Leggere un encoder motore da Linux
Introduzione
In un progetto Develer a cui ho lavorato si è manifestata la necessità di interfacciarsi con un motore asincrono trifase. Questo tipo di motore è caratterizzato dalla suddivisione della propria rotazione in un numero finito di passi. Quindi la rotazione del motore può essere determinata leggendo il valore del passo corrente.
La scheda che ho utilizzato per il progetto è una Develboard, quindi un SoC SAMA5D44, processore ARMv7 a 600 MHz, con sistema operativo GNU/Linux. Questa architettura è, in particolare, fornita di una periferica hardware chiamata Timer Counter, la quale permette la configurazione in modalità decoder in quadratura, al fine di leggere la posizione corrente del motore.
Segnali in quadratura
Un motore encoder fornisce dei segnali in quadratura per codificare la rotazione e la direzione. Questi due segnali sono chiamati A e B, e sono caratterizzati da due onde quadre sfasate di 90 gradi tra di loro. Spesso questo comportamento si può ottenere con un disco opportunamente creato con un pattern di parti opache e trasparenti:

La posizione di rotazione può essere misurata contando i fronti delle due forme d’onda, invece la fase tra le due determina la direzione di rotazione.
Nella figura seguente, i segnali A e B rappresentano i segnali in quadratura, che danno luogo a 4 stati in totale, mentre il segnale Z è utilizzato per il posizionamento assoluto e indica una rivoluzione completa del motore:
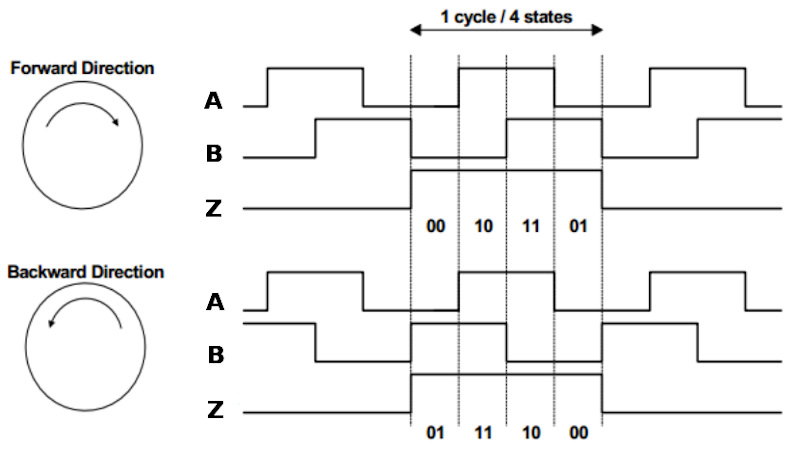
Il segnale Z può rimanere ad un livello alto per un massimo di 4 stati e, se questo avviene, allora uno qualsiasi dei 4 stati può essere riconosciuto come quello in cui il giro è stato completato. Lo scostamento iniziale di rotazione non può essere conosciuto, tuttavia la posizione assoluta del motore può essere calcolata prendendo in considerazione il segnale Z, che fornisce un riferimento spaziale preciso.
Periferica Timer Counter
La periferica hardware Timer Counter permette la decodifica dei segnali in quadratura, fornendo due registri hardware che potenzialmente possono misurare la posizione, il numero di rotazioni e la velocità del motore. Tuttavia, queste 3 informazioni non possono essere calcolate contemporaneamente, ma si può scegliere tra posizione/rotazione oppure velocità/rotazione. In questo articolo, la periferica è stata programmata al fine di leggere la rotazione e quindi determinare la posizione assoluta del motore. Invece, la velocità sarà calcolata in software partendo dai dati di posizione.
La figura seguente mostra il diagramma a blocchi di Timer Counter. Internamente è diviso in 3 blocchi (channel) che contengono alcuni registri, tra cui quello del contatore.
