Metriche di progetto con Grafana
Lo sviluppo di un progetto prevede molte attività ed una metodologia ben strutturata, al fine di portare avanti le specifiche in modo agile. Una parte fondamentale dello sviluppo è quella della definizione (e della messa in pratica) di tutte le attività volte al mantenimento delle funzionalità implementate. Questo per evitare regressioni ogni volta che si apportano modifiche al codice sorgente. Solitamente le attività di testing possono essere svolte a vari livelli, su un progetto:
- Test di Unità.
- Test di Integrazione.
- Sistema di Continuous Integration (CI).
- Benchmark di Prestazioni.
Come sappiamo, il livello più basso è rappresentato dai test di unità. A questo livello, si garantisce che una certa funzione o unità base di codice si comporti come atteso. Il livello seguente è rappresentato dai test di integrazione, ovvero verificare casi d’uso come da specifica, mettendo insieme varie parti di codice. Ci sono poi meccanismi per l’esecuzione automatica di questi test, automatizzando anche azioni specifiche e ripetitive (come la creazione di artefatti), attraverso un sistema di continuous integration, come CircleCI, GitHub Actions o qualsivoglia. Infine, è bene considerare che ci possono essere delle parti di codice che fanno maggior uso di CPU, quindi si possono implementare dei benchmark per valutarne le prestazioni.
I livelli di testing menzionati in precedenza sono molto importanti, ma alcune volte abbiamo a che fare con progetti complessi, in cui si rende necessario tenere sotto controllo le prestazioni generali del sistema. I benchmark di prestazioni non sono sufficienti, in quanto un sistema di produzione mostra un comportamento che è dato dall’interazione di molti fattori, quali tempo di esecuzione di una certa funzione, latenze di rete, blocchi su acquisizione di mutex e molto altro. Per queste ragioni, qualsiasi commit può inconsapevolmente peggiorare le prestazioni generali del sistema, senza che ce ne possiamo accorgere. Come possiamo tenere sotto controllo le prestazioni?
Come tenere sotto controllo le prestazioni
Per garantire che un sistema non abbia delle regressioni di performance, dobbiamo innanzitutto definire delle grandezze, o delle metriche, che vadano a misurare degli aspetti che sono ritenuti importanti per un corretto funzionamento. Ogni sistema avrà delle caratteristiche diverse, quindi queste metriche cambiano da progetto a progetto e devono essere utili per analizzare successivamente il funzionamento in produzione.
Facciamo un esempio di un ipotetico sistema che analizza degli oggetti durante il loro movimento lungo un nastro trasportatore. Gli oggetti passano inizialmente in prossimità di alcuni sensori che ne acquisiscono le caratteristiche, poi un’unità di business logic (BL) elabora i dati entro un determinato punto limite (checkpoint). Infine tali oggetti saranno gestiti da alcuni attuatori a valle, durante il loro proseguimento sul nastro trasportatore.
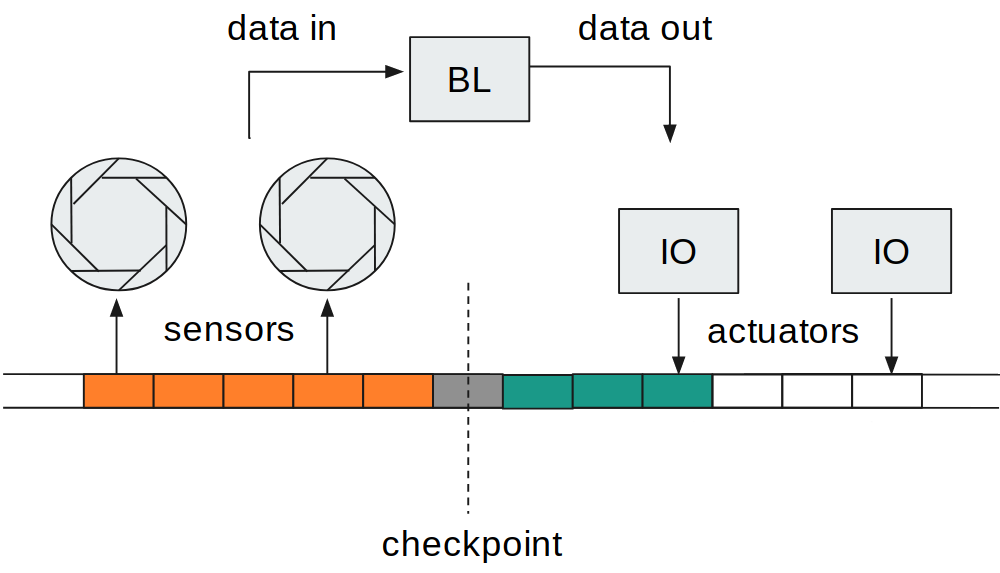
Nel sistema rappresentato in figura precedente, è chiaro che se l’unità centrale BL non riesce a recuperare ed analizzare tutti i dati per un certo oggetto entro il checkpoint, ne consegue che gli attuatori a valle non potranno essere pilotati in tempo. Per questo motivo, possiamo definire delle metriche caratteristiche che rappresentano il funzionamento del sistema, ad esempio:
- T1: Tempo di acquisizione misure, prima del checkpoint.
