Git: come scrivere commit e perché
Autore: Federico Guerinoni
Prerequisiti
Partendo da zero git è un software open-source nato per tenere traccia dei cambiamenti. Quali cambiamenti? Tutti i cambiamenti, teoricamente si può tenere traccia di ciò che si vuole in un formato leggibile dall’uomo, codice sorgente, modifiche alla lista della spesa o altro. Spoiler: tiene anche traccia dei cambiamenti di file binari come file eseguibili, file di office o altri strani formati ma questo non è il focus di questo articolo.
Cos’è un commit? È una “registrazione” dei cambiamenti, puoi vederla come un’istantanea dei tuoi file in un momento specifico della storia. Quando “committi” qualcosa il sistema traccia l’autore, il timestamp e un messaggio. Ora riassumiamo alcune buone pratiche generali da adottare quando si scrive un commit.
- ogni commit dovrebbe avere una singola responsabilità per un singolo cambiamento
- limitare l’oggetto a 50 caratteri
- limitare il corpo a 72 caratteri
- usare lo il tempo verbale imperativo nel soggetto
- scrivere il soggetto in maiuscolo
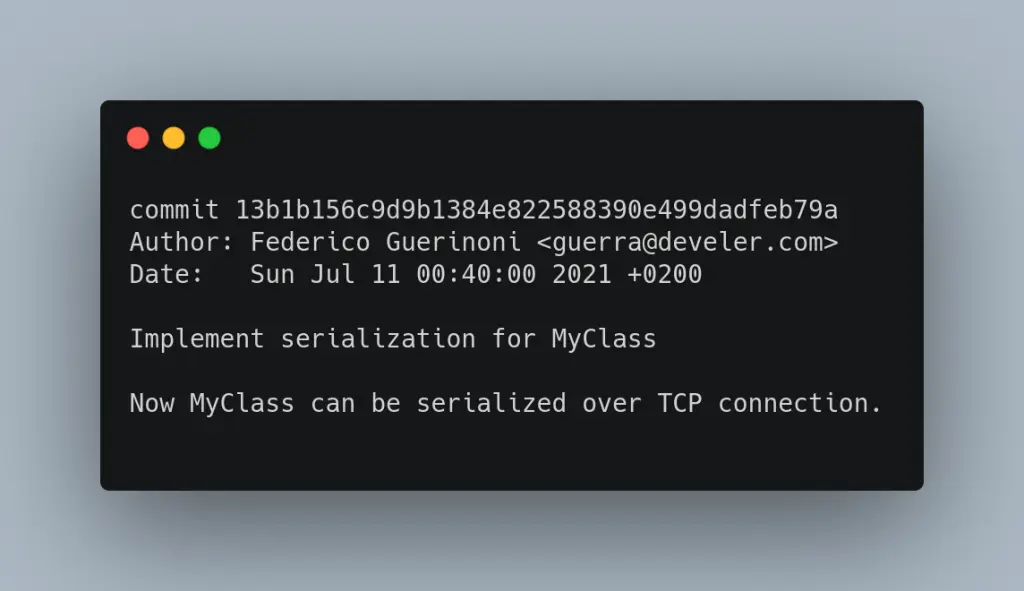
Nell’immagine seguente puoi vedere un semplice esempio di un buon messaggio di commit.
Git flow (flusso di lavoro)
Dopo la prima parte introduttiva possiamo analizzare il flusso di Git. Questo è un passo importante da tenere a mente quando scrivi un commit o quando si sceglie la strategia e le regole di commit per il tuo progetto.
Un flusso in Git è come il codice sarà integrato e sviluppato da tutti i membri del team. Ci sono molti tipi diversi di flusso e vi incoraggio a cercare online tutti i modelli per trovare il migliore che si adatta alle vostre esigenze, ma qui mi concentrerò solo sulla differenza che ogni modello ha sul vostro messaggio di commit.
Se avete familiarità con git sapete che c’è un ramo che è considerato “il default” e il riferimento per tutte le caratteristiche di un software, questo ramo può essere chiamato “master” o “main” o “mainline”. In base alla strategia che si segue ci sono molti modi diversi di interagire con questo ramo di default. Questi flussi che potete adottare sono qualcosa di teorico, sono le regole che stabilite per il vostro progetto e con il vostro team, non c’è un vero standard e gli strumenti che usate possono aiutare a seguire questo modello o possono essere solo un’interfaccia per git.
Esempio 1: ramo master, ogni membro del team parte da master e crea un ramo per una funzione specifica e dopo una revisione sarà unito al ramo master. Ogni <n> commit si può scegliere di fare un rilascio usando un tag su un commit di master.
Esempio 2: ramo master per la produzione, ramo di sviluppo per mantenere e unire tutte le cose che ogni membro vuole unire. In questo caso dopo molti test o rilasci beta il ramo di sviluppo sarà unito al ramo master per un rilascio.
Esempio 3: ramo master per la produzione, il team crea un ramo “feature” con una grande funzionalità e ogni membro che lavora su quella inizia da lì e crea un altro ramo per ogni sotto caratteristica che sarà unita al ramo feature “principale”. Quando questo grande sviluppo sarà finito, tutto sarà fuso nel ramo principale.
Esempio 4: ramo master, ogni membro del team invia un singolo commit al master che include qualcosa di stabile e che non rompe altre cose. In questo caso ogni commit forse sarà un po’ più grande e viene rivisto senza un PR (pull request).
Con questi esempi spero di avervi dato una piccola panoramica di come potrete organizzare il vostro flusso di lavoro per il vostro progetto. Allora come può questo influire su come dovrei scrivere un commit? Vediamo…
Git merge vs rebase and merge
Questa è un’altra regola da aggiungere nel vostro team, perché questo aspetto è il nucleo della motivazione di come si dovrebbe scrivere un commit.
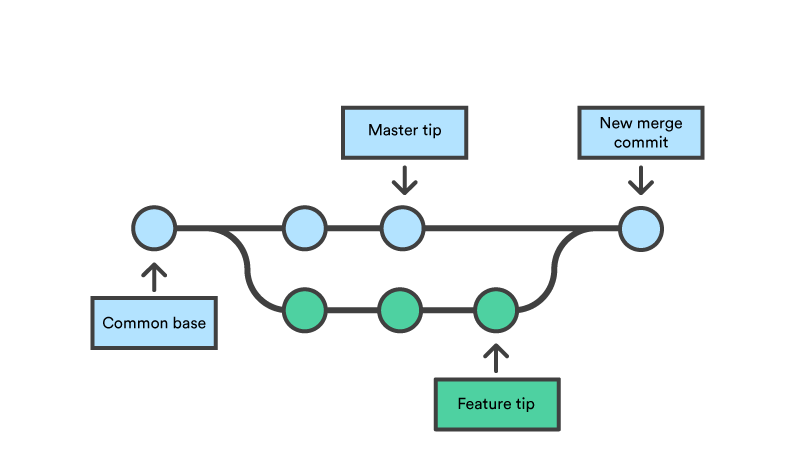
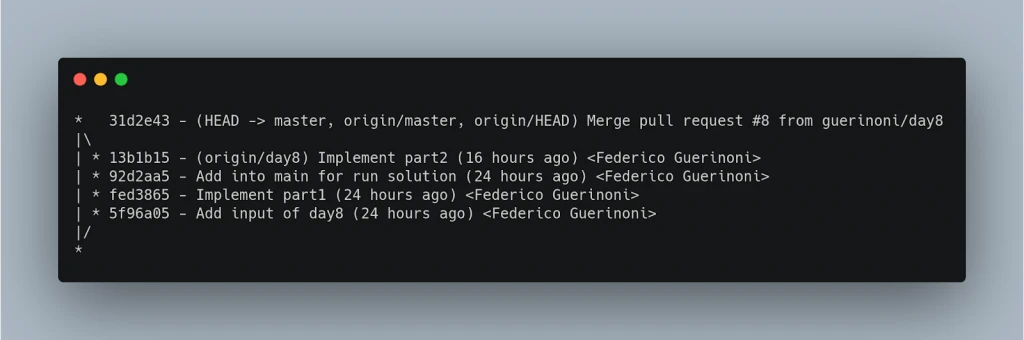
Nell’esempio sopra potete vedere come un ramo separato sarà unito al default, in questo caso il default è master. Con questa strategia si possono vedere dal log (e dal grafico) quali commit fanno parte del ramo master e quali fanno parte di quella funzione, questo permette di scrivere un messaggio di commit con meno dettagli perché il contesto del dominio è già coperto da quel ramo che è stato integrato. Nell’esempio seguente si può vedere che i commit sono meno precisi perché fanno parte del ramo “day8” che detiene il contesto di dominio di questa funzionalità inserita. Questo non è inteso come un incitamento a scrivere un commit superficiale ma in questo caso si possono evitare troppi dettagli.
