Garantire l’affidabilità di un sistema Linux embedded
Introduzione
Nell’ultimo decennio, la diffusione di Linux nel mondo industriale ha subito una costante crescita, incentivata dalla famosa legge di Moore: processori sempre più performanti sono disponibili sul mercato a prezzi sempre più competitivi.
La nascita di sistemi di build quali Buildroot e Yocto, che permettono di creare un sistema Linux embedded completo in pochi click, ha ulteriormente stimolato tale processo. Al giorno d’oggi, praticamente ogni produttore di processori e microcontrollori destinati all’utilizzo embedded fornisce qualche forma di supporto per l’integrazione dei propri prodotti con Linux.
Nei prossimi paragrafi, analizzeremo una problematica particolarmente rilevante per i sistemi che lavorano in questo contesto: l’implementazione di meccanismi che consentano ad un sistema che opera sul campo di continuare a funzionare in (quasi) ogni situazione.
Le criticità di un sistema sul campo
Una delle proprietà maggiormente desiderabili per un sistema industriale è l’affidabilità, ossia la capacità del sistema di garantire, nel tempo, le proprie condizioni di funzionamento, specialmente in risposta ad eventi straordinari quali guasti, anomalie o errori umani.
Diversi sono infatti i problemi che possono verificarsi durante il tempo di vita di un sistema che possono interferirne col normale funzionamento, alcuni addirittura legati intrinsecamente all’infrastruttura e all’organizzazione del sistema stesso, ed inevitabili se si desiderano funzionalità particolari. Per citare alcuni esempi comuni:
- problematiche hardware legate a difetti di progettazione, deterioramento o malfunzionamento di componenti, corruzione degli elementi di memoria etc.
- errori software che minano la stabilità del sistema (bug, configurazioni errate etc.)
- eventi imprevisti e non tollerati (spegnimenti improvvisi dovuti a perdita di alimentazione, errore umano etc.)
Un classico esempio riguarda lo studio dei problemi derivanti dall’implementazione di un sistema di aggiornamento, o parte di esso. Si tratta infatti di una funzionalità raramente trascurabile, e spesso necessaria per diverse ragioni:
- risoluzione di bug che emergono durante il normale funzionamento del sistema
- scoperta di vulnerabilità critiche introdotte da terze parti
- aggiunta di funzionalità non previste in fase di definizione del sistema
L’implementazione di un sistema di aggiornamento si porta dietro però una serie di problematiche che, se non affrontate, possono successivamente causare costi di manutenzione non previsti e spesso importanti.
Un aggiornamento fallito può infatti lasciare il sistema in uno stato inconsistente che ne impedisce il funzionamento, o può causare comportamenti inaspettati e, nei peggiori casi, pericolosi; In altri casi un aggiornamento, pur terminando correttamente, può introdurre dei problemi imprevisti che non possono essere corretti perché non è stato previsto un meccanismo di fallback per queste evenienze.
In entrambi questi scenari, l’unica soluzione possibile prevede l’intervento di un operatore che deve ripristinare manualmente il sistema ad uno stato valido, o addirittura al suo stato originale. Non sempre questa operazione è attuabile sul campo, e spesso richiede di riportare l’apparecchio in assistenza, procedura che in particolari casi può risultare costosa in termini di tempo e denaro (basti pensare al classico caso in cui l’apparecchio malfunzionante fa parte di un sistema meccanico più ampio).
La presenza di meccanismi che permettano di prevenire questi problemi o comunque di riportare il sistema in uno stato consistente si dimostra quindi spesso una necessità, ed esistono diverse tecniche a riguardo.
Sistemi read-only
Tipicamente il primo step nell’implementazione di un sistema Linux affidabile consiste nel configurare le partizioni di sistema in modalità read-only.
Questo accorgimento, seppur molto semplice da realizzare, fornisce un primo meccanismo di protezione abbastanza efficace contro eventi comuni quali spegnimenti improvvisi e corruzione dovuta a bug del software.
In questa configurazione, è in genere prevista una partizione scrivibile in cui vengono salvati i dati dell’applicativo e tutte quelle parti del sistema che è necessario modificare a runtime.
Data la sua cost-effectiveness, questa tecnica è spesso usata in congiunzione con le altre che verranno esposte di seguito.
Sistemi a partizioni multiple
L’introduzione di copie ridondanti del sistema su uno stesso storage è una tecnica comune e spesso semplice da implementare, che previene principalmente le problematiche legate alla corruzione della partizione di sistema o del suo contenuto.
E’ particolarmente utile nei casi in cui:
- il sistema viene tipicamente spento togliendo alimentazione alla scheda elettronica
- è presente un meccanismo di aggiornamento che operi sulla partizione di sistema
- il sistema sia dislocato in posizioni difficili da raggiungere e quindi un intervento manuale sia particolarmente complicato
Tale meccanismo presenta numerosi vantaggi:
- costi di implementazione molto bassi (non è richiesto hardware aggiuntivo)
- non necessita lo sviluppo di componenti software ad-hoc (salvo una minima parte di gestione delle partizioni)
- non ha costi di manutenzione
Questa tecnica è in genere implementata a livello di bootloader di secondo livello (tipicamente U-Boot o Barebox per sistemi Linux basati su ARM), che forniscono funzionalità per la manipolazione e l’accesso ai filesystem.
L’idea di base consiste nel suddividere lo storage usato per il sistema (in genere una memoria flash o eMMC, ma lo stesso discorso si applica a qualsiasi tipo di dispositivo bootabile) in due partizioni.
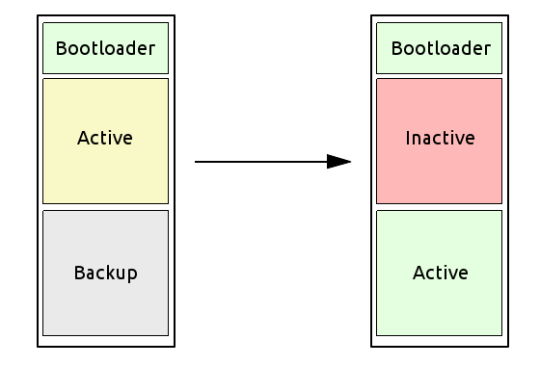
Una prima partizione contiene il filesystem marcato come attivo, ossia quello dal quale verrà effettuato il boot successivo. Si dà per assodato che il filesystem attivo sia in uno stato consistente (come fare a garantire ciò verrà presentato successivamente).
La seconda partizione contiene il filesystem di backup, anch’esso consistente, che viene utilizzato come fallback nel caso in cui un evento distruttivo di qualche genere si verifichi sul filesystem attivo.
L’immagine illustra lo schema di partizionamento classico usato in questi casi.
Ad ogni avvio, il bootloader controlla lo stato della partizione attiva: se il check va a buon fine, la partizione è considerata valida. In caso contrario, la partizione viene marcata come non valida, e la partizione di backup viene marcata come attiva.
Questo semplice meccanismo permette quindi di tollerare almeno un errore verificatosi durante il normale funzionamento del sistema, fornendo la possibilità di rilevarne la presenza e risolverlo, se possibile, al prossimo avvio (ad esempio ripristinando il filesystem da remoto).
Svariate tecniche possono essere utilizzate per effettuare il controllo dello stato della partizione:
- un file di stato in una posizione nota del filesystem, che includa informazioni sull’ultimo stato noto del sistema (startup, boot completato, spegnimento completato, riavvio)
- una variabile di stato nell’environment del bootloader (se accessibile anche da Linux)
- una piccola partizione dedicata
- una piccola memoria esterna (ad es. una EEPROM)
Questa tecnica ha ovviamente delle limitazioni da tenere in considerazione:
- non è resiliente a problemi hardware dello storage utilizzato (single point of failure)
- nella sua forma più semplice, non fornisce nessuna funzionalità di recovery, prevenendo un unico evento di guasto
- dimezza a tutti gli effetti la disponibilità di spazio per il sistema
Sistemi con storage multipli
Un step successivo rispetto a quanto visto finora consiste nello spostare il backup del sistema fuori dallo storage contenente la partizione principale, in una memoria dedicata.
Questa soluzione risolve due dei problemi esposti sopra: lo spazio disponibile su disco non è più limitato dalla presenza di una partizione “inutilizzata” ed è invece completamente sfruttabile, e viene inoltre eliminato il single point of failure, in quanto questa soluzione richiede che entrambe le memorie falliscano, affinché il sistema diventi inutilizzabile.