Questa è la parte evidenziata in arancione in figura.
- T2: Tempo di elaborazione misure, sul checkpoint.
Questa è la parte evidenziata in grigio in figura.
- T3: Tempo di anticipo per pilotare il primo attuatore.
Questa è la parte evidenziata in verde in figura.
Se misuriamo i tempi T1, T2 e T3 per ogni oggetto che passa lungo il nastro trasportatore, allora possiamo analizzare il funzionamento del sistema. Ad esempio, se il tempo T1 diventasse prossimo allo 0, allora vuol dire che il margine prima del checkpoint si riduce troppo. Questo potrebbe essere causato da ritardi di rete, tempo di elaborazione dei sensori ed altri fattori. Tuttavia, in sistemi complessi non è semplice valutare questi fattori. Infatti i vari test di integrazione o benchmark non ci aiutano, né possiamo inserire stampe o log di debug, in quanto possono alterare le prestazioni del sistema e la quantità di tali log sarebbe troppo onerosa da leggere. Sopraggiunge perciò la necessità di avere un sistema per il monitoraggio di queste metriche in modo efficiente e comprensivo.
Aggiunta di metriche al codice sorgente
La prima soluzione che viene naturale è quella di implementare le metriche “manualmente” nel codice sorgente, cioè nel caso del nostro esempio, calcolare i tempi T1, T2 e T3 e poi farne una media, valore minimo e valore massimo. Questi calcoli devono ragionevolmente essere eseguiti in tempo costante, per non perturbare il funzionamento di sistema. Inoltre dobbiamo anche implementare un modo per recuperarli per scopi di visualizzazione. Quest’ultima parte è fondamentale, perché non sono solo metriche di debug in fase di sviluppo, bensì giocano un ruolo chiave anche in produzione. Ne consegue che sia meglio utilizzare una libreria già pronta.
In un progetto Go su cui ho lavorato, inizialmente abbiamo utilizzato una libreria chiamata Tachymeter. Questa libreria è molto conveniente e semplice da usare. Essa cattura eventi di tempistiche in stile buffer circolare, in modo efficiente. Questo ne è un esempio per fare una misurazione:
import "github.com/jamiealquiza/tachymeter"
func main() {
t := tachymeter.New(&tachymeter.Config{Size: 50})
for i := 0; i < 100; i++ {
start := time.Now()
doSomeWork()
t.AddTime(time.Since(start))
}
fmt.Println(t.Calc())
}
Il codice istanzia un oggetto tachymeter che mantiene 50 campioni e poi esegue 100 osservazioni di una grandezza che rappresenta un tempo. L’ultima istruzione Println stampa infine alcuni dati statistici che la libreria ha calcolato, come la media, percentili, minimo, massimo, deviazione standard ed altro.
Un altro aspetto molto utile è che questa libreria dispone di vari formati di output per i valori statistici acquisti:
- Formato testuale multi riga;
- Formato JSON;
- Istogramma testuale;
- Istogramma HTML.