L’immagine seguente mostra come sarà la storia dopo una strategia di rebase e merge, si può ottenere questa storia lineare anche con il merge fast-forward ma non andrò a fondo in questa differenza.
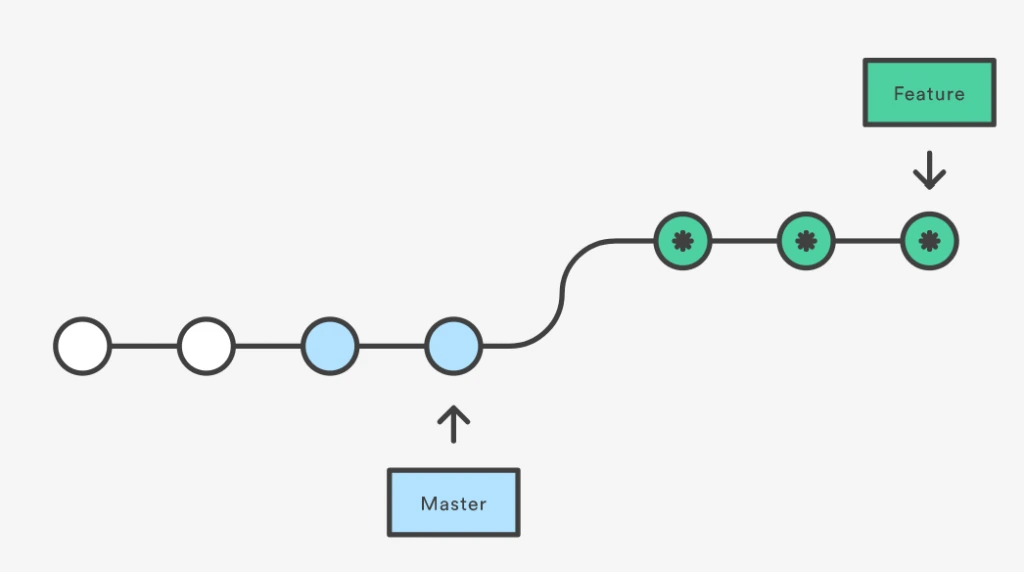
Qui tutti i commit del ramo separato per quello sviluppo sono dopo l’ultimo commit del master, quindi quando vai alla storia puoi vedere qualcosa come questo.
