Il versionamento dei file su disco

Proseguendo il tema iniziato con l’articolo “Salvare file su disco, ed aprirli di nuovo”, vediamo come caricare progetti salvati su file da versioni diverse di un’applicazione (liberamente tratto dal vero sistema di versionamento di un cad nel settore della moda)
Cosa si intende per versionamento o versioning?
- Per versioning si intende la possibilità, per un programma che salva dei progetti in file su disco, di aprire i vecchi salvataggi dopo un aggiornamento. Ma anche, al contrario, di permettere alle vecchie versioni del programma di aprire file salvati con una versione più recente.
Per semplicità di esposizione, assumerò via via alcune scelte di design. La prima è: tutti i software della versione 1.x salveranno file alla versione 1
Questo perché vogliamo che tutte le versioni 1.x siano compatibili tra loro. Evitando quindi di modificare le strutture del programma, per esempio, tra la versione 1.0 e la versione 1.1.
Discorso simile vale per il formato dei file su disco: all’interno delle release 1.x potremo introdurre bugfix, migliorie grafiche, ma la struttura dei dati deve restare la stessa, per permettere lo scambio dei file tra 1.x diverse.
Con la versione 2.0 invece il nostro diario si evolve: vogliamo introdurre il supporto per i tag.
La nuova versione può già uscire col supporto per i vecchi progetti, il formato 1 è ormai fissato, possiamo scrivere del codice che converta le vecchie strutture nelle strutture attuali.
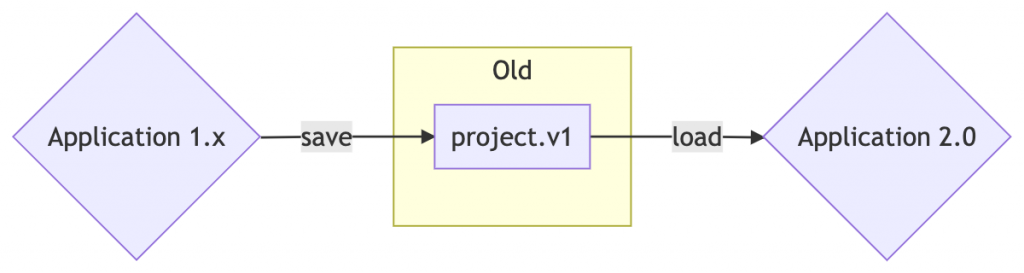
Il problema un po’ più complesso sta nel permettere l’operazione inversa: abbiamo un’applicazione che viene rilasciata con delle release periodiche, ogni versione è mantenuta per un certo tempo. Fino a quando una release è mantenuta viene garantita la possibilità di aprire i file salvati con release successive.
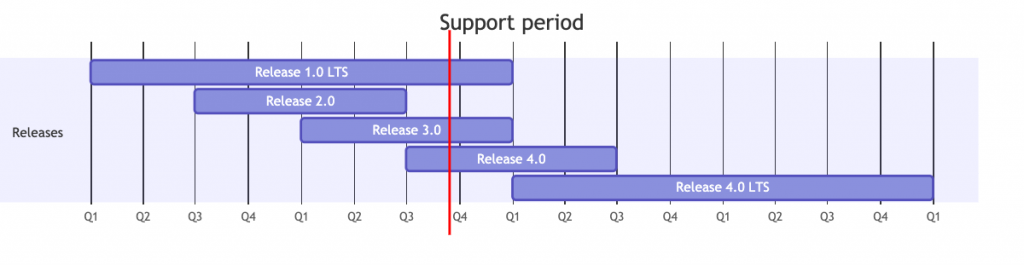
Mentre le nuove release escono già col supporto per i vecchi formati, nel caso delle vecchie release sarà necessario un aggiornamento per abilitare il supporto ai nuovi progetti. Perché, se le feature della release 2.0 fossero già state pronte o prevedibili 🔮, l’avremmo già rilasciate nella 1.0.
Possiamo supporre di dover rilasciare una 1.1 che verrà pubblicata più o meno in concomitanza con la versione 2.0, e questo aggiornamento alla release 1.x non aggiunge nessuna altra caratteristica se non permettere l’apertura dei nuovi progetti:
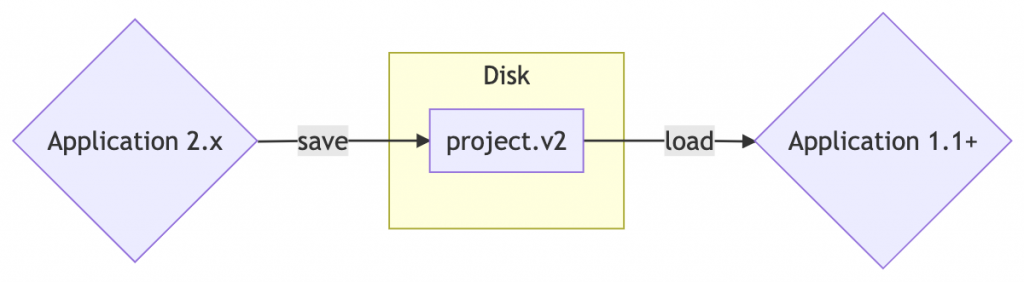
Questo è l’obiettivo a cui vogliamo arrivare, ma vediamo quali sono le problematiche che emergono nel salvare dati strutturati in modo persistente su disco e quali buone pratiche possiamo mettere in atto.
Compatibilità tra versioni
Se partiamo affrontando il problema senza riflettere su diverse scale temporali, potremmo pensare di gestire i diversi formati direttamente nel costruttore delle nostre entità. Ad esempio cosa possiamo fare se abbiamo aggiunto una lista di tag come attributo del post?
- potremmo aggiungere l’argomento opzionale nelle nuove versioni, con una lista vuota come valore di fallback,
- potremmo aggiungere l’argomento anche nelle vecchie versioni, scartandolo.
Questo approccio ha però vari problemi, in particolare se pensiamo alle evoluzioni nel tempo, tra una settimana, tra un mese, tra un anno:
- le modifiche sono diffuse in tutto il codice:
- sia nella nuova release,
- sia nelle vecchie release ancora supportate,
- se le vecchie release sono più di una, aggiungere l’argomento in più è una modifica non automatica, perché ogni release diverge sempre più dal codice del branch di sviluppo attuale.
Per evitare questi problemi è nostro interesse separare il supporto delle versioni dal codice principale dell’applicazione, in modo che la classe JournalPost possa lavorare sempre con i dati alla versione corrente.
Prima di poter creare le nuove istanze, abbiamo bisogno di adattare i dati dal vecchio formato intermedio al nuovo formato intermedio, in modo che abbiano la struttura necessaria per poter creare le istanze. Oltre a questo, dobbiamo porci alcune domande:
- quando andremo ad accedere nuovamente ai dati, in che formato saranno?
- se non fossero del formato giusto, come possiamo convertirli?
Da questi primi dubbi emerge la prima regola fondamentale della persistenza dei dati:
Regola 1: i dati persistenti devono avere un campo con la versione
Che sia una intestazione, un campo {version: "1", ...}, l’importante è che sia una cosa che potremo tenere ferma pur evolvendo il resto del formato. Senza una versione saremmo obbligati a fare strani if sulla struttura per cercare di indovinare la versione di partenza. Meglio scriverla, no?
Regola 2: scegliere un formato dei dati stabile e ricco
Scegliere un formato di serializzazione pre-esistente ci semplifica il lavoro, ma non è necessario. È solo una comodità che ci permette di delegare il problema della serializzazione ad una diversa parte del codice.
Se decidiamo di accoppiare la trasformazione delle strutture nel formato intermedio alla sua serializzazione, di fatto stiamo introducendo due possibili cambiamenti:
- il formato dei dati su disco può cambiare di versione in versione,
- l’interpretazione dai dati caricati dal disco può cambiare di versione in versione.
Scegliere una libreria (privata o pubblicamente disponibile) per la serializzazione riduce la complessità del problema suddividendo le reponsabilità.
- La libreria di serializzazione dovrà esclusivamente occuparsi di trasformare i bytes in strutture dati in memoria e viceversa.
- La nostra applicazione dovrà occuparsi esclusivamente di trasformare il formato intermedio dalla vecchia alla nuova versione.
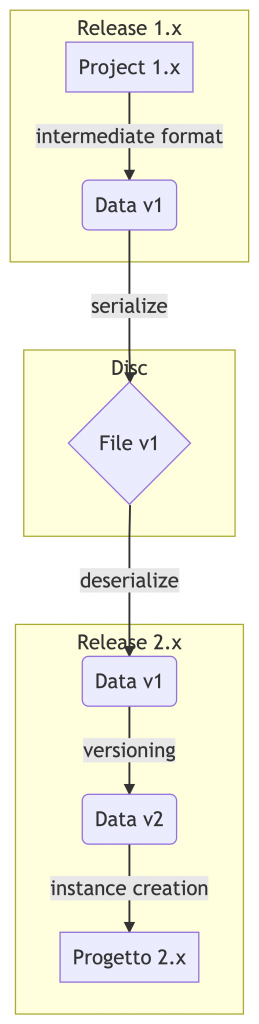
Riassumendo, il processo di salvataggio e caricamento ha questo flusso:
- i dati in memoria vengono trasformati in un formato intermedio alla versione
1, - i dati intermedi vengono serializzati su disco,
- in modo simmetrico i dati dal disco vengono deserializzati dal programma alla release 2.x,
- una volta ottenuto il formato intermedio alla versione
1(così lo avevamo salvato), i dati vengono trasformati e portati alla versione2, - a questo punto è possibile creare le nuove istanze.
Ma quali sono le caratteristiche di un buon formato di serializzazione per il versioning?
In generale la caratteristica principale è che il formato sia ispezionabile e modificabile, così da poter accedere alle parti senza dover scrivere un parser.
Se il nostro formato può rappresentare liste e dizionari/mappe, possiamo caricarlo nelle strutture dati analoghe nel nostro linguaggio e trasformarlo, cambiando la struttura o i valori come necessario.
Nel caso (complesso) di voler permettere ai vecchi software di aprire i nuovi progetti, se il formato di serializzazione cambia così tanto da richiedere una nuova versione della libreria di serializzazione, è importante ricordare che anche questa andrà aggiornata nelle vecchie release.
Avete scelto JSON per salvare il progetto? C’è una trappola da evitare: non usate il nome del formato come estensione. Il collegamento tra il formato dei file e l’estesione è un dettaglio privato dell’applicazione. Magari vogliamo comprimere il file, magari cambiare formato senza confondere l’utente. Tutte cose possibili con un po’ di attenzione, anche mantenendo fissa l’estensione, ma difficili da fare se l’estensione diventa palesemente errata.
Esempio di versioning
Supponiamo che alla versione 1.0 il nostro programma salvi una struttura JournalPost definita come:
@dataclass
class JournalPost:
body: str
category: strNella versione 2.0 decidiamo di voler assegnare dei tag ad ogni articolo al posto di una singola categoria – sempre semplici stringhe – e quindi la struttura diventa qualcosa del tipo:
@dataclass
class JournalPost:
body: str
tags: List[str]Abbiamo visto che ci sono almeno due modi per aprire il vecchio formato:
- ogni classe[1] avrà un codice speciale dedicato al caricamento delle vecchie versioni,
- il codice di ogni classe supporta solo il caricamento della versione corrente, mentre un altro modulo si occupa di trasformare i dati dal vecchio formato al nuovo.
Anche se la prima opzione sul breve termine potrebbe sembrare la più semplice, pensando un po’ in prospettiva emergono subito degli aspetti negativi:
- ogni volta che si cambia il formato, vanno aggiornate tutte le classi che si serializzano in modo diverso,
- il bagaglio cognitivo necessario a modificare ogni classe cresce via via che le modifiche si stratificano,
- modifiche relative ad una stessa release sono diffuse in più di un file,
- portare in vecchie release le modifiche fatte su tanti file aumenta la probabilità di conflitti nella gestione del codice.
OK, l’avevo già detto, ma è importante 😼 e lo ripeto.
Per ovviare a questi problemi, conviene creare un minimo di infrastruttura per delegare ad una parte specifica del codice il compito di trasformare i dati, lasciando più semplice tutto il resto del programma.
Import (aprire progetti più vecchi)
Supponiamo di serializzare la classe in formato JSON, la versione 1.0 sarà qualcosa del genere:
{
"version": 1,
"journal": {
"name": "Learning diary",
"posts": [{"body": "Today was a day",
"category": "home"}]
}
}Per semplicità espositiva, supponiamo che dopo il caricamento, i dati vengano caricati un una struttura journal che è proprio la trasposizione in tipi nativi Python a partire dai dati del JSON.
Al momento del caricamento nella release 2.0 dovremo implementare una funzione del tipo:
def import_1(journal):
"""
The versioning library will call the function
`import_1()` with `journal` at version `1` and
will modify `journal` to be at version `2`.
"""
for post in journal["posts"]:
# Create the new argument with the old category value
post["tags"] = [post["category"]]
# Remove the old argument
del post["category"]Regress (aprire progetti più nuovi)
Se invece vogliamo fare il contrario, aprire un progetto alla versione 2 con il programma alla release 1.1, il procedimento è simile:
Normalmente la release 1.0 l’avremo distribuita prima di rilasciare la 2.0, il supporto per i progetti delle nuove release arriverà in una release di supporto.
def regress_2(journal) -> bool:
"""
The `regress_2()` function will convert the
`journal` from version `2` to version `1`.
The returned value is `True` if the old format
supported all the information stored in the new
one, and `False` otherwise,
"""
lossless = True
for post in journal["posts"]:
# we cannot backport more than one tag
if len(post["tags"]) > 1:
lossless = False
# We arbitrarily choose to save the first tag as a category,
# or use 'home' as fallback if there are no tags
tags = post["tags"]
post["category"] = tags[0] if tags else "home"
del post["tags"]
return losslessIn questo caso, dobbiamo restituire un’informazione importante per l’utente: nell’aprire il nuovo progetto alcune delle informazioni presenti nel nuovo formato sono andate perse?
Nel nostro esempio eventuali tag multipli sono persi. Notifichiamo la perdita di informazioni solo se ci sono tag multipli nel progetto.
Volendo, invece di restituire un flag booleano, potremmo restituire una lista di messaggi più dettagliati, o anche lasciare l’utente ignaro, ma un booleano potrebbe essere una giusta via di mezzo.
A questo punto cosa può andare male? Varie cose, che vedremo nel terzo e ultimo articolo di questa serie “Cosa può andare male?”
L’articolo fa parte di una serie di tre articoli:
– Salvare file su disco, ed aprirli di nuovo
–Il versionamento dei file su disco
– Salvare file su disco, cosa può andare male
[1]Per semplicità ragioniamo con la terminologia di classi, ma la logica è applicabile anche ad altri paradigmi di programmazione. ↩︎