Il formato output HTML è comodo perché consente di esporre i grafici su un endpoint HTTP e di visualizzarli tramite browser. Ci possiamo collegare a tale endpoint all’indirizzo IP della macchina che fa girare il nostro software. Un esempio di cosa si possa ottenere è mostrato nella figura seguente:
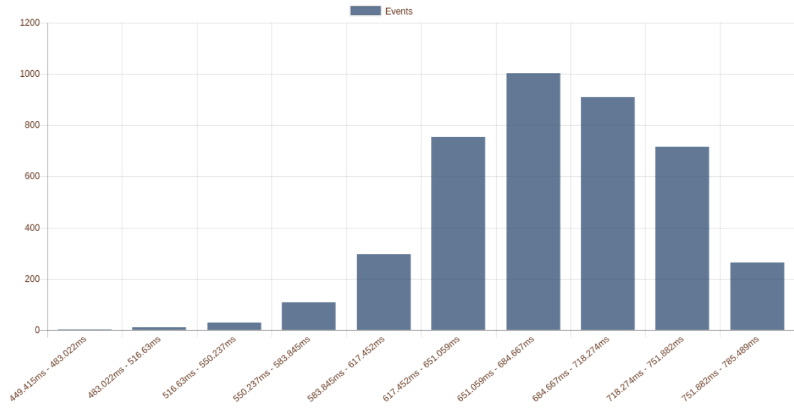
Nonostante la semplicità di utilizzo, ci sono alcuni problemi che possono diventare limitanti in sistemi complessi:
- Per visualizzare le statistiche “live”, dobbiamo fare polling “manuale” sul nostro sistema.
- Come si dimensiona il buffer di campioni? Nell’esempio precedente la dimensione era 50, tuttavia essa dipende molto dal tipo di metrica. Una grandezza che viene aggiornata ogni 10ms probabilmente avrà bisogno di una finestra più larga per calcolarne le statistiche, rispetto ad un’altra che viene aggiornata ogni secondo.
- I calcoli delle statistiche sono fatti “a bordo”, quindi maggiore è il buffer di campioni, maggiore sarà il tempo impiegato per estrarre le statistiche.
- Mancanza di correlazione temporale. Questo significa che è difficile correlare tra loro metriche diverse, per debuggare i problemi.
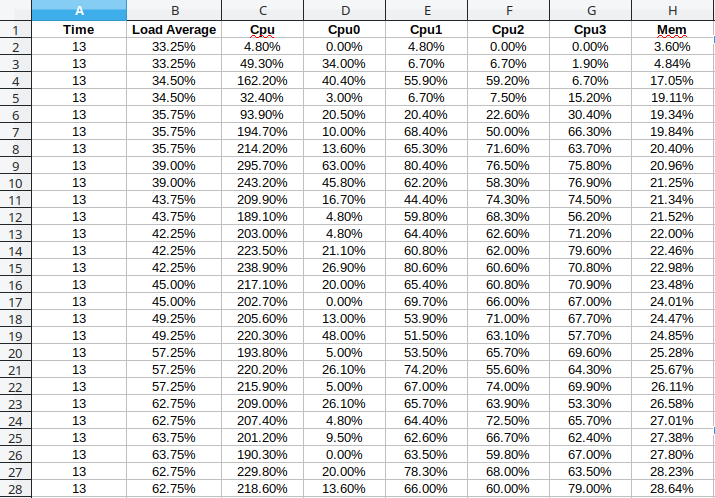
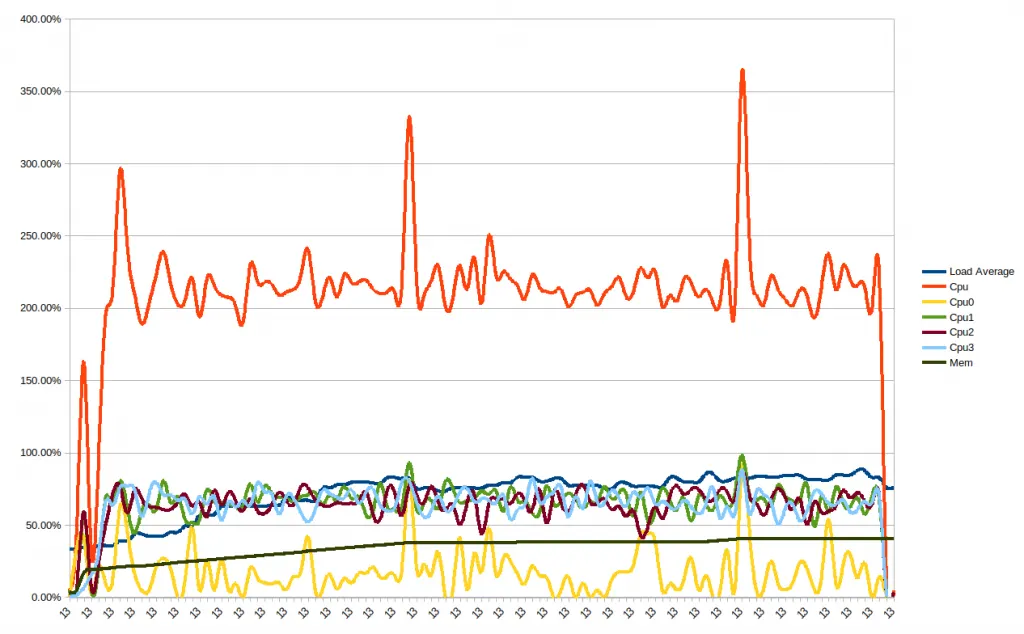
- Mancanza di metriche del sistema operativo. Se vogliamo analizzare la CPU o la memoria utilizzata, dobbiamo ricorrere a script fatti a mano e fogli Excel per tirare fuori alcuni grafici che ci interessano.
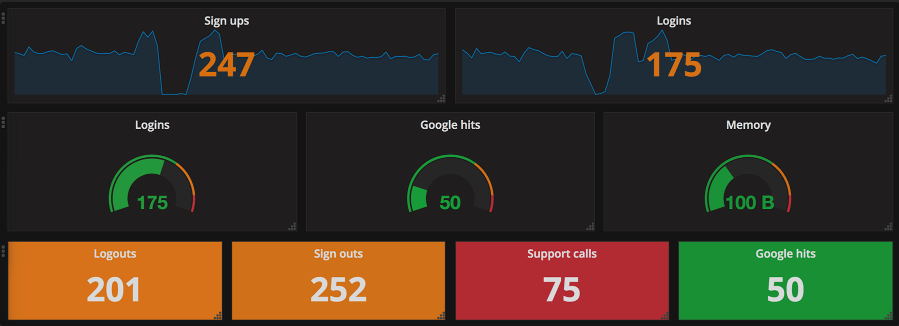
Soluzione con Prometheus e Grafana
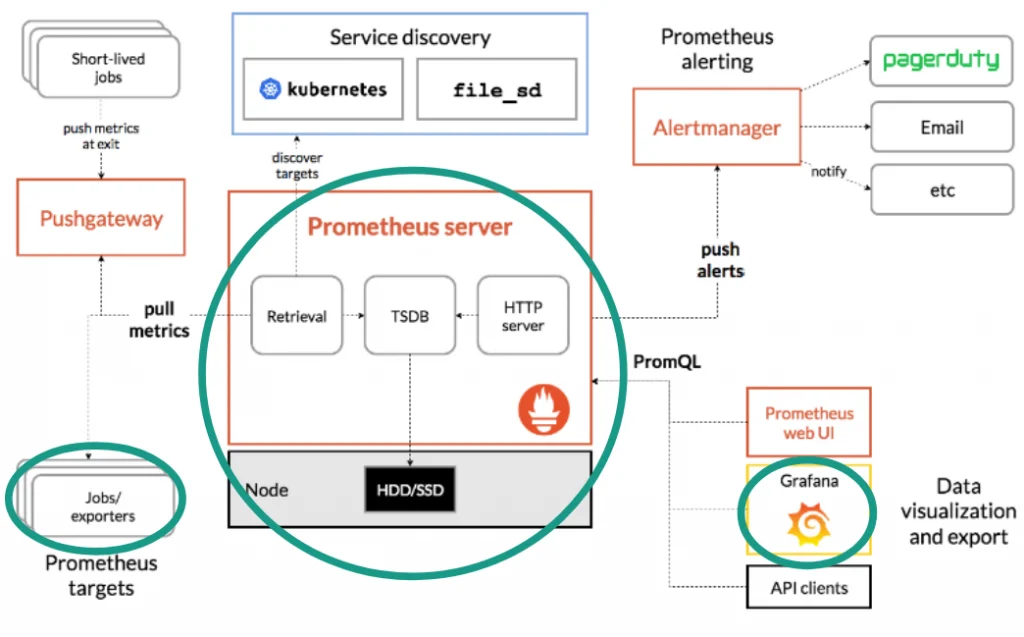
Per ottenere una soluzione di reportistica completa, che superi le limitazioni indicate in precedenza, si può valutare l’introduzione di un’architettura più estendibile e complessa, rappresentata dalla coppia Prometheus con Grafana. Per una spiegazione dettagliata di questi due componenti, si rimanda ai siti di riferimento. Tuttavia in figura seguente è possibile vedere un risultato che si può ottenere, per confronto con le soluzioni precedenti:


L’architettura che abbiamo utilizzato nel nostro progetto Go è formata dai seguenti elementi:
- Libreria Prometheus in Go lato client, per fare osservazioni di metriche ed esportarle verso il server tramite endpoint HTTP.
- Server Prometheus che effettua polling periodico ed estrae i valori grezzi delle metriche dalla macchina in funzionamento.
- Servizio web Grafana di reportistica che visualizza i dati del server Prometheus.
L’utilizzo della libreria Prometheus in Go è semplice. Ad esempio, una metrica di tipo istogramma (ma ce ne sono anche di altri tipi) si crea in questo modo:
RecvTime = prometheus.NewHistogram(
prometheus.HistogramOpts{
Namespace: "myprj",
Name: "reception_time_ms",
Help: "Reception time in milliseconds",
// -500 ms -> 2500 ms
// 12 buckets of 250ms each
Buckets: prometheus.LinearBuckets(-500, 250, 12),
})
È stata aggiunta la metrica RecvTime, che può essere utilizzata in un punto qualsiasi del nostro codice Go. Rispetto alla libreria Tachymeter, in questo caso si possono configurare i parametri della grandezza, a seconda delle sue caratteristiche. In questo caso è definito un range che va da -500 ms a 2500 ms. Dimensionare correttamente i bucket è importante, dal momento che questo ha impatto sulla risoluzione dei valori registrati e della quantità di dati prelevati periodicamente dal server Prometheus. Ogni qual volta vogliamo registrare un valore di questa metrica in Go, supponendo che calcTime sia il valore calcolato nel nostro codice, possiamo usare un’istruzione di questo genere:
RecvTime.Observe(float64(calcTime / time.Millisecond))La struttura generale di questa architettura di reportistica è descritta in dettaglio sulla pagina di overview di Prometheus, ma nel progetto Go su cui ho lavorato abbiamo utilizzato solo alcune funzionalità, indicate nella figura seguente:
Come si vede, introdurre questa soluzione in un progetto esistente può essere complicato e ci sono dei costi da considerare, sia per l’implementazione che per il mantenimento.
Il vantaggio di utilizzare questo approccio è che si può estendere anche con altri exporter, ovvero meccanismi per l’esportazione di metriche di sistemi di terze parti, spesso liberamente disponibili online. Ad esempio, un componente che abbiamo trovato molto utile nel nostro progetto è il node_exporter. Questo processo, se attivato, espone automaticamente moltissime metriche del sistema operativo GNU/Linux, come quelle mostrate nella figura dei grafici in precedenza. Diventa perciò possibile mettere in relazione il funzionamento dei nostri processi con l’andamento delle risorse del sistema operativo. Per esempio, si possono mettere in relazione errori di traffico di rete con eventuali problemi del nostro programma di produzione e molto altro ancora. Non è una potenzialità da sottovalutare, soprattutto quando ci sono diversi componenti da collegare insieme, anche sviluppati da team diversi.
Analisi delle prestazioni con Grafana
Una volta identificate le metriche di sistema, è necessario scegliere il loro tipo, ovvero che proprietà statistiche sono di nostro interesse. Prometheus dispone delle metriche di tipo Counter, Gauge, Histogram e Summary (simile ad Histogram, ma con caratteristiche diverse di cui non entreremo nel dettaglio in questo articolo). Inoltre, per ogni tipo Prometheus, esiste un pannello Grafana appropriato che ne consente la visualizzazione. Nella figura seguente, sono mostrati alcuni Gauge e Counter, con dei pannelli Grafana.
Il tipo Counter rappresenta un contatore che si incrementa in modo monotono. Può essere usato per mostrare il numero di errori che si sono verificati, il numero di richieste ricevute e così via. Il tipo Gauge mostra un valore singolo, che può aumentare o diminuire nel tempo. Quindi esso può essere usato per mostrare il livello di utilizzo CPU o memoria. Il tipo Histogram permette, invece, di effettuare osservazioni in bucket configurabili e di visualizzare il grafico dei percentili.
Per esempio, se consideriamo il novantesimo percentile, questo mantiene l’andamento del 90% dei valori registrati per quella misura. Ciò rappresenta uno strumento buono per tenere sotto controllo l’andamento delle prestazioni del progetto. Supponiamo che ad un centro punto, nella base di codice entri un commit per cui tutti i test di unità e integrazione risultino soddisfatti, ma che peggiori molto le prestazioni generali. La situazione che si verifica potrebbe essere simile a quella mostrata in figura, prima (a sinistra) e dopo (a destra) aver applicato il commit:
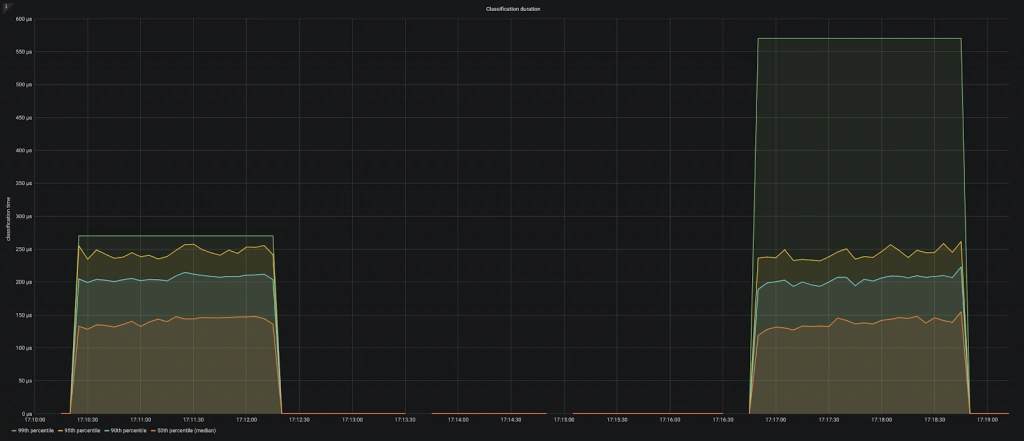
Se i grafici mostrati rappresentano un tempo di elaborazione, allora questo significa che il commit in questione ha causato un degrado delle prestazioni, in quanto il tempo di elaborazione (visualizzato col percentile 99%) è aumentato parecchio. Quindi probabilmente succederà che, successivamente, altri commit faranno sforare il limite imposto per il tempo di elaborazione, pur facendo aumentare questo tempo soltanto in modo lieve. Risulterà pertanto difficile trovare il vero commit che ha causato l’aumento più importante del tempo di elaborazione, pur senza sforare il limite temporale in quel momento.
