Salvare file su disco, cosa può andare male

Una volta che abbiamo salvato un progetto su disco e gestito il versionamento, varie cose possono andare male, in modo più o meno pericoloso per i dati dell’utente.
Modifica ad un argomento con valore di default
Supponiamo di avere il nostro JournalPost, definito alla release 1.0 del programma come:
@dataclass
class JournalPost:
body: strAlla release 2.0 del programma decidiamo di avere sia post pubblici che privati. Inoltre decidiamo che il post di default sia privato.
@dataclass
class JournalPost:
body: str
private: bool = TrueQuando creiamo un nuova istanza, l’argomento private ha un valore di default e può essere omesso. Si può creare un nuovo post con:
post = JournalPost(body="It Could Be Worse; It Could Be Raining")Pensiamo un attimo se è necessario fare un passo di import, ma decidiamo di non farlo, tanto l’istanza si può creare anche senza l’argomento private. I vecchi post resteranno privati grazie al valore di default nel costruttore. Facciamo solo un passo di import come marcatore della modifica al formato:
def import_1(journal):
# Added `private` argument to JournalPost
passÈ normale che durante lo sviluppo vengano fatti più passi di import, cioè più modifiche strutturali alle entità del progetto, tra una release e la successiva. Per semplicità abbiamo detto che la release 1.0 è alla versione
1del formato e che la versione 2.0 è alla versione2, ma potrebbe essere anche alla versione14, le due numerazioni sono indipendenti.
Alla versione 3.0 del progetto, decidiamo che, per qualche ragione, il default dell’attributo private deve cambiare ed essere False.
Qua si aprono due panorami:
- Un progetto creato alla versione
1, aperto e salvato alla versione2(nella serializzazione salviamo tutti gli attributi delle classi, ancheprivate=True), aprendolo nella versione3avrà linee conprivate=True✔️ - Un progetto, creato alla versione
1e aperto direttamente nella versione3, avrà l’attributoprivate=Falseperché l’argomento non viene passato al costruttore e prende il valore attuale del default ❌
Se il linguaggio usato permette dei valori di default, i valori di default delle classi vanno aggiunti al versioning.
Il passo di import scritto in modo più robusto è:
def import_1(journal):
# Added `private=True` argument in JournalPost
for post in journal["posts"]:
post["private"] = TrueAnche se il cambio del default è il caso più grave, i casi più frequenti in cui la mancanza di un attributo è un problema sono i passi successivi di import, che devono fare scelte ispezionando quell’attributo.
Supponiamo nella versione 3.0 di aver cambiato l’implementazione del journal e di aver deciso di mantenere due liste separate, una per i post privati e l’altra per quelli pubblici, andremo quindi a creare le due liste valutando l’attributo private:
def import_5(journal):
for post in journal["posts"]:
if post["private"]:
...Ma se ci siamo dimenticati di aggiungere l’attributo private al passo di versioning, avremo un errore nel cercare di leggere il valore post["private"] e saremo obbligati a scrivere post.get("private", ???), perdendo anche un po’ di tempo a capire quale sia il corretto valore di default nel punto della storia in cui siamo.
Recupero di un progetto corrotto
Supponiamo che per via di un bug, la versione 2.0 del programma potesse salvare dei post con tags=None al posto di tags=[]. Questo problema blocca il caricamento, perché non si riesce proprio a creare una istanza del post senza una lista (anche vuota) di tags.
Ci sono almeno un paio di strategie possibili:
- mettiamo nell’inizializzazione del
JournalPostdel codice speciale per gestire il caso degenere ditags=Nonee lo portiamo nella release 2.1 assieme al fix che risolve il bug che creava i progetti corrotti, - modifichiamo al momento del caricamento il progetto, prima di creare una istanza, mettendo una lista vuota al posto del
None, e rilasciamo una 2.1 con il fix al salvataggio ma nessuna altra modifica nella classeJournalPost.
L’opzione 1) ha vari contro:
- non sappiamo se la lista vuota arriva da un progetto corrotto o da nuovo codice e dobbiamo gestire i due casi allo stesso modo,
magari in un futuro tags=None potrebbe diventare un valore valido.
- per sempre avremo un codice di inizializzazione più complicato per gestire i vari errori di serializzazione, ed il codice si complicherà sempre di più via via che nel tempo si aggiungeranno altri problemi.
Si possono trovare architetture intelligenti per delegare fix di questo genere ad una specifica funzione chiamata prima del caricamento, ma il codice delle classi dovrebbe essere in qualche modo informato di dettagli tipo la versione corrente della serializzazione, dettagli che sono scollegati dai compiti base della classe.
L’opzione 2) invece può funzionare, ma l’idea semplice di modificare il passo di import_1() per correggere il problema non funziona, perché i progetti alla versione v2 non eseguono di nuovo le funzioni di import precedenti. Non ha senso aggiungere la funzione import_2() perché avremmo corretto il bug solo nella versione 3.0 del programma[1].
L’astuto lettore mi chiederà: potremmo però agire in modo combinato? Il caso speciale dovrà essere gestito nelle versioni 2.1+, mentre potremmo aggiungere un passo di import speciale nella versione 3.0, che risolve il problema almeno a partire dalla prossima release. Questo potrebbe essere un buon compromesso ma è anche un ottimo spunto per trovare una soluzione che lascia il codice delle classi invariato.
