Salvare file su disco, ed aprirli di nuovo

Photo by Erda Estremera on Unsplash
Perché è un problema?
Perché il “problema” sta nel fatto che l’utente si aspetta di non avere alcun problema. Solo che per offrire questa esperienza lo sviluppatore deve prevedere e gestire la maggior parte di questi problemi potenziali 🎱.
In questa serie di tre articoli cercheremo di rispondere ad alcune domande:
- Persistenza in senso molto vago, salviamo su disco un blob di dati, che sono il dump dello stato del’applicazione. Siamo alla prima release, il codice a runtime è lo stesso che ha salvato i dati. Ma la seconda release? Il codice si è evoluto, mentre il dump è lo stesso. Quindi il dump o il codice vanno adattati per raggiungere la compatibilità. Qua si aprono le due strade: adattiamo i dati del dump al codice nuovo o il codice al dump vecchio?
- Persistenza dei dati, come arriviamo a questo “dump”? Strutture che si sanno serializzare? Serializzazione di alberi o grafi diretti aciclici?
- Come far aprire file salvati con versioni diverse dell’applicazione? Ci sono un po’ di buone pratiche, perché è facile tirarsi la zappa sui piedi. Sono problemi che ci si pongono in un software che ha più di 10 anni di vita e garantisce un supporto per le vecchie release di 2-3 anni, non capita all’app media per telefono.
- Cosa può andare male quando salviamo? È importante chiarire il contesto: stiamo progettando un software professionale in cui l’utente investe ore ed ore del suo tempo per realizzare qualcosa, e perdere un salvataggio è un danno economico. Quindi anche a livello di architettura del sistema di salvataggio si fanno dei passi per rendere “normale” anche la gestione dell’improbabile, perché a tendere, di release in release, si manifesterà: aver salvato dei dati corrotti per via di un bug nel programma.
In particolare vedremo come creare un formato di file duraturo per la nostra applicazione, e nello stesso tempo mantenere il codice pulito, senza strani if per gestire le inevitabili modifiche del formato avvenute durante l’evoluzione del software.
Vedremo in dettaglio:
- come salvare dei dati (strutture in memoria del nostro programma) su un file,
- come gestire le evoluzioni delle strutture del programma e i file salvati su disco a versioni diverse,
- come recuperare dei file che sono stati corrotti da un bug nel programma.
E come questo ci porti a alle 3 regole d’oro della persistenza dei dati:
- i dati persistenti devono avere un campo con la versione,
- il formato di serializzazione dei dati deve essere stabile e ricco,
- non usare il nome del formato come estensione del file.
Persistenza dei dati
Quasi ogni applicazione ha la necessità di far persistere dei dati tra un’esecuzione e la successiva. Sia che l’app sia una classica applicazione desktop che una più moderna applicazione web, se permettiamo all’utente di salvare un file su disco è probabile che si aspetti di poter eseguire anche l’operazione inversa: caricare nuovamente quel file all’interno della nostra applicazione.
Ci sono almeno due tipi di persistenza molto diffusi:
- persistenza delle impostazioni dell’utente
- persistenza dei progetti/documenti creati con l’applicazione
Il primo caso è solitamente più semplice da gestire, perché spesso delegabile a librerie già esistenti [1]. Il secondo caso è generalmente più complicato, e prendere il problema alla leggera potrebbe esser ragione di grattacapi in futuro.
Per capire meglio le problematiche legate alla persistenza, considereremo l’evoluzione nel tempo di un’ipotetica applicazione.
Supponiamo che la nostra applicazione sia un diario, avremo delle entità che sono i post del nostro diario, che per semplicità espositiva hanno per ora solo il corpo del messaggio. Per giustificare le nostre attenzioni alla qualità, immaginiamo che il nostro diario sia usato da J. K. Rowling e da George R. R. Martin, non possiamo fare brutta figura!
Usando uno pseudocodice – ovvero, non testato – simile a Python, possiamo immaginare che la struttura di un post sia:
@dataclass
class JournalPost:
body: strNon abbiamo aggiunto un
pid, un indice per poter far riferimento ad un particolare post. In realtà potrebbe essere utile, ma ai fini di questa esposizione non è importante.
I dettagli di come procedere nella serializzazione dipendono molto dal linguaggio usato, però ci possiamo focalizzare sul risultato.
In generale in memoria avremo una sorta di radice, un punto base per accedere alle varie entità. Nel caso dei post potremmo avere un Journal con una struttura del tipo:
@dataclass
class Journal:
name: str
posts: List[Journalpost]Che poi mostreremo ordinati per data o per tag, ma sono tutte feature ancora da implementare 😀.
Data questa struttura gerarchica possiamo immaginare di serializzare il nostro Journal partendo dalla radice e chiamare ricorsivamente sui nodi dell’albero una funzione di serializzazione.