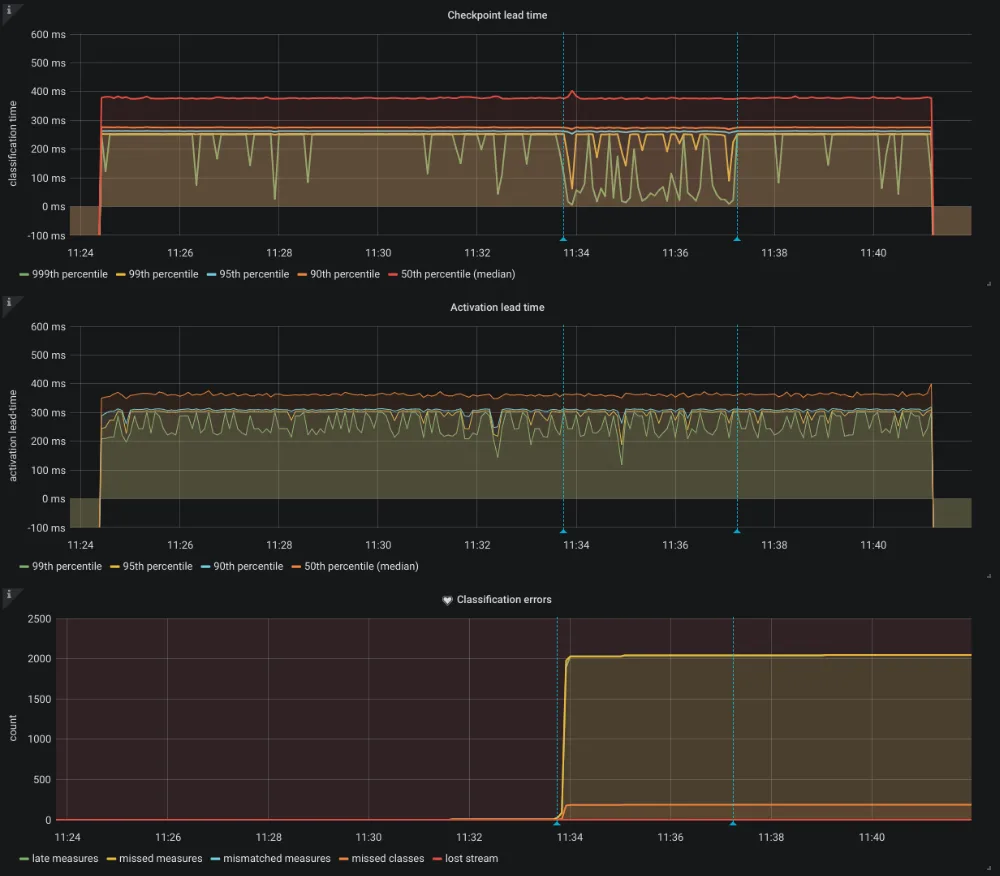
Un’altra funzionalità utile di Grafana è quella di mettere in correlazione temporale metriche diverse. Se abbiamo una grandezza che conteggia il numero di errori che si sono verificati, spesso può risultare difficile capire quale sia il motivo di questi errori, soprattutto se essi si presentato in un certo istante. Tuttavia, mettendo in correlazione il numero di errori con (ad esempio) il tempo di ricezione delle misure, potremmo capire che a fronte di un ritardo sulla ricezione di alcuni dati, allora il sistema presenta un malfunzionamento. Grafana consente anche di selezionare range temporali e di fare zoom sulla parte interessata. In figura seguente, possiamo vedere un esempio di come una perturbazione del grafico in alto possa essere messo in relazione ad un incremento degli errori visualizzato nel grafico più in basso:
Conclusioni
Per concludere, nella realizzazione di sistemi complessi può capitare che le consuete modalità di testing non siano sufficienti per garantire la corretta funzionalità di produzione del nostro sistema, dal punto di vista delle prestazioni. Per questo motivo, si rende utile effettuare e visualizzare misurazioni di punti specifici di funzionamento, ovvero introdurre alcune metriche di progetto. Le metriche devono esporre caratteristiche salienti, quindi è richiesta una conoscenza approfondita del progetto. Gli strumenti che ci vengono in soccorso per questa attività sono Prometheus e Grafana. Tuttavia, c’è da considerare che per la messa in opera e anche per la manutenzione degli stessi, è richiesto del tempo di sviluppo non trascurabile. Una volta configurato il tutto, il sistema sarà monitorabile anche in produzione e, vista la semplicità con cui è possibile visualizzare i grafici, anche il committente può impare ad utiizzare lo strumento ed essere così d’aiuto su possibili malfunzionamenti. È anche bene non esagerare troppo con l’esportazione di metriche, dato che anch’esse hanno un costo a runtime, seppur minimo. Bisogna trovare il giusto compromesso tra ciò che è necessario ed evitare di introdurre misure di debug, ovvero soltanto utili allo sviluppo ma che perdono senso in produzione. Non c’è da dimenticare che potrebbe essere utile fare un backup o ripristinare le metriche acquisite, per replicarle su un altro server. Ho trovato quest’ultimo aspetto laborioso da implementare, quindi credo che possa essere sicuramente un miglioramento, per questi strumenti di reportistica. In definitiva, l’analisi di statistiche a runtime è stata fondamentale sul progetto a cui ho lavorato ed ha consentito anche a membri del team, con meno esperienza sul progetto, di evitare errori.