L’idea che possiamo esplorare è quella di introdurre un ugly-fix, cioè una funzione pensata per essere eseguita a una particolare versione della serializzazione, sia nel caso che il progetto sia stato importato che nel caso in cui il progetto si trovi già a quella versione:
def ugly_fix_2(journal):
for post in journal["posts"]:
if post["tags"] is None:
post["tags"] = []Questo codice viene eseguito tutte le volte che il progetto si trova alla versione 2, dopo gli eventuali passi di import.
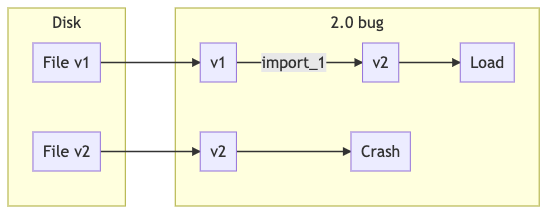
La release 2.0, senza passi di fix, continua a (cercare di) aprire i file in questo modo (ma poi restituisce un errore nel caricare il post corrotto):
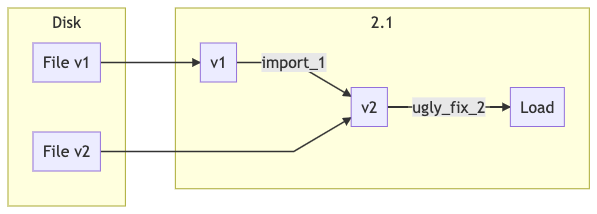
Nella release 2.1 introduciamo il fix nel codice per non serializzare più i post corrotti e l’ugly-fix per recuperare i progetti salvati con la release 2.0.
Nella release 3.0 continuiamo ad eseguire il fix, ma solo per le versione potenzialmente corrotte, mentre non lo eseguiamo per la release corrente, dato che il problema è già stato risolto nel codice (non esistono progetti con questo tipo di problema alla versione 3).
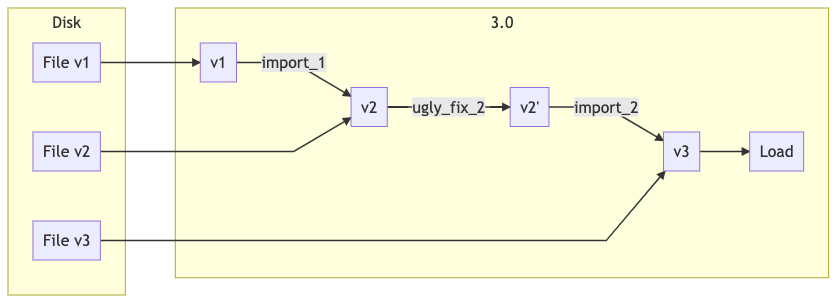
In questo modo possiamo portare nella vecchia versione le nuove funzioni di ugly-fix e correggere il bug dei progetti salvati male in una release 2.1, che continua a salvare progetti alla versione 2 ma senza bug.
In questi casi purtroppo il fix viene eseguito anche su progetti sani, quindi è importante che la funzione di fix non faccia niente se il progetto è già corretto. La prima applicazione della funzione ugly_fix_N() può cambiare qualcosa, ma la seconda applicazione non deve cambiare niente, altrimenti è un bug.
Sarebbe possibile introdurre una diversa numerazione delle versioni, e assumere che la versione
2_0e2_1possano essere compatibili al 100% ma le versioni successive possano aver risolto alcuni bug. Non ho esperienza con questo approccio, ma in teoria permetterebbe di eseguire gli ugly-fix solo se necessario.
Sarebbe anche possibile introdurre una versione iniziale per decidere di non applicare il fix ai progetti salvati alla versione1, dato che il bug si poteva manifestare solo nella release 2.0.
Gli ugly-fix si applicano anche nel caso in cui l’errore sia in un passo di import. Resta possibile portare in una vecchia release il fix ma non è possibile, senza usare un ugly-fix, correggere i progetti già caricati e salvati alla nuova versione almeno una volta. Questo tipo di errore è subdolo, perché, se siamo riusciti a caricare il progetto dopo averlo corrotto ed anche a salvarlo di nuovo, è veramente difficile che nel file sia ancora presente tutta l’informazione necessaria per recuperare il progetto originale.
Conclusione
Anche in questa epoca dove molto avviene nel cloud, la persistenza locale è sempre una realtà con cui fare i conti.[2]
Riassumendo, le regole da tenere a mente quando si salvano dei file su disco sono quattro:
- i dati persistenti devono avere un campo con la versione
- il formato di serializzazione dei dati deve essere stabile e ricco
- non usare il nome del formato come estensione del file
- i valori di default delle classi/funzioni vanno congelati nel versioning
E le regole sono solo tre se il linguaggio che state usando non ha argomenti con valori di default.
Buon salvataggio!
L’articolo fa parte di una serie di tre articoli:
– Salvare file su disco, ed aprirli di nuovo
–Il versionamento dei file su disco
– Salvare file su disco, cosa può andare male
[1]Per ridurre la variabilità, almeno nel nostro modo di lavorare, la versione 2.x del progetto salverà per sempre solo file alla versione 2. Quindi la prima release che esegue il passo import_2() è la versione 3.0.↩︎
[2]Chi ha lavorato con i database avrà notato le grandi similitudini coi concetti di migrazioni offerti da varie librerie, per citarne una molto completa ed apprezzata, quella delle Migrazioni di Django.↩︎