How many of you have had to tackle one of these problems?
“Given a free text field, implement the search for products in a catalog by name or category, first showing the results corresponding to the name and then providing autocomplete suggestions to the user.”
“Implement a search field for articles where you can search by name and tolerate any typing errors.”
“Given a database of products sold, identify the 10 best-selling categories of the current calendar year and return the average price for each.”
If you’re one of them or have faced similar problems, Elasticsearch is the tool for you!
Introduction
Elasticsearch is a distributed search engine used for doing full-text searches and data analysis. For example, Wikipedia uses Elasticsearch to perform instant searches for articles and provide suggestions, while GitHub uses it to search for code, and Stack Overflow uses it for searching and to show related questions.
Technically speaking, Elasticsearch is a software written in Java and based on Apache Lucene, a Java library that efficiently implements full-text search. But Lucene is just a library, and in order to use it, you need to write your application in Java and directly integrate it. Even worse, Lucene is very complex to use, and writing an application that uses it requires a thorough understanding of full-text search theory. Elasticsearch uses Lucene internally, but exposes a simple RESTful API that abstracts its complexity and that can be used directly or through one of the clients written in numerous languages (JavaScript, Python, Ruby, Java, .NET, Perl, etc.).
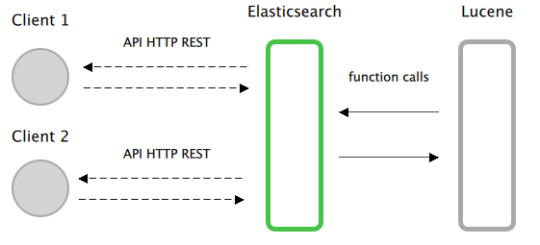
Elasticsearch is also a document-oriented database that uses JSON for data serialization. It can store and search complex documents, and its distributed architecture makes it easy to scale across hundreds of servers, handling petabytes of data with ease.
The structure of a cluster
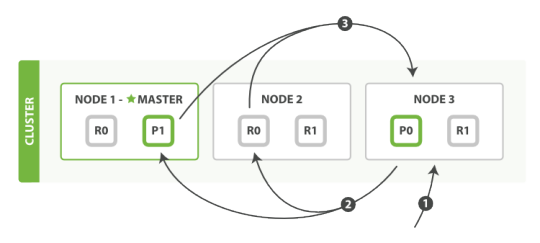
The standard Elasticsearch setup consists of a cluster made up of one or more nodes. Each node runs on a server or virtual machine and represents a single Elasticsearch instance.
A key concept in Elasticsearch is the index, which is a collection of documents grouped by type—similar to a database in relational systems. Each index is divided into one or more shards, and each shard is essentially a separate Lucene instance. Shards come in two types:
- Primary shards, which handle both indexing and search operations.
- Replica shards, which are read-only copies used to increase fault tolerance and search capacity. If needed, a replica shard can be promoted to a primary.
Documents within an index are evenly distributed across all its primary shards.
Elasticsearch automatically manages the allocation of shards across the cluster to optimize performance and resilience. When a client sends a query to any node, that node becomes the coordinator: it routes the request to the appropriate shards – including those on other nodes – gathers the responses, and merges them into a single result, applying any aggregation logic if required.
Elasticsearch’s distributed and flexible architecture allows it to efficiently handle anything from small datasets to millions of documents with ease.
Research
While it’s easy to search for documents in Elasticsearch using a simple query string that supports common operators, the true power of the platform lies in its Query DSL. This structured query language not only allows for precise document retrieval, but also enables fine-tuned control over the scoring algorithm, boosting certain results, applying filters, and defining complex criteria.
Beyond basic search, Elasticsearch also offers advanced features such as result highlighting, aggregations, and intelligent functionalities like “more like this” or “did you mean?” to enhance the search experience.
The first execution
Installing and running Elasticsearch is straightforward. Written in Java, it requires a Java Virtual Machine (JVM)—version 7 or 8, either Oracle or OpenJDK—and runs smoothly on most Linux distributions, as well as on Windows Server and Solaris.
*Once downloaded—either from the official website or via package managers like APT or YUM—you can extract the archive and start Elasticsearch on nix systems with the following command:
$ /bin/elasticsearchand on Windows systems with:
$ /bin/elasticsearch.batand then start experimenting!
$ curl -X GET http://localhost:9200/
{
"status" : 200,
"name" : "Xemu",
"cluster_name" : "elasticsearch",
"version" : {
"number" : "1.7.3",
"build_hash" : "05d4530971ef0ea46d0f4fa6ee64dbc8df659682",
"build_timestamp" : "2015-10-15T09:14:17Z",
"build_snapshot" : false,
"lucene_version" : "4.10.4"
},
"tagline" : "You Know, for Search"
}To find out more:
- definitive guide: https://www.elastic.co/guide/en/elasticsearch/guide/current/index.html
- reference: https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html