I Post sono foglie e possono essere serializzati senza particolari attenzioni:
@dataclass
class JournalPost:
body: str
def dump(self):
"Convert the instances to the intermediate format"
return {"body": self.body}
@classmethod
def load(cls, post_data):
"Create the instances from the intermediate format"
return cls(**post_data)Invece il Journal fa riferimento a dei post. In questo caso il grafo [2] è proprio un albero, e possiamo evitare la complicazione di serializzare i riferimenti tra entità e serializzare i nodi figli direttamente come contenuti nel nodo padre.
@dataclass
class Journal:
name: str
posts: List[JournalPost]
def dump(self):
"Convert the instances to the intermediate format"
return {"name": self.name,
"posts": [post.dump() for post in self.posts]}
@classmethod
def load(cls, journal_data):
"Create the instances from the intermediate format"
posts = [JournalPost.load(**post_data) for post_data
in journal_data.pop("posts")]
return cls(**journal_data, posts=posts)Ovviamente questo codice è molto semplificato, nei casi reali si cercano delle convenzioni per recuperare il nome delle classi e per fare ricorsione sui vari attributi usando l’introspezione, ma il concetto non cambia.
Alla fine della serializzazione, avremo le nostre strutture rappresentate in un formato diverso (magari JSON o XML) che potremo salvare in un file che conterrà come minimo le informazioni necessarie per poter fare il processo inverso, e tornare dal formato intermedio alle istanze.
Nel nostro esempio di post, ci possiamo immaginare una trasformazione di questo tipo:
{
"journal": {
"name": "Learning diary",
"posts": [{"body": "Today was a day"}]
}
}Abbiamo scritto del codice per passare da una struttura arbitraria in memoria ad un formato costituito da tipi nativi più semplice: liste, stringhe, mappe. La complessità dei tipi usabili dipende dal formato di serializzazione finale. Per fare un esempio, in JSON le mappe non sono ordinate, altri formati potrebbero offrire mappe ordinate, il formato intermedio va un po’ studiato caso per caso, ma il flusso resta lo stesso:
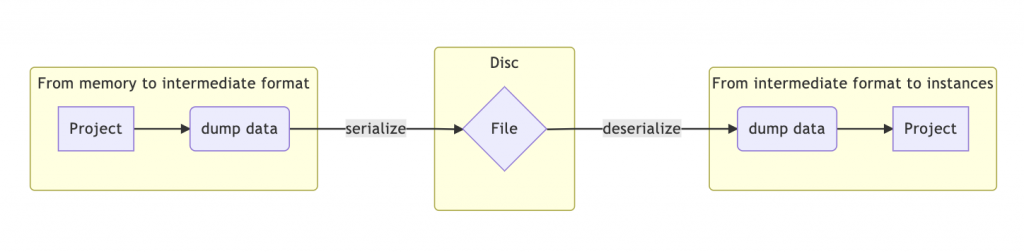
Ma ora che abbiamo salvato qualcosa su disco, abbiamo creato un punto fisso nella storia che non potremo più modificare. Gli utenti contano di poter aprire il diario anche con le nuove versioni del programma. Nel prossimo articolo della serie parleremo proprio di “Versionamento dei file su disco“. A presto!
L’articolo fa parte di una serie di tre articoli:
– Salvare file su disco, ed aprirli di nuovo
–Il versionamento dei file su disco
– Salvare file su disco, cosa può andare male
[1] Ad esempio nell’ecosistema Qt i QSettings astraggono il problema delle impostazioni offrendo un’interfaccia unificata alle librerie presenti sulle varie piattaforme. ↩︎
[2]Se non fosse un albero? In questo caso, cioè nel caso generico in cui le relazioni tra entità non formano un albero ma un grafo, serializzando in modo ricorsivo, ci troveremmo ad espandere una stessa entità più volte. In questi casi solitamente si usano degli ID univoci per serializzare i riferimenti tra entità, e tutte le entità vengono serializzate in una unica lista. Perché questo funzioni è importante che il grafo delle entità sia un grafo diretto aciclico, in modo da poter trovare un ordinamento topologico:
Wikipedia In teoria dei grafi un ordinamento topologico (in inglese topological sort) è un ordinamento lineare di tutti i vertici di un grafo aciclico diretto (DAG, directed acyclic graph). I nodi di un grafo si definiscono ordinati topologicamente se i nodi sono disposti in modo tale che ogni nodo viene prima di tutti i nodi collegati ai suoi archi uscenti <…> . È possibile ordinare topologicamente un grafo se e solo se non ha circuiti (cioè solo se è un grafo aciclico diretto), e sono noti algoritmi per determinare un ordinamento topologico in tempo lineare.
Questo ordinamento garantisce che sia possibile serializzare prima le entità base e poi le entità che hanno un riferimento alle prime. Nel caso del nostro esempio, prima tutti i post e poi il journal. Deserializzando nello stesso ordine, potremo creare tutte le istanze di JournalPost e poi passarle al costruttore di Journal, deserializzato per ultimo. ↩︎