteristics which are often unknown while writing the code and are hence sensible to disengage from.
Our attention now turns to concurrency, which is the design of the code. Let’s get acquainted with goroutines.
Goroutines
Let’s do a few examples. Let’s say we have three functions that perform CPU-intensive calculations.
package main
func doCalc1() {
// 2 seconds spent here...
}
func doCalc2() {
// 2 seconds spent here...
}
func doCalc3() {
// 2 seconds spent here...
}
func main() {
// ...
// insert long program here...
// ...
doCalc1()
doCalc2()
doCalc3()
// ...
// insert rest of the program here...
// ...
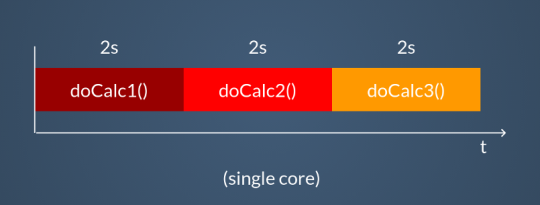
}Calling these functions in sequence is the simplest and most well-known approach. Clearly, the result will be to wait for the sum of the waiting times of each single function. There’s no magic here, it’s what we’d expect.
We can do better. We can turn these functions into a goroutine simply by adding the keyword go at the time of the call.
go doCalc1()
go doCalc2()
go doCalc3()In this way we’re adding information; we are marking the execution of these three functions so that they happen simultaneously. These functions are independent of each other and can be executed at the same time. Take note: this is a “high-level” choice.
The result is that the functions will no longer be launched in sync; they’ll be handled by the Go runtime scheduler. We can see goroutines as microthreads. In short, they are:
- performed independently
- lightweight micro-threads
- fast
- low overhead
- stack-efficient
Unlike threads, goroutines are very light with practically zero overhead. It’s absolutely normal to have thousands and thousands of goroutines running in your program.
The result of using goroutines in the place of functions, as far as performance is concerned, depends entirely on the nature of these functions and on the hardware’s parallelism capability.
We have two notable cases where we particularly benefit from having goroutines:
- we’re executing I/O-bound tasks
- we’re running CPU-bound tasks on a multi-core processor
In the first case, we find ourselves making the most of CPU parallelism by executing multiple goroutines. For instance, let’s say we have three functions to execute in sequence, which respectively employ one second of CPU-bound calculations, two seconds of calculations, and a wait input of about two seconds for the third one.
func doSlimCalc() {} // 1 second
func doFatCalc() {} // 2 seconds
func getData() {} // 2 seconds I/O wait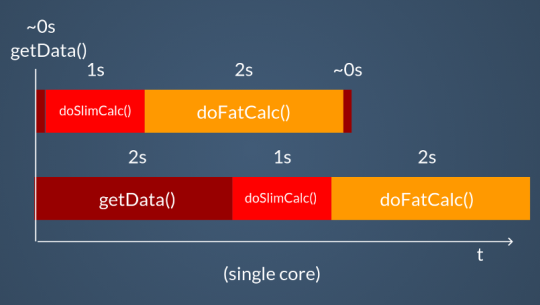
Even on a single core, you’ll still have a performance advantage, as the goroutines waiting for I/O will be paused and the others will be carried out in the meantime.
If the CPU is multi-core, there will be another advantage, namely the effective parallelization of the goroutines on several cores. Let’s see the three systems compared in the graph.
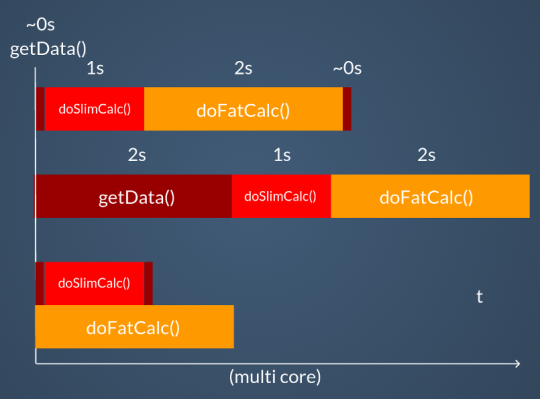
However, the situation becomes complicated when our functions must somehow interact with each other. In this case we want to avoid using the common tools (which in any case are available in the standard library), such as lock, mutex, traffic lights, etc., and we’ll use channels instead.
Channels
Channels are, as the name suggests, communication channels. They are:
- mono or bidirectional
- concurrency-safe
- typed
- first-class citizens
Channels are the right way to synchronize goroutines by managing data and memory. They are typed and first-class citizens, so they can be passed as parameters to functions, saved in variables, and so on.
// Creation of a channel
ch1 := make(chan int)
// Entering of a data item in the channel
ch1 <- 1
// Reading of a datum from the channel
num := <- ch1Let’s look at an example:
package main
import (
"fmt"
"time"
)
func main() {
ch1 := make(chan string)
go func() {
ch1 <- "Hello"
ch1 <- "World!"
}()
go func() {
for {
fmt.Println(<-ch1)
}
}()
time.Sleep(1 * time.Second)
}Two functions launched as goroutines communicate through a string channel. The first produces words and the second writes to the screen. As we’ve already seen for goroutines, we can also see how easy it is to use channels.
When using channels, we must keep a maxim in mind that explains the design philosophy:
Don’t communicate by sharing memory. Share memory by communicating.
In other words:
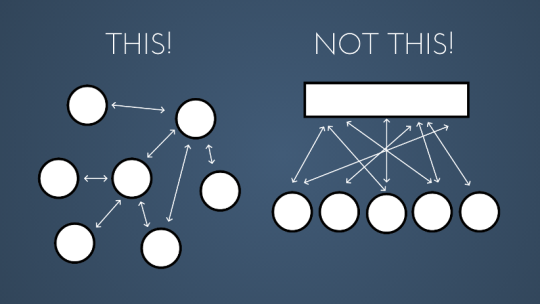
The basic idea is to build a structure that uses communication channels to synchronize and share memory, rather than having a shared memory area to protect in order to avoid race conditions.
In addition, channels offer us the convenience of being sufficiently high-level to hide the implementation details that are necessary for correct parallelism management.
When two goroutines connect to the two sides of a channel, one waiting for data, the other to send data, there is a moment of synchronization.
Select
A piece is still missing. In a real case we’ll actually have dozens and dozens of channels, we’ll have different waiting points with thousands of goroutines at work, and we’ll want to manage all of this efficiently.
Take a look at these two functions:
func producerSlow(output chan string) {
for {
output <- "Message!"
time.Sleep(1 * time.Second)
}
}
func producerFast(output chan int) {
for {
output <- rand.Int()
time.Sleep(500 * time.Millisecond)
}
}These functions do something very common: they take a channel as a parameter and use that channel as a communication channel to input data. In this very simple example, the two producers have different processing times.
Let’s say we want to print this data on screen. Our consumer will therefore be a print. A first way to handle this situation could be:
func main() {
ch1 := make(chan string)
ch2 := make(chan int)
go producerSlow(ch1)
go producerFast(ch2)
for {
fmt.Println(<-ch1)
fmt.Println(<-ch2)
}
}The result is that we have a strong moment of synchronization in the consumer where we are canceling out the advantage of having goroutines.
Message!
5577006791947779410
Message!
8674665223082153551
Message!
6129484611666145821
Message!
4037200794235010051We’re going at the speed of the slowest goroutine. We can do better than that by using a select. Let’s see how.
func main() {
ch1 := make(chan string)
ch2 := make(chan int)
go producerSlow(ch1)
go producerFast(ch2)
for {
select {
case msg := <-ch1:
fmt.Println(msg)
case num := <-ch2:
fmt.Println(num)
}
}
}The select has several cases. The whole element is blocking the execution of the program as long as all its cases are blocked. In this case, the select remains on hold until one of its cases is unblocked and executed.
The first effect of this is that we’re taking advantage of our goroutines more efficiently.
Message!
3916589616287113937
6334824724549167320
Message!
605394647632969758
1443635317331776148The fastest goroutine is not forced to wait for the slower one. Its branch in the select will be the one that will be unblocked twice as much the slowest one, going as fast as possible.
The select therefore introduces a much more evolved synchronization mechanism. It’s a sorting point for the channels so they don’t wait unnecessarily for the program to read blocked channels.
This allows us to further extend our design with features such as wait timeout, for example. Let’s take the After function in the time module.
func After(d Duration) <-chan TimeThis function takes a duration and returns a channel of Time structures. The purpose of returning a channel is that by waiting on it, we’ll be unblocked only when the timeout given by the Duration parameterexpires.
select {
case msg := <-ch1:
fmt.Println(msg)
case num := <-ch2:
fmt.Println(num)
case <-time.After(250 * time.Millisecond):
fmt.Println("Timeout!")
}If after 250 milliseconds none of the select channels have been unblocked, the timeout one will definitely be coming out of the select block. All of this is done with just two lines of code. The possibilities are really endless.
Conclusions
Go offers a perspective on solid, effective, and simple concurrency. Goroutines, channels, and select are basic language tools that are easy to use and understand and are useful for building more sophisticated tools.
Go’s approach really makes designing asynchronous and parallel applications accessible to everyone.