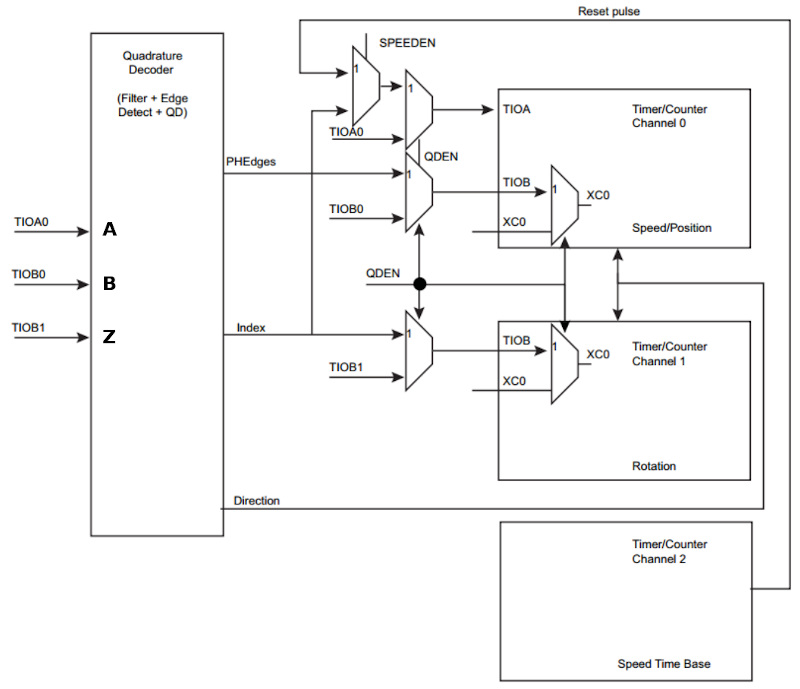
Il blocco 0 contiene il contatore per calcolare la posizione o velocità (CV0). Il blocco 1 contiene il contatore per calcolare la rotazione del motore (CV1). Infine, il blocco 2 serve per fornire un riferimento temporale nel caso si voglia effettuare il calcolo di velocità. Nonostante la periferica non sia stata programmata per misurare la velocità, il blocco 2 viene comunque usato per i timer ad alta risoluzione del kernel, quindi è occupato per espletare questa funzionalità.
I contatori CV0 e CV1 (a 32 bit) sono incrementati automaticamente dal Timer Counter, in base all’analisi dei segnali A e B. In particolare, quando il motore ruota in avanti, essi incrementano il proprio valore. Al contrario, quando il motore ruota in direzione opposta, essi saranno automaticamente decrementati. Quindi la posizione relativa rimane sincronizzata al trasporto, anche se il motore avesse un cambio di rotazione, oppure un gioco dovuto alle parti meccaniche collegate.
Al fine del calcolo della posizione, il registro CV0 conta i passi encoder del motore, invece il registro CV1 conta il numero delle sue rotazioni. Combinando insieme queste due informazioni, si può ottenere la posizione assoluta del motore.
La seguente figura mostra la rilevazione del cambio di direzione analizzando i segnali A e B. In particolare, il cambio di direzione viene segnalato non appena sono rilevati due fronti consecutivi del segnale sfasato B.
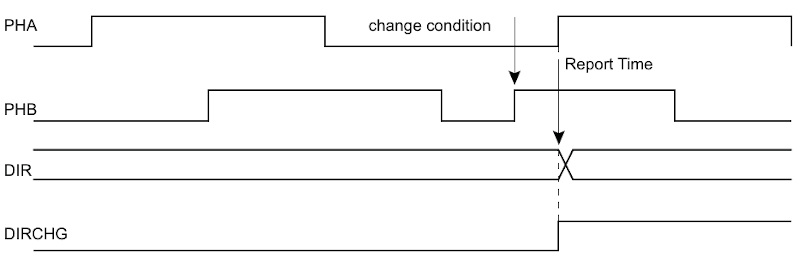
I contatori hardware sono registri a 32 bit, quindi si verificherà overflow in condizioni di utilizzo normali, cioè quando il motore ruota nel senso di direzione di lavoro. Ci possono anche essere dei casi in cui si verifica underflow se il motore ruota in senso contrario, quando essi assumono un valore prossimo allo zero. Un driