Criticità di Go su sistemi embedded
Go è un linguaggio di nuova generazione che racchiude sia i vantaggi di prototipizzazione veloce di Python, che le prestazioni delle applicazioni C/C++. Questa caratteristica lo ha reso un linguaggio utilizzabile anche in ambito embedded, ma quali sono le accortezze da seguire per avere dei buoni risultati?
Requisiti delle applicazioni embedded
La caratteristica principale di un’applicazione embedded è la proprietà di real time, ovvero la capacità di reagire prontamente ad un certo evento, sia interno che esterno. Il tempo di reazione può essere lento o veloce, ma è importante che sia deterministico. Quando realizziamo un programma in Go, dobbiamo mettere in conto di avere un runtime su cui non abbiamo un controllo totale. In particolare Go ha un garbage collector (GC) che entra in azione a seguito dell’allocazione di memoria e gli eventi software sono gestiti dal runtime. Dobbiamo quindi cercare di limitare il più possibile i fattori che possano disturbare il flusso principale del nostro programma, causando delle latenze inaspettate.
Un aspetto importante è la performance, in quanto spesso le schede embedded hanno una potenza di computazione più limitata rispetto ad un sistema desktop. Tuttavia recentemente è possibile trovare sul mercato schede embedded sempre più potenti, anche multicore, quindi il classico approccio basato su un singolo main loop che gestisce tutto, non scala più. Perciò anche un’applicazione embedded ha necessità di sfruttare più core, eseguendo delle operazioni in parallelo.
Go è un linguaggio semplice, autocontenuto e veloce. Per queste ragioni, esso trova un suo spazio nel mondo embedded. In questo articolo utilizzerò, come riferimento, la versione 1.11 di Go.
Aspetti importanti da valutare
Consideriamo un’applicazione che gira su un sistema embedded con sistema operativo GNU/Linux. Gli aspetti importanti da valutare, per un corretto funzionamento, sono in generale i seguenti:
- Utilizzo di strutture dati e algoritmi efficienti.
- Ottimizzazione del critical path, ovvero dell’operazione principale.
- Interazione con le periferiche.
- Operazioni di I/O.
- Operazioni concorrenti.
- Gestione della memoria.
I primi 2 punti sono abbastanza generici, nel senso che, indipendentemente dal linguaggio di programmazione, dovremo scegliere delle strutture dati e degli algoritmi efficienti, al fine di migliorare l’operazione principale che il nostro sistema embedded deve espletare. Ad esempio, generalmente vorremmo evitare di fare operazioni con complessità O(n^2), oppure rimanere bloccati a lungo su delle syscall e così via.
Per quanto riguarda l’interazione con le periferiche, Go mette a disposizione la maggior parte delle syscall di sistema, quindi non ci dovrebbero essere problemi di comunicazione. Tuttavia, un codice idiomatico Go presenta alcune particolarità, che determinano anche un impatto sulle prestazioni. Vediamo quali sono le buone pratiche da seguire per ottenere un codice efficiente.
Cerchi un corso su Go?
Scopri i nostri corsi per aziende
Operazioni di I/O
La gestione dell’I/O è una parte importante che però deve essere pensata in modo diverso rispetto a come avviene di solito in un programma embedded, quando programmiamo in Go. Infatti, in generale, in Go non esiste il concetto di API non bloccante. Una delle interfacce base in Go è io.Reader, che definisce un metodo Read bloccante. Quindi dovendo leggere da un file descriptor oppure da una connessione TCP, ad esempio, il metodo rimane bloccato fino a che non ci sono dati da leggere, oppure il flusso finisce. Al contrario, programmando in C++, possiamo leggere da più sorgenti allo stesso momento, fino a che almeno una di esse non restituisce dati in ingresso.
Vediamo un semplice esempio in C/C++:
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <sys/poll.h>
int main(int argc, char **argv) {
struct pollfd fds[1];
// watch stdin for input
fds[0].fd = STDIN_FILENO;
fds[0].events = POLLIN;
while (1) {
const int timeout_msecs = 5000;
const int ret = poll(fds, 1, timeout_msecs);
if (ret <= 0)
break;
if (fds[0].revents & POLLIN) {
char buf[32];
memset(buf, 0, sizeof(buf));
const int n = read(fds[0].fd, (void *)buf, sizeof(buf)-1);
if (n < 0)
break;
printf("stdin has input data: %s\n", buf);
}
}
}Attraverso la syscall poll si ricevono delle notifiche riguardo i file descriptor che risultano leggibili (in
generale anche più di uno). Se dobbiamo leggere da molte connessioni TCP è perciò possibile utilizzare lo stesso
thread per effettuare letture non bloccanti, evitando quindi di rimanere in attesa su una connessione che non ha dati
in ingresso. Ogni qual volta è disponibile un nuovo dato, possiamo decidere come gestirlo, a seconda che la funzione di
lettura sia in esecuzione sul thread principale oppure su un altro thread in parallelo. Tuttavia al più dovremo
sincronizzare due thread tra loro, con l’uso di mutex oppure attraverso un socket inter-processo.
Vediamo lo stesso esempio scritto in Go:
package main
import (
"fmt"
"os"
"time"
)
func main() {
ch := make(chan string)
go func(ch chan<- string) {
buffer := make([]byte, 32)
for {
n, err := os.Stdin.Read(buffer)
if err != nil {
close(ch)
return
}
ch <- string(buffer[:n])
}
}(ch)
for {
select {
case s, more := <-ch:
if !more {
return
}
fmt.Println("data from stdin:", s)
case <-time.After(5 * time.Second):
return
}
}
}Nell’esempio precedente è stata avviata una Goroutine di lettura, che è valida per un solo stream di input. Se avessimo avuto più sorgenti da cui leggere, avremmo dovuto avviare altre Goroutine che operano in parallelo al loop principale. Perciò il flusso di esecuzione di un programma Go è diverso ed è più naturale sfruttare i core disponibili. In questo esempio abbiamo inoltre utilizzato un channel per inviare il dato letto al loop principale.
Per questi motivi, qual è il modo migliore per condividere i dati tra Goroutine diverse? Le possibilità a disposizione sono principalmente legate all’utilizzo di channel oppure di mutex.
Rimani aggiornato!
Ricevi novità su Develer e sulle tecnologie che utilizziamo iscrivendoti alla nostra newsletter.
Operazioni concorrenti
Supponiamo di avere un software in Go strutturato come al listato precedente. Si ricevono dati da molte connessioni TCP in ingresso e c’è una Goroutine di gestione principale che si occupa di elaborare questi dati. Come detto in precedenza, il modo idiomatico Go per gestire questa situazione è quello di lanciare una Goroutine per ogni connessione TCP, come mostrato nella figura seguente:
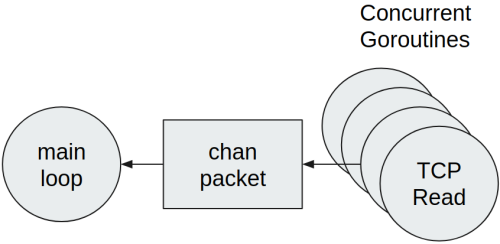
Ogni goroutine esegue lo stesso codice:
- Lettura dati dalla rete.
- Decodifica dei dati in strutture Go.
- Invio dei pacchetti al loop principale.
È stato scelto di utilizzare un channel Go per mettere in comunicazione le Goroutine con il loop principale. Inoltre ogni pacchetto ricevuto dalla rete viene inviato nel canale singolarmente. Questo metodo è corretto, tuttavia non è efficiente quando il numero di pacchetti ricevuti dalla rete è elevato. Scrivere in un canale comporta:
- Accedere a primitive di sincronizzazione, dato che i canali sono thread-safe.
- Gestire molti più eventi di lettura nella Goroutine ricevente.