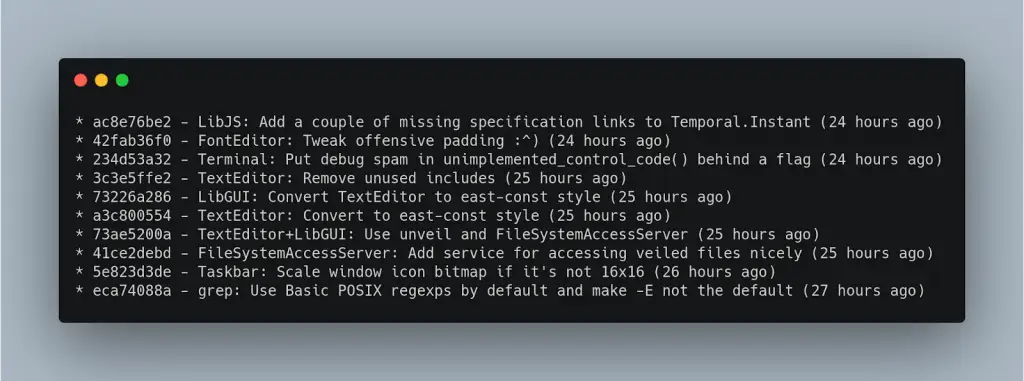
In questo caso non si riesce a notare una separazione netta di una funzionalità dall’altra perché la storia è lineare, qui si deve scrivere un messaggio di commit perfetto, perché dovresti dare un contesto dei cambiamenti e una piccola spiegazione nel corpo del commit. Usare questo tipo di flusso di lavoro significa che ogni commit rappresenta anche una sorta di documentazione per altre persone che leggeranno il codice in futuro ed esploreranno la storia.
Code review
Un altro passo durante lo sviluppo è chiamato revisione del codice (code review). Questo processo consiste nel presentare una richiesta agli altri membri del team per rivedere le modifiche per una specifica funzione/sistemazione che si vuole introdurre. Non mi concentrerò su come fare una revisione del codice, ma di solito il resto del team controllerà:
- che il nuovo codice funzioni come atteso per quella funzionalità
- che non venga manomesso il funzionamento del resto del codice
- lo stile del codice
- eventuali problemi di performance
- documentazione
Forse si potrebbero controllare molte altre cose, ma questi cinque sono i requisiti minimi per accettare una feature nel ramo di default. Allora come si fa a rivedere il codice? Ci sono principalmente due opzioni, tutti i cambiamenti insieme o commit per commit.
Ovviamente ogni sviluppatore può usare il metodo che ritiene migliore, ma se ci sono molti cambiamenti di linea vi suggerisco di seguire passo dopo passo ogni commit, perché ogni commit dovrebbe avere solo una responsabilità e si può vedere l’oggetto e il corpo di quel commit per una migliore comprensione.
Voglio sottolineare quanto sia importante scrivere un buon commit con singoli cambiamenti per questa fase perché gli altri sviluppatori possono risparmiare molto tempo con un buon lavoro sulla storia di git. Si può anche dedurre quanto sia importante fare una piccola PR con poche modifiche perché lo sforzo di rivedere il codice degli altri è enorme.
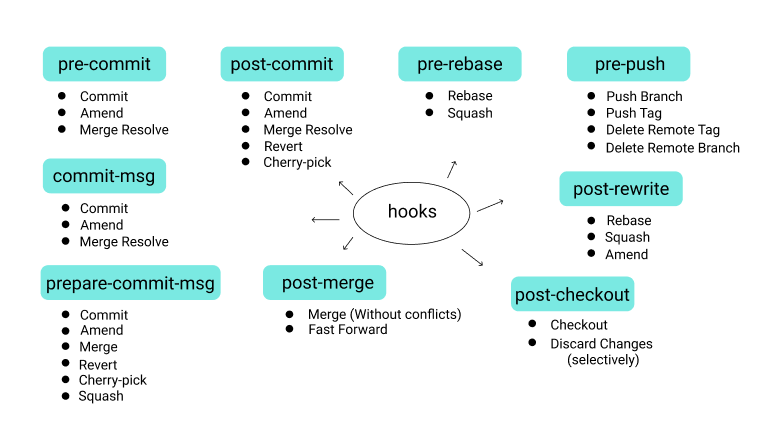
Hook
Gli hooks di Git risiedono sotto la cartella .git del tuo repo in una cartella chiamata hooks. Il percorso degli hooks sarà simile a repo/.git/hooks. Sono scripts personalizzati che git esegue prima o dopo eventi come commit, push, e sono una caratteristica integrata, non c’è bisogno di scaricare nulla.
Esempi di utilizzo degli hooks:
- Controllo del commit prima di effettuare un push
- Si assicurano che il codice rispetti gli standard del progetto
- Notifica al team di una modifica avvenuta
- Push del codice dentro un ambiente di produzione o test
Ci sono due diversi tipi di hooks, lato client e lato server. Come potete immaginare questo design incide sui diversi scopi di controllo o notifica o altre operazioni. Nelle immagini seguenti una mappa completa dei tipi di hooks.
Ok, ora mostrerò un semplice esempio di hook per il pre-commit scritto in bash, questo script controllerà il vostro messaggio di un commit (commit-msg) e avviserà se il vostro corpo non corrisponde alle regole, in questo caso deve contenere una di queste parole chiave “Add: |Created: |Fix: |Update: |Rework:”.
#!/bin/bash
Color_Off='\033[0m'
BRed="\033[1;31m" # Red
BGreen="\033[1;32m" # Green
BYellow="\033[1;33m" # Yellow
BBlue="\033[1;34m" # Blue
MSG_FILE=$1
FILE_CONTENT="$(cat $MSG_FILE)"
# Initialize constants here
export REGEX='(Add: |Created: |Fix: |Update: |Rework: )'
export ERROR_MSG="Commit message format must match regex \"${REGEX}\""
if [[ $FILE_CONTENT =~ $REGEX ]]; then
printf "${BGreen}Good commit!${Color_Off}"
else
printf "${BRed}Bad commit ${BBlue}\"$FILE_CONTENT\"\n"
printf "${BYellow}$ERROR_MSG\n"
printf "commit-msg hook failed (add --no-verify to bypass)\n"
exit 1
fi
exit 0
Questo è uno strumento integrato molto importante che ti aiuta a mantenere coerente il tuo codice e la tua storia di git, perché puoi anche eseguire altri scripts sulla tua base di codice per la formattazione secondo uno stile o altri controlli personalizzati.
Molti servizi di hosting git come GitHub, Gerrit, GitLab possono offrire il loro strumento per introdurre alcuni hook di commit lato server per la notifica o altre operazioni come l’esecuzione di test o il deploy.
Convenzioni e casi d’uso
Qui voglio mostrare alcune convenzioni generali utilizzate in diversi tipi di repository, si potrebbe scegliere da questa lista di consigli le proprie preferenze specifiche in base alle proprie esigenze.
Commit convenzionali (https://www.conventionalcommits.org/en/v1.0.0/)
Questo è un insieme di regole seguite per esempio dal progetto Angular che descrive come si dovrebbe scrivere un commit in ogni situazione. Qui il modello è:
- <tipologia di operazione>[campo di visibilità]: descrizione
- corpo del testo opzionale
- footer opzionale
Questo copre molte situazioni standard come feature, bugfix, revert un commit o rilasciare una versione con un tag specifico.
Ecco un esempio di un commit:

Bonus: https://github.com/carloscuesta/gitmoji-cli questo è uno strumento molto bello che ti aiuta a impegnarti dal tuo terminale con alcuni modelli già integrati.
Qt Project
Ora guardiamo le regole del codice sorgente di Qt, qui potete trovare una descrizione dettagliata su come contribuire al loro repository e c’è una pagina sulla commit policy (https://wiki.qt.io/Commit_Policy) che parla delle regole per creare un ramo, con il suo nome, e come scrivere un commit in Qt. Qui tutti i commit seguono:
- un template (https://code.qt.io/cgit/qt/qt5.git/tree/.commit-template) che prepara ogni messaggio di commit con la struttura specificata nel file
- soggetto: titolo
- descrizione nel corpo del commit
- uno script che genera automaticamente un change-ID, questo necessita di una inizializzazione con script di perl
- i footer pagina sono per lo più riempiti da gerrit con “Reviewed-by”, che tiene traccia dei revisori di quel commit fuso in master.
Qt usa gerrit come strumento per gestire il repository e la revisione del codice e questo modello segue l’esempio4 del capitolo “Git flow”, quindi ogni commit contiene un singolo cambiamento e sarà rivisto atomicamente. (c’è un metodo che permette di collegare molti commit tra loro, ma non è il caso comune che trovate qui).
