Applications distributed with ZMQ Clone Pattern
ZMQ (or ZeroMQ) is a communication library that has recently made it possible to use messaging patterns in a simple way. When we have to get two software processes to communicate, very often the only way that we can think of is to use the client-server model, where the server part provides a service to one or more clients. In reality, this isn’t a real pattern because there are many ways that a service can be provided; in fact, it’s generally a quick way to identify which part is listening compared to which one is connecting. ZMQ tries to abstract the way two parts connect to each other, focusing instead on how we want messaging to take place. The following are the main built-in patterns of ZMQ:
- Request-Reply: Request for one or more services from clients, useful for implementing RPC mechanisms.
- Publisher-Subscriber: Data distribution via publication, useful for update notifications to an audience of receivers.
- Pipeline: Simultaneous task execution and distribution, useful for propagating data updates.
- Exclusive-Pair: Exclusive connection between two threads, useful for implementing IPC mechanisms.
ZMQ has various types of sockets to use basic messaging patterns. Through the basic patterns, you can then create second-level patterns, depending on the needs of the application that we want to set up. In this short article, I’ll explain the reasons that made it necessary to use an advanced messaging pattern such as the Clone Pattern.
Module interconnection problem
When we’re dealing with a distributed system or we want to separate the complex logic of our system into several independent modules, most importantly, we have to think about how they’ll have to communicate. This means more work and costs, so it isn’t always appropriate to make this decision, especially on small projects. Despite that, organizing in separate modules has some advantages, including:
- A smaller component usually has a lower complexity than a larger one, so it’s easier to maintain.
- It’s possible to work more easily on teams consisting of many people.
- It’s easier to limit responsibilities in case of malfunctions.
- One or more parts of the system can be updated while minimizing disruption.
- The system altogether scales better, if properly organized.
- A possible crash remains confined to the module that shows the bug.
Since the logic of the entire system is distributed across multiple modules, the state also appears to be distributed. Every module or component of the system has its own state. Often, the most immediate solution translates into a direct connection between the modules, as shown in the figure.
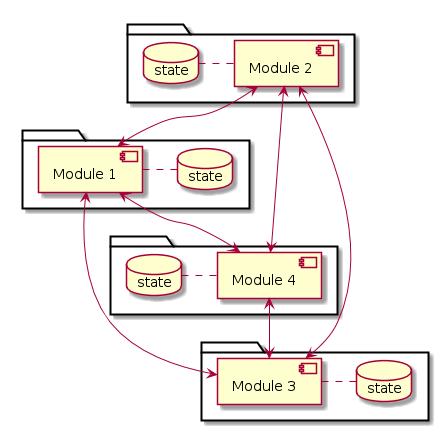
This decentralized architecture is very flexible as there are no constraints. Often, however, enormous flexibility translates into complex management. In reality, the communication mode, the state update policies, and the network endpoints have to be defined for each module. As the number N of modules increases, the tendency is to obtain NxN connections—a situation that isn’t always pleasant.
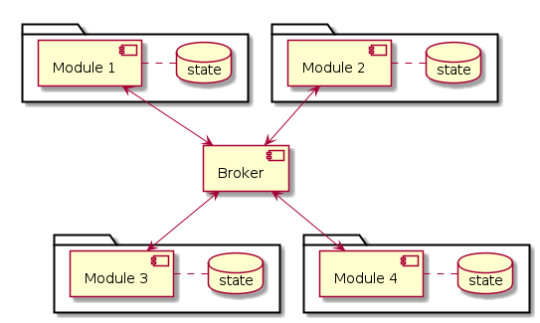
A centralized architecture can be used to make this problem more structured. In this type of architecture, there is a special component called the broker that sorts and stores for the distributed application’s state. Introducing a central component brings a series of pros and cons with it which are important to evaluate:
- With a broker, you can avoid network component discovery problems.
- Each component connects to the broker in the same way without having to redefine who binds and who connects every time.
- The broker is a bottleneck, so the level of data traffic has to be assessed.
- The system scales better as nodes increase, even if the broker’s data traffic increases. For instance, if the system consists of 100 modules, it will be easier to connect them all to the broker rather than to each other. Plus, adding a new module doesn’t involve modifying modules that are already present.
- There may be latency and jittering on sending messages depending on data traffic.
The following figure shows a centralized broker-based architecture.
State sharing
ZMQ’s Clone Pattern might be the solution for getting multiple modules to communicate with each other while sharing a common state. The system architecture is centralized and based on the broker. However, the broker’s task isn’t limited to just sorting messages; it also plays a role in common state storage. This storage function is a variation with respect to the generic centralized model described in the previous paragraph. This pattern isn’t one of the built-in ones; it uses other basic patterns to create a more complex one. The built-in patterns used in Clone are as follows:
- Publisher-Subscriber to distribute data updates to components.
- Pipeline to forward state updates and messages to the broker.
- Request-Reply to perform state synchronizations when a module is inserted into the network.