Esistono fondamentalmente due approcci a questa soluzione, che differiscono per il tipo di storage utilizzato e la funzionalità che forniscono.
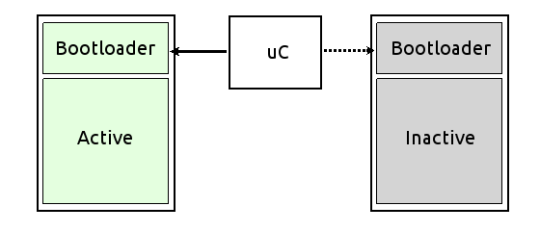
Nel primo approccio, la memoria di backup contiene una copia esatta del sistema presente nella prima. In questo caso, tipicamente le memorie sono dello stesso tipo, e il bootloader seleziona l’una o l’altra al momento del boot, in maniera molto simile a quanto visto precedentemente.
Nel secondo approccio, invece, la memoria di backup è generalmente utilizzata solo come contenitore per un’immagine di sistema minimale, generalmente compressa, che viene caricata ed eseguita da RAM. Sarà poi compito di questo sistema ripristinare la partizione principale, scaricando ad esempio una copia del sistema da un server remoto. In questo caso, la memoria di backup è generalmente molto più piccola e utilizza un bus di comunicazione “lento” (in genere SPI).
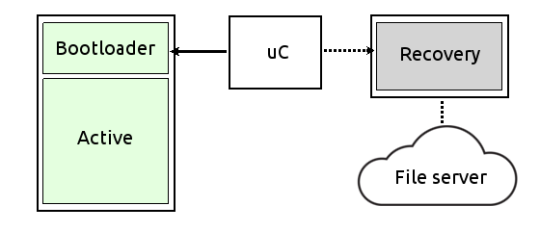
Entrambi gli approcci presentano pro e contro: il primo richiede un maggiore lavoro sulla parte hardware, che risulterà essere anche più costosa; il secondo permette di risparmiare sull’hardware, spostando però la complessità sul software e sulla manutenzione di un’infrastruttura di recovery.
Nel complesso questa soluzione, seppur più robusta di un semplice sistema a doppia partizione, non è esente da svantaggi:
- costi più elevati, in termini di hardware o infrastruttura di recovery
- complessità maggiore nella gestione delle partizioni e del boot
- supporto necessario per (potenzialmente) diverse tecnologie di storage
Cerchi un corso su Linux Embedded?
Scopri i nostri corsi per aziende
Sistemi con recovery da remoto
Si tratta di una versione rivista del secondo approccio visto sopra. In questa configurazione il restore della partizione principale, che era prima affidato ad un sistema di recovery caricato da una piccola memoria ad-hoc, è invece effettuato dal bootloader stesso. La copia del sistema viene ancora recuperata da un server remoto, ma il processo di formattazione della partizione principale e scompattamento dell’immagine viene gestito interamente dal bootloader.
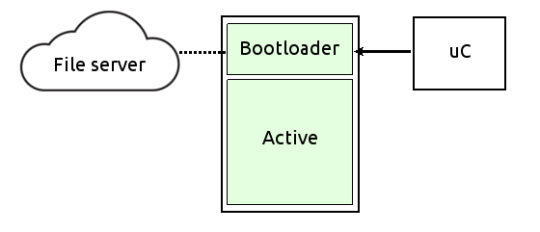
Questa soluzione è notevolmente più conveniente della precedente dal punto di vista hardware, in quanto ne riduce ulteriormente la complessità, ma richiede che il bootloader utilizzato implementi un set di feature più o meno ricco a seconda dell’infrastruttura utilizzata:
- supporto per l’hardware di rete utilizzato
- uno stack di rete TCP/IP completo
- supporto per il protocollo applicativo utilizzato per effettuare il download dell’immagine (HTTP, FTP etc.) ed eventuali metodi di autenticazione (SSL, HTTP Basic Auth etc.)
- software di decompressione e decodifica dell’immagine scaricata
Conclusione
Come appena visto, esistono diverse tecniche per massimizzare l’affidabilità di un sistema, ciascuna delle quali coi suoi pro e contro. La lista qui presentata non è affatto esaustiva, ed è comunque sempre necessario valutare la soluzione migliore sulla base da una lato di esigenze e vincoli hardware e software, dall’altro delle funzionalità desiderate e del grado di tolleranza richiesto dal sistema.