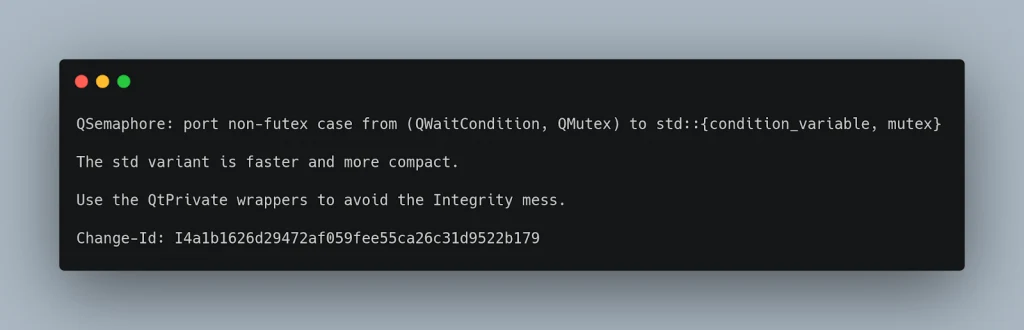
SerenityOS
Questo è un sistema operativo open source ospitato su Github, il suo modello di flusso git è basato sull’invio di un PR che implementa o corregge una singola cosa, ma è permesso inviare più di un commit. Questo perché per quella caratteristica si può anche migliorare un’altra parte del progetto e quella parte dovrebbe rimanere in un commit dedicato.
Qui c’è una sola regola: soggetto + titolo e dettagli nel corpo, di solito il soggetto è anche il campo/scope del progetto ed è facile trovare cosa scrivere nel commit.
Viene incoraggiato fortemente l’impostazione del hook pre-commit perché il progetto fornisce già scripts che controllano il tuo codice. (https://github.com/SerenityOS/serenity/blob/master/.pre-commit-config.yaml)
Questo perché la strategia di merge usata per ogni PR è di unire con fast forward, simile a rebase e merge, quindi il risultato sarà una perfetta storia lineare e pulita. Molto bello guardare dentro ogni cambiamento.
Esempio di commit in serenityOs:
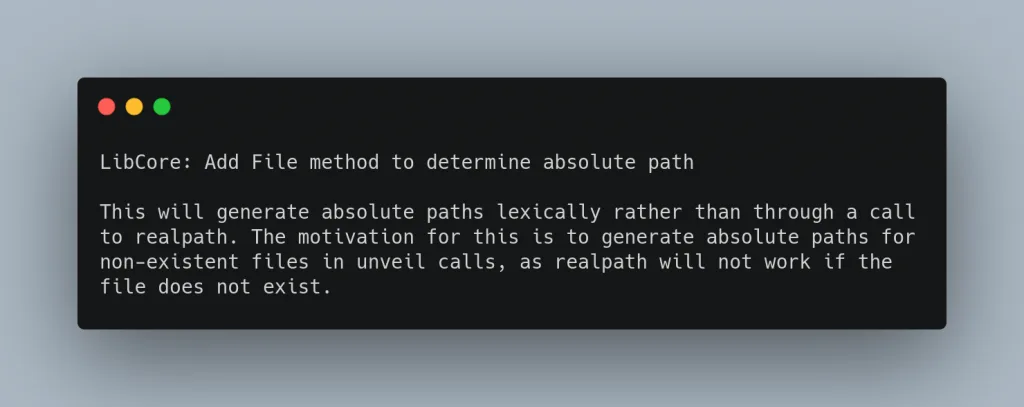
Linux Kernel
Nel kernel linux ogni commit sarà inviato utilizzando i servizi di posta di git, quindi è necessario scegliere la mail giusta in base all’oggetto (dipende da che parte del kernel) che avete cambiato. C’è anche uno script che vi fornisce l’attuale manutentore di quella parte di codice, questo per il cc-ing della vostra patch. Dal momento che la revisione e l’invio avvengono solo tramite posta, devi descrivere molto bene la tua patch perché la storia è lineare e devi fornire un buon commit anche per le persone future che guardano quel codice (e la storia).
In questo repository dovete fare il commit del vostro codice con la firma (git commit -s), è usata per dire che voi certificate di aver creato la patch in questione, o che voi certificate che, al meglio delle vostre conoscenze, è stata creata sotto una appropriata licenza open-source, o che vi è stata fornita da qualcun altro sotto quei termini. Questo può aiutare a stabilire una catena di persone che si assumono la responsabilità dello stato del copyright del codice in questione, per aiutare a garantire che il codice protetto da copyright non rilasciato sotto un’appropriata licenza di software libero (open source) non sia incluso nel kernel.
Ci sono anche molte regole su altri footer di pagina come “Reported-by:, Tested-by:, Reviewed-by:, Suggested-by: e Fixes” o “Acked-by:, Cc:, e Co-Developed-by”, piè di pagina molto bello per tenere traccia di tutto solo in base al repository.
Nell’immagine seguente c’è un esempio di un commit nel kernel linux, molto ben documentato e utile da leggere:
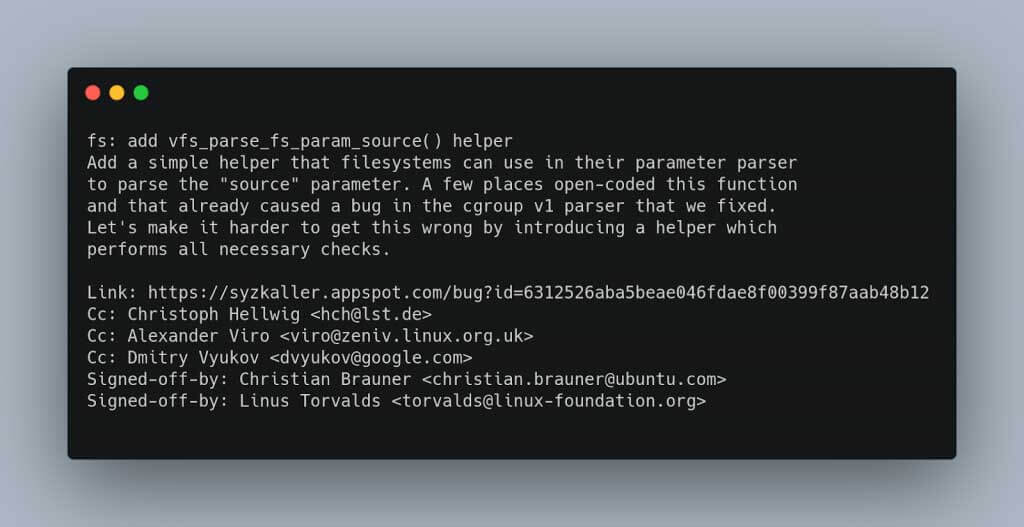
Go (Golang)
Anche il linguaggio di programmazione di Google utilizza lo strumento gerrit per la revisione del codice e segue lo stesso modello di linux, singolo commit, singolo cambiamento sarà unito senza presentare un PR.
Qui troverete tutte le regole per contribuire al linguaggio, https://golang.org/doc/contribute#mail, prima di iniziare a contribuire dovrete impostare uno strumento chiamato git-codereview, utilizzato per controllare il vostro commit nella posizione HEAD del ramo corrente. Il commit dovrebbe seguire queste regole:
- La prima riga della descrizione della modifica è convenzionalmente un breve riassunto di una riga del cambiamento, preceduto dal principale pacchetto interessato
- Una regola generale è che dovrebbe essere scritto in modo da completare la frase “Questo cambiamento modifica Go per _____.” Ciò significa che non inizia con una lettera maiuscola, non è una frase completa, e riassume effettivamente il risultato del cambiamento.
- Il riferimento al ticket che si sta risolvendo/implementando
Ci sono anche altre regole sulla revisione e sui commenti, ma preferisco saltare questa parte perché non è l’argomento centrale.