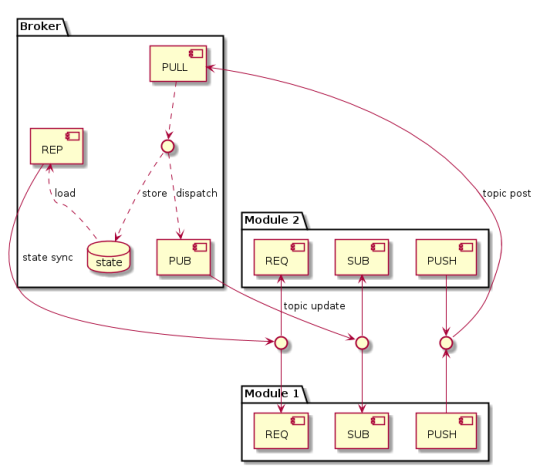
The broker makes state sharing possible since the software modules can’t directly communicate with each other. Let’s see what the mode of operation is for this mechanism in more detail:
- Synchronize operation. This is the first operation that a module has to complete when it’s inserted into the Clone network. The goal is to synchronize with all the broker’s states (or better yet, only the subparts we’re interested in). Synchronization takes place through a REQ-REP (request-reply) socket pair. The broker always listens for these state requests. Whenever it receives one, it interrupts its normal operation flow to serve the request and send the entire state to the module.
- Update operation. This represents the propagation style of data within the network and it occurs through a PUB-SUB (publisher-subscriber) socket pair. Each data type takes a topic category, and a module generally only subscribes to the topics that it’s interested in. We can say that the state is a set of key-value data, where the topic takes on the meaning of the key, and the value is a generic binary payload. During its normal operation, the broker publishes updates to the modules every time a change occurs in the data.
- Modify operation. This represents how a module alters state data. In particular, each module forwards its own state modification through a pair of PUSH-PULL (pipeline) sockets. The broker, in turn, sequentializes all the changes received from the modules and then updates its state and rewrites the modifications for each of them.
A correct implementation of this pattern has to take disconnections into account, which can occur between the broker and the other modules. This functionality can be implemented through a diagnostic mechanism with heartbeat packets sent continuously by the broker as if it were a normal distribution of data. Each component must detect this heartbeat and proceed with resynchronizing the state in case there’s a failure to communicate.
The Clone Pattern only defines the way that messages pass between one module and another, but doesn’t place constraints on the payload. In order for the software component interfaces to be clear and well-defined, the payload of the exchanged messages can be defined with other formalisms such as ASN.1, MessagePack, JSON, among others. This decision, however, belongs to the business logic of the applications.
We experienced a round-trip time of 2 ms per message when using this communication mechanism in a real system. In the presence of a pretty heavy load, like an 800-byte message every 200 ms, the latency ranges from 15 ms to 50 ms (indicative data). This performance is completely acceptable for non-real-time applications or for meeting tight deadlines.
State replicating
There are circumstances where replicating the state is crucial in order to have a certain degree of redundancy of the whole system. Redundancy can be used to increase the availability or security of a system. The practical case we want to discuss is relative to the first point. That is, we want to extend this centralized architecture to obtain a hot standby mechanism to increase availability. In this context we use the term system to define the set of all the modules connected to a broker that are running on a machine. We thus want to instantiate two systems and link them together in some way.
A possible solution is to connect the two brokers to each other. The broker component can be further extended so that inside, it has the same logic for connection and management that we find in the software modules. So a broker presents itself to the other as if it were a simple module (federation style approach), rather than having privileged communication channels (peering approach). The system broker that assumes the role of hot standby (system B) subscribes to the entire state of the active system (system A) without any limitation. System B will therefore get all the updates and will keep its state aligned with system A’s by design.
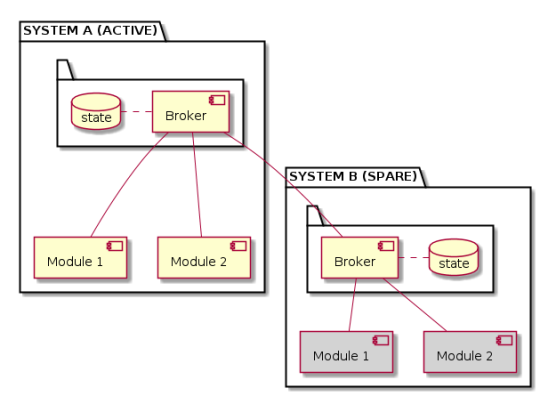
System B has the same modules as system A, but it can’t run until system A is up and running. Under this condition, system B’s only function is to maintain its aligned state. On the other hand, activating system B can take place with the same heartbeat mechanism defined earlier. For instance, if system A stops working, system B notices and takes over, becoming active. At that point, all of system B’s modules start up and the first operation they perform is synchronizing with their broker’s state. As a result, the overall functioning of the system is redundant, increasing availability.
Of course, there are some practical problems to solve to perform the changeover between the two units:
- The timeouts have to be calibrated correctly to ensure that the master system is really dead, otherwise unwanted changeovers might occur.
- It’s wise to have a double channel of communication between the two brokers to avoid a network failure being mistaken for a malfunction of the active system.
- The two systems have to arrive at a consensus if both are spares, especially during the first launch.
- It’s a good idea to minimize the changeover phases since the service is down while switching mastership.
- Before activating the spare system, all modules in the active system have to be deactivated.
Conclusions
ZMQ is a low-level library that provides messaging patterns which, until a few years ago, were very complex to implement and use. Nonetheless, by focusing on the needs of our application, we can interconnect software components efficiently. Nowadays, it’s easier to create a distributed application.