La “concorrenza” (Concurrency) in Go
Che si ami o che si odii, Go è un linguaggio che farà parlare di sé per molti anni a venire. Una delle tante ragioni del suo iniziale successo risiede negli strumenti che il linguaggio fornisce per quanto riguarda parallelismo e concurrency. Vale la pena dare un rapido sguardo alle tre funzionalità fondamentali per capire il modello di concurrency del Go: goroutine, channel e il costrutto select.
Programmi seriali in un mondo parallelo
Scrivere software significa risolvere problemi. Spesso significa farlo ponendo un’istruzione dopo l’altra, in modo seriale, un concetto alla volta. La maggior parte del codice che scriviamo di solito segue questa proprietà.
Il problema è che il mondo non è seriale. La realtà è intrinsecamente parallela. Molteplici eventi accadono in contemporanea, con effetti che interferiscono gli uni gli altri. Più che una linea sequenziale di azioni, la realtà è una rete caotica di situazioni parallele. Se vogliamo risolvere problemi reali dobbiamo necessariamente venire a patti con tutto questo.
Vari strumenti sono stati studiati nel corso degli anni per gestire il parallelismo: thread, mutex, task, coroutine, etc… Tuttavia il Go affronta un dato di fatto e lo pone al centro del proprio design, e nel farlo cerca di usare strumenti più moderni.
L’applicazione più usata oggi non è più un programma lanciato da un utente, su un computer, funzionante su una CPU. Le applicazioni di più largo utilizzo oggi sono webapp.
Cioè stiamo parlando di applicazioni intrinsecamente parallele, che operano dati di milioni di utenti, distribuite su molteplici server, con molteplici servizi forniti da molteplici macchine collocate in varie parti del mondo. Inoltre la CPU standard oggi è sicuramente una CPU multicore. Questo cambiamento radicale merita un ripensamento importante a livello di strumenti di linguaggio. La concurrency diventa un elemento essenziale.
Concurrency non è parallelismo
Sembrerà una domanda banale, ma citando parallelismo e concurrency di cosa stiamo effettivamente parlando?
La concurrency è una prospettiva di design. È la composizione di cose (spesso funzioni) eseguibili in modo indipendente tra loro. Quando parliamo di concurrency stiamo solitamente parlando di come progettare la struttura del codice per gestire esecuzioni simultanee e concorrenti.
Parallelismo è invece l’atto di eseguire effettivamente funzioni in modo simultaneo. Questo dipende spesso da caratteristiche dell’hardware (singlecore vs multicore) e del sistema operativo, caratteristiche spesso sconosciute al momento della scrittura del codice e dalle quali è buona prassi astrarsi.
La nostra attenzione adesso si rivolge alla concurrency, cioè al design del codice, e andiamo a conoscere le goroutine.
Goroutine
Facciamo qualche esempio. Poniamo di avere tre funzioni che eseguono calcoli cpu-intensive.
package main
func doCalc1() {
// 2 seconds spent here...
}
func doCalc2() {
// 2 seconds spent here...
}
func doCalc3() {
// 2 seconds spent here...
}
func main() {
// ...
// insert long program here...
// ...
doCalc1()
doCalc2()
doCalc3()
// ...
// insert rest of the program here...
// ...
}Chiamare queste funzioni in sequenza è l’approccio più semplice e conosciuto. Chiaramente il risultato sarà aspettare la somma dei tempi di attesa di ogni singola funzione. Nessuna magia qui, è tutto come ci aspetteremmo.
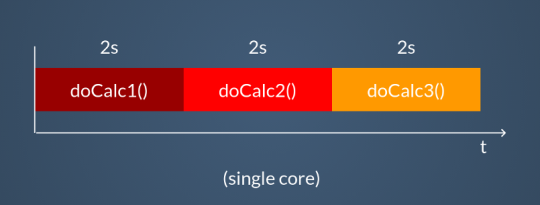
Possiamo fare di meglio. Possiamo trasformare queste funzioni in goroutine semplicemente aggiungendo la keyword go al momento della chiamata.
go doCalc1()
go doCalc2()
go doCalc3()In questo modo stiamo aggiungendo un’informazione; stiamo marcando l’esecuzione di queste tre funzioni affinché avvenga in parallelo. Queste funzioni sono indipendenti tra loro e possono essere eseguite contemporaneamente.
Notate bene: è una scelta di “alto livello”.
Il risultato è che le funzioni non saranno più lanciate in modo sincrono, ma verranno gestite dallo scheduler del runtime di Go. Possiamo vedere le goroutine come micro-thread. In definitiva sono:
- eseguite in modo indipendente
- lightweight micro-thread
- veloci
- basso overhead
- stack efficiente
A differenza dei thread le goroutine sono leggerissime, praticamente a zero-overhead. È assolutamente normale avere migliaia e migliaia di goroutine in esecuzione nel proprio programma.
Il risultato di utilizzare goroutine al posto di funzioni, per quanto riguarda le prestazioni, dipende interamente dalla natura di queste funzioni e dalla capacità di parallelismo dell’hardware.
Abbiamo due casi in particolare dove si beneficia particolarmente del vantaggio di avere goroutine:
- stiamo eseguendo task I/O bound
- stiamo eseguendo task cpu-bound su un processore multicore
Nel primo caso ci troviamo a sfruttare al meglio il parallelismo della cpu attraverso l’esecuzione di più goroutine.
Poniamo di aver ad esempio tre funzioni da eseguire in sequenza, le quali impieghino rispettivamente un secondo di calcoli cpu-bound, due secondi di calcoli, e la terza invece un’attesa input di circa due secondi.
func doSlimCalc() {} // 1 second
func doFatCalc() {} // 2 seconds
func getData() {} // 2 seconds I/O wait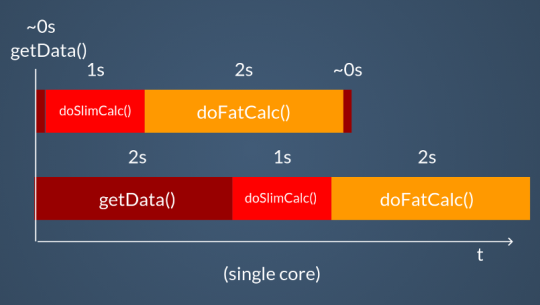
Anche su un singolo core si avrà comunque un vantaggio prestazionale, in quanto le goroutine in attesa di I/O saranno messe in pausa e al loro posto saranno nel frattempo eseguite le altre.
Se la CPU è multicore si avrà un ulteriore vantaggio, ovvero l’effettiva parallelizzazione delle goroutine su più core. Vediamo nel grafico i tre sistemi a confronto.
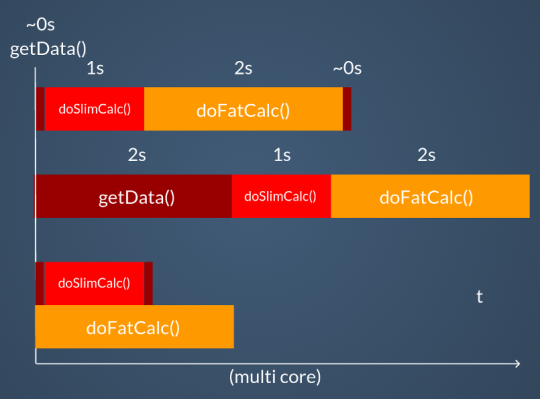
La situazione però si complica nel momento in cui le nostre funzioni dovranno in qualche modo interagire tra loro. In questo caso vogliamo evitare di utilizzare direttamente i soliti strumenti (in ogni caso disponibili nella libreria standard), come lock, mutex, semafori, etc…, e invece andremo ad utilizzare i channel.
Cerchi un corso su Go?
Scopri i corsi professionali Develer
Channel
I channel sono, come il nome suggerisce, canali di comunicazione.
- mono o bidirezionali
- concurrency safe
- tipizzati
- first-class citizen
I channel sono il modo giusto di sincronizzare goroutine gestendo dati e memoria. Sono tipizzati, e sono appunto first-class citizen, possono quindi essere passati come parametri a funzioni, salvati in variabili, e così via.
// Creazione di un channel
ch1 := make(chan int)
// Immissione di un dato nel channel
ch1 <- 1
// Lettura di un dato dal channel
num := <- ch1Vediamo un esempio:
package main
import (
"fmt"
"time"
)
func main() {
ch1 := make(chan string)
go func() {
ch1 <- "Hello"
ch1 <- "World!"
}()
go func() {
for {
fmt.Println(<-ch1)
}
}()
time.Sleep(1 * time.Second)
}Due funzioni lanciate come goroutine comunicano attraverso un channel di string. La prima produce parole e la seconda le scrive a schermo. Come abbiamo già visto per le goroutine, anche per i channel si nota l’estrema facilità d’uso.
Nell’usare i channel dobbiamo tenere a mente una massima che spiega la filosofia di design:
Don’t communicate by sharing memory. Share memory by communicating.
In altre parole:
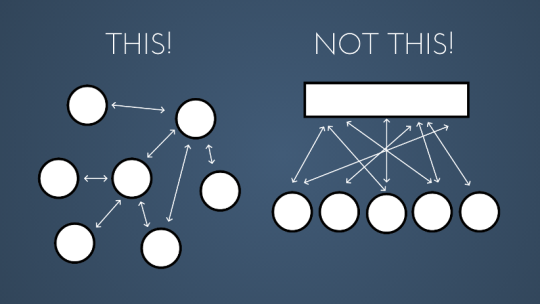
L’idea alla base è di costruire una struttura che utilizzi canali di comunicazione per sincronizzarsi e per condividere memoria, piuttosto che avere un’area di memoria condivisa da proteggere per evitare race condition.
Inoltre i channel ci offrono la comodità di essere sufficientemente di alto livello da nascondere i dettagli implementativi necessari per una corretta gestione del parallelismo.
Nel momento in cui due goroutine si collegano ai due lati di un channel, una in attesa di dati, l’altra ad inviare dati, si ha un momento di sincronizzazione.
Select
Manca ancora un tassello. In un caso reale avremo infatti decine e decine di channel, avremo diverse attese con migliaia di goroutine all’opera, e vorremmo gestire in modo efficiente tutto questo.
Pensiamo a due funzioni così:
func producerSlow(output chan string) {
for {
output <- "Message!"
time.Sleep(1 * time.Second)
}
}
func producerFast(output chan int) {
for {
output <- rand.Int()
time.Sleep(500 * time.Millisecond)
}
}Queste funzioni fanno una cosa molto comune: prendono un channel come parametro e usano quel channel come canale di comunicazione per immettervi dati. In questo esempio molto semplice, i due producer hanno tempi di elaborazione diversi.
Poniamo di voler stampare a video questi dati. Il nostro consumer sarà dunque una print. Un primo modo di gestire questa situazione potrebbe essere:
func main() {
ch1 := make(chan string)
ch2 := make(chan int)
go producerSlow(ch1)
go producerFast(ch2)
for {
fmt.Println(<-ch1)
fmt.Println(<-ch2)
}
}Il risultato è che abbiamo un momento di sincronizzazione forte nel consumer, dove stiamo annullando il vantaggio di avere delle goroutine.
Message!
5577006791947779410
Message!
8674665223082153551
Message!
6129484611666145821
Message!
4037200794235010051Stiamo andando alla velocità della goroutine più lenta. Possiamo fare meglio di così utilizando una select. Vediamo come.
func main() {
ch1 := make(chan string)
ch2 := make(chan int)
go producerSlow(ch1)
go producerFast(ch2)
for {
select {
case msg := <-ch1:
fmt.Println(msg)
case num := <-ch2:
fmt.Println(num)
}
}
}La select ha diversi casi. L’intero elemento è bloccante fino a che tutti i suoi casi sono bloccati. In questo caso la select rimane in attesa fino a che uno dei propri casi non si sblocca e viene eseguito.
Il primo effetto di questo è che stiamo sfruttando in modo più efficiente le nostre goroutine.
Message!
3916589616287113937
6334824724549167320
Message!
605394647632969758
1443635317331776148La goroutine più veloce non è costretta ad aspettare quella più lenta. Il suo ramo nella select sarà quello che si sbloccherà il doppio delle volte della più lenta, andando alla velocità massima possibile.
La select introduce quindi un meccanismo di sincronizzazione molto più evoluto. È un punto di smistamento dei canali per non far aspettare inutilmente il programma sulla lettura di canali bloccati.
Questo ci permette di poter estendere ulteriormente il nostro design con funzionalità come, ad esempio, timeout di attesa. Prendiamo la funzione After nel modulo time.
func After(d Duration) <-chan TimeQuesta funzione prende una durata e ritorna un canale di strutture Time. Il senso di ritornare un canale è che stando in attesa su di esso verremo sbloccati solo quando sarà scaduto il timeout dato dalla Duration in ingresso.
select {
case msg := <-ch1:
fmt.Println(msg)
case num := <-ch2:
fmt.Println(num)
case <-time.After(250 * time.Millisecond):
fmt.Println("Timeout!")
}Se dopo 250 millisecondi nessuno dei canali della select si è sbloccato, sicuramente lo sarà quello del timeout, uscendo dal blocco select. Il tutto realizzato con solo due righe di codice in più. Le possibilità sono veramente moltissime.
Conclusioni
Go offre una prospettiva sulla concurrency solida, efficace, semplice. Goroutine, channel e select sono primitive di linguaggio facili da usare e da capire, utili a costruire strumenti più sofisticati.
L’approccio di Go rende veramente accessibile il design di applicazioni asincrone e parallele a tutti.