Ne consegue che il loop principale non è in grado di gestire prontamente tutti i pacchetti ricevuti. In generale in questi casi, una modifica che può aiutare è utilizzare una slice di elementi, quindi riducendo il numero di scritture effettuate nel canale:
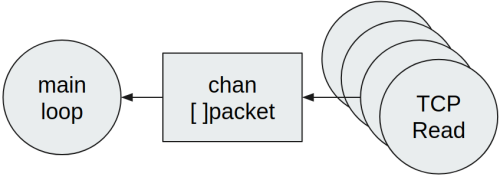
Perciò, nel caso vengano letti più pacchetti da una connessione di rete, conviene raggrupparli tutti in una slice ed inviare nel canale soltanto la slice stessa. Questa soluzione è migliore della precedente se vogliamo diminuire la latenza tra la ricezione di un pacchetto e la sua elaborazione. Lo svantaggio principale tuttavia consiste nell’aumentare la pressione sul garbage collector di Go, in quanto ogni slice deve essere creata a runtime e successivamente rilasciata, al momento della lettura. In aggiunta, ogni slice dovrà probabilmente avere dei puntatori ai pacchetti contenuti, quindi anche tali pacchetti dovranno essere rilasciati dal GC. Vedremo successivamente come migliorare la gestione della memoria.
Dal momento che creare dinamicamente degli oggetti o slice non è ottimale, un’altra soluzione possibile è utilizzare un mutex, al fine di condividere i dati con il loop principale:
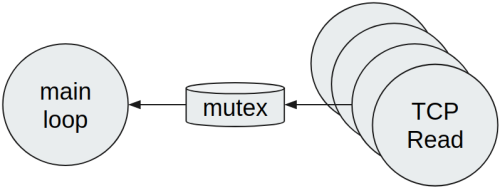
Questa soluzione presenta immediatamente degli svantaggi. Per prima cosa, il mutex è condiviso tra molte Goroutine e la contesa è molto elevata, quindi diventerà un collo di bottiglia. Bisogna anche considerare che lo scheduler del Go è cooperativo, quindi ogni Goroutine viene messa in esecuzione quando un’altra raggiunge un punto di sincronizzazione oppure chiama delle syscall. Per questo motivo un mutex unico condiviso aumenta la pressione di scheduling sulle Goroutine e la ricezione dei dati potrebbe non essere più fair. Se vogliamo seguire questa strada, a seconda di come sono partizionati i dati, è possibile eseguire uno shardening in modo da evitare la contesa su un singolo mutex.
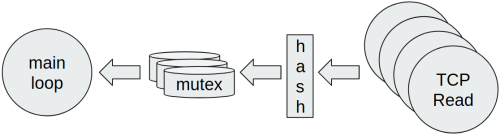
Per far questo in generale bisogna definire una funzione hash che mappi ogni pacchetto nella sua partizione di dati. In questo modo la contesa tra Goroutine concorrenti diminuisce, ma è sempre necessario prendere in considerazione eventuali conflitti. Perciò la contesa è minore, ma non si ridurrà totalmente a zero. La funzione di hash può essere decisa in base a dei parametri di configurazione e talvolta si può anche evitare, se è possibile separare i dati in base a qualche logica di progetto (ad. esempio indirizzo IP sorgente, campi contenuti nei pacchetti dati, etc…).
Si aggiunge per completezza che anche in Go si può utilizzare la syscall poll, quindi riducendo il numero totale di
Goroutine ad una. Comunque questo approccio non è idiomatico ed è un caso d’uso non tipico.
Gestione della memoria
Un aspetto molto importante da tenere sotto controllo quando si sviluppa un’applicazione emebedded è quello dell’utilizzo di memoria. Go ha una sua politica di gestione del GC, la cui spiegazione esula dagli obiettivi di questo articolo. È sufficiente sapere che la pressione del GC aumenta quanta più memoria dinamica viene allocata. Questo provoca l’intervento del GC più frequentemente, causando anche uno stop-the-world in minima parte, ovvero un’interruzione di tutto il flusso di esecuzione. In un sistema embedded il GC può causare quindi delle latenze inaspettate che vogliamo mantenere limitate. Nei prossimi paragrafi vediamo come sia possibile limitare gli effetti del GC.
Allocazione dinamica della memoria
Il lavoro del GC è quello di cercare quali parti di memoria non sono più utilizzate, cercando tutti i puntatori verso allocazioni di memoria. Quindi, utilizzando più memoria, il tempo di ricerca e di pulizia aumenta. Se il software necessita di molta memoria, allora potrebbe esserci un problema di performance. Un modo semplice per ovviare a questo inconveniente è quello di evitare i puntatori, usando quindi array di oggetti che non ne contengano.
Proviamo a misurare quanto tempo impiega il GC, eseguendo due test:
- A: allocazione dinamica di elementi senza puntatori
- B: allocazione dinamica di elementi con puntatori
package main
import (
"fmt"
"runtime"
"time"
)
type A struct {
value int
}
func testA() {
arr := make([]A, 1e6)
runGC()
arr[0] = A{}
}
type B struct {
value *int
}
func testB() {
arr := make([]B, 1e6)
runGC()
arr[0] = B{}
}
func runGC() {
t0 := time.Now()
runtime.GC()
fmt.Printf("test duration: %s\n", time.Since(t0))
}
func main() {
testA()
testB()
}test duration: 224.338µs
test duration: 5.023066msÈ chiaro dai risultati che il GC impiega molto più tempo a scansionare memoria che contiene puntatori. Da notare che questo comportamento non si presenta se gli array sono preallocati staticamente, come talvolta succede nelle applicazioni embedded.
Ci sono comunque alcuni tipi di dati Go che contengono al proprio interno dei puntatori. In questi casi quindi dobbiamo
fare attenzione quando si allocano oggetti che li contengono. Alcuni esempi di questi tipi di dati sono time.Time e
string.
Cosa facciamo se non possiamo evitare allocazioni dinamiche?
Non è sempre possibile evitare di utilizzare memoria dinamica. Riprendendo l’esempio dei pacchetti di rete, abbiamo visto che utilizzare una slice di elementi può aiutare al fine di ridurre il numero di scritture su un canale. In questo caso è necessario allocare una slice della dimensione giusta, da inviare nel channel di comunicazione.
Nel listato seguente si può vedere che molti slice di interi sono inviati nel canale da una Goroutine concorrente, verso
la Goroutine principale. Per effettuare un calcolo più preciso, il GC è stato disabilitato tramite l’istruzione
debug.SetGCPercent(-1), eseguendo l’operazione di GC soltanto una volta alla fine.
package main
import (
"fmt"
"runtime"
"runtime/debug"
"time"
)
func main() {
// let's disable the GC
debug.SetGCPercent(-1)
ch := make(chan []int)
go func(ch chan<- []int) {
for i := 0; i < 1e6; i++ {
ch <- make([]int, 3)
}
close(ch)
}(ch)
{
loop:
for {
select {
case _, more := <-ch:
if !more {
break loop
}
}
}
}
t0 := time.Now()
runtime.GC()
fmt.Printf("GC duration: %s\n", time.Since(t0))
}GC duration: 1.352792msIl tempo totale di GC è simile ai test precedenti, nel caso di memoria contenente puntatori. Questo è normale dal
momento che stiamo allocando molti slice. Per mitigare questo problema di allocazione, si può prendere in considerazione
l’utilizzo di un sync.Pool. Questo oggetto serve per gestire l’allocazione dinamica, riutilizzando oggetti che sono
stati già allocati in precedenza. Vediamo come sia possibile modificare l’esempio precedente a tale scopo:
package main
import (
"fmt"
"runtime"
"runtime/debug"
"sync"
"time"
)
type mySlice struct {
Val [3]int
}
func main() {
// let's disable the GC
debug.SetGCPercent(-1)
ch := make(chan *mySlice)
pool := sync.Pool{
New: func() interface{} {
return &mySlice{}
},
}
go func(ch chan<- *mySlice) {
for i := 0; i < 1e6; i++ {
ch <- pool.Get().(*mySlice)
}
close(ch)
}(ch)
{
loop:
for {
select {
case s, more := <-ch:
if !more {
break loop
}
pool.Put(s)
}
}
}
t0 := time.Now()
runtime.GC()
fmt.Printf("GC duration: %s\n", time.Since(t0))
}GC duration: 191.448µsIl tempo di garbage collection risulta notevolmente ridotto! Tuttavia sono state necessarie alcune modifiche. Per prima
cosa, ogni qual volta vogliamo istanziare un oggetto, si chiama il metodo sync.Pool.Get(). In modo analogo, una volta
che l’oggetto è stato utilizzato, esso può essere rilasciato tramite il metodo sync.Pool.Put(). Il sync.Pool è
thread-safe, quindi questi metodi si possono utilizzare da Goroutine differenti. Inoltre, siccome questi oggetti sono
riutilizzati, è importante eseguire un Clear dei dati contenuti, dopo Get oppure prima di Put.
Un’altra modifica è l’introduzione della struttura mySlice, che rappresenta una slice con un numero fisso di elementi. Ovviamente spesso capita di non sapere a priori quanti elementi sono disponibili. Per questo motivo si può aggiungere un parametro Size che indica il numero delle posizioni effettivamente utilizzate. Da notare che però sarebbe auspicabile evitare questo approccio, per non doversi implementare nuovamente il tipo slice di Go. Per questa ragione è consigliabile avere una struttura definita in questo modo:
type mySlice struct {
Val []int
}
func (ms *mySlice) Clear() {
for i := range ms.Val {
ms.Val[i] = 0
}
ms.Val = ms.Val[:0]
}Gli elementi saranno aggiunti allo slice nel modo usuale tramite append. Inoltre è fondamentale che Clear faccia il
reset di tutti gli elementi effettivamente utilizzati, prima di reimpostare la variable slice a ms.Val[:0]. Tale
operazione crea una copia di una slice ma con zero elementi, che punta alla stessa area di memoria già allocata. Infatti
se la slice sottostante venisse riallocata tutte le volte, potrebbe essere vanificato l’utilizzo del sync.Pool.
Closure ed escape analysis
Il linguaggio Go permette di definire delle funzioni anonime e più in generale delle closure. Mentre le prime non sono in generale un problema per le performance, le seconde invece possono esserlo. Una closure in Go si concretizza nella creazione di un oggetto che mantiene uno stato su cui la funzione può operare. Se ci sono delle operazioni che fanno uso intensivo di closure, allora ancora una volta si può verificare un peggioramento dei tempi di garbage collection. Perciò è meglio non usare closure nel flusso critico di programma, a meno che il compilatore non sia in grado di evitare il loro spostamento nella memoria heap. Questa ottimizzazione prende il nome di escape analysis e serve a determinare se ci sono dei riferimenti ad un valore che sfuggono dalla funzione in cui sono dichiarati. Se nessun riferimento sfugge, allora il valore può essere posizionato nello stack della funzione e quindi non c’è necessità di allocazione e conseguente liberazione di memoria. Le regole di escape analysis non fanno parte della specifica di linguaggio Go, quindi possono cambiare da una versione all’altra.
package main
import "os"
func adder(x, y int) func() int {
return func() int {
return x + y
}
}
func main() {
ret := adder(1, 3)()
os.Exit(ret)
}Ecco l’output dell’esecuzione del programma, abilitando l’escape analysis con il parametro -gcflags '-m':
$> go run -gcflags '-m' foo.go
./foo.go:6:9: can inline adder.func1
./foo.go:6:9: func literal escapes to heap
./foo.go:6:9: func literal escapes to heap
exit status 4Si può vedere che la funzione di ritorno di adder viene allocata nella memoria heap. Il programma precedente può
essere riscritto tramite la creazione di una struttura “contesto”, convertendo la closure in un metodo di tale oggetto.
package main
import "os"
type context struct {
x, y int
}
func (c context) Add() int {
return c.x + c.y
}
func main() {
ret := context{1, 3}.Add()
os.Exit(ret)
}Si può verificare adesso che i valori sono allocati tutti nello stack.
$> go run -gcflags '-m' foo.go
./foo.go:9:6: can inline context.Add
./foo.go:14:26: inlining call to context.Add
<autogenerated>:1: (*context).Add .this does not escape
exit status 4Il logging può essere costoso
In un sistema embedded, come in ogni altro, la possibilità di generare messaggi informativi o di errore è fondamentale.
Attraverso il logging si possono identificare delle anomalie oppure verificare il corretto funzionamento del software.
In Go, quando vogliamo stampare dei messaggi, usiamo la libreria standard tramite le funzioni del package fmt. Però,
la funzione Printf è definita così:
func Printf(format string, a ...interface{}) (n int, err error)Dal punto di vista delle prestazioni, il problema è molteplice e riguarda più che altro il secondo parametro. Infatti il
tipo interface{} non può essere determinato a compile time, quindi causa sia un’allocazione che la necessità di
determinare a runtime il tipo reale del dato. Ad esempio, possiamo vedere nel programma seguente di esempio, che
addirittura una costante viene spostata nella memoria heap.
package main
import "fmt"
func main() {
fmt.Printf("%d\n", 1)
}$> go run -gcflags '-m' foo.go
./foo.go:6:21: 1 escapes to heap
./foo.go:6:12: main ... argument does not escape
1Un libreria molto utile per effettuare il logging in modo efficiente è zerolog, con la quale è possibile anche impostare il livello di log di ogni messaggio. Più in dettaglio, se nel programma aggiungiamo molti messaggi di debug, essi avranno un impatto molto limitato, quasi zero. Se invece questi aspetti non vengono presi in considerazione, allora anche i messaggi di debug possono avere un impatto negativo sulle performance del programma, anche nel caso in cui il livello di log sia superiore a debug (quindi evitandone la stampa).
Eseguendo l’escape analysis sul prossimo programma che utilizza zerolog, abbiamo conferma che non viene fatta nessuna allocazione di memoria.
package main
import "github.com/rs/zerolog/log"
func main() {
log.Info().Int("val", 1).Msg("")
}$> go run -gcflags '-m' foo.go
{"level":"info","val":1,"time":"2019-01-30T17:18:20+01:00"}Conclusioni
Questo articolo fornisce dei concetti introduttivi per utilizzare il Go in ambito embedded. Ho cercato di elencare i punti più importanti, che si dovrebbero tenere in considerazione quando dobbiamo scrivere un software efficiente.
Riassumendo brevemente, abbiamo visto che Go permette di sfruttare le architetture CPU più recenti, grazie al modello
concorrente del suo runtime. Per quanto riguarda la sincronizzazione, è idiomatico utilizzare i channel, raggruppando i
dati da scrivere in slice. È possibile anche utilizzare i mutex, facendo attenzione a non creare colli di bottiglia tra
le Goroutine. Inoltre, specialmente per le applicazioni embedded, è fondamentale tenere sotto controllo i tempi di GC.
Per ridurre le allocazioni, si può sfruttare il sync.Pool, riutilizzare delle slice già create in precedenza, oppure
evitare le closure. Infine, anche il logging può risultare oneroso in termini di allocazioni, quindi è conveniente
utilizzare una libreria pensata proprio per questo problema.
In generale, tuttavia, non è necessario che il codice sia completamente ottimizzato, ma può succedere di doverlo fare per il flusso di esecuzione principale. Infatti, se non è strettamente necessario, è meglio leggere del codice chiaro e comprensibile, piuttosto che uno complesso ma più efficiente. In effetti un programma Go generalmente si adatta bene a situazioni in cui sono richieste prestazioni elevate, perciò vale sempre la regola d’oro di evitare le ottimizzazioni preventive.