Nell’immagine seguente un esempio di commit nel repository Go:
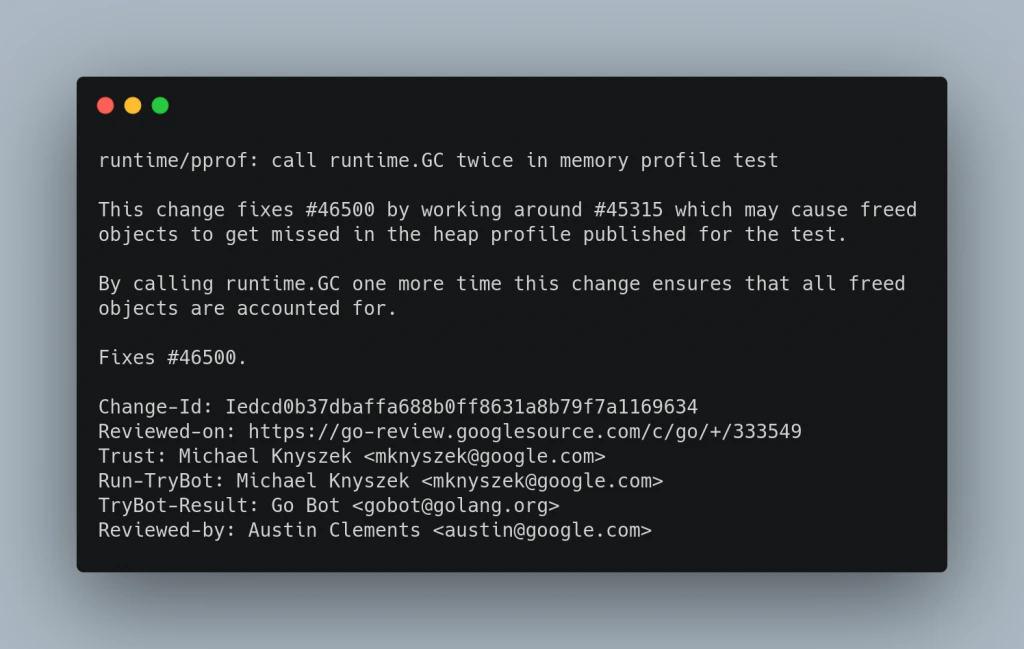
Conclusioni
Come potete vedere ci sono molti aspetti da considerare prima di scegliere un set di regole per il flusso, i commit, gli hook e che strumenti utilizzare. È probabile che gli strumenti cambino frequentemente, quelli che uso più spesso al momento in cui scrivo sono:
- GitHub come servizio di hosting
- GitHub Action per continuous integration e deploy
- Git alias | Atlassian git tutorial
- Mantenere la conoscenza il più possibile nel commit git o nel codice perché non dipendono dai vostri strumenti extra o dalle caratteristiche dell’hosting git
Nei repository non popolari/grandi è molto difficile vedere quest’ultima regola, forse perché non c’è bisogno di scavare nella storia o forse la documentazione è privata e vengono usati altri strumenti.
Ora avete tutte le informazioni per scegliere la vostra strategia per il vostro team e progetto, vi lascio con alcuni suggerimenti:
- Se il vostro progetto è un progetto open-source, con un lungo supporto e forse più collaboratori il modo migliore è quello di mantenere la storia super pulita con pochi PR o usando gerrit per il merging di un commit alla volta.
- Se state lavorando su un progetto che richiede caratteristiche che impattano una grande quantità di codice e il merging ha senso solo alla fine dell’intero lavoro potreste prendere il flusso di feature-branch senza una storia lineare tenendo traccia dei commit di merging.
- Se il progetto è molto grande, suggerisco di dividere il lavoro in molti commit diversi perché un singolo merge può introdurre cambiamenti all’interno di una parte del progetto che non è l’obiettivo principale della PR in questione.
Tutti questi consigli funzionano bene per qualsiasi dimensione del team, anche se stai lavorando da solo, perché puoi vedere la qualità del progetto anche dal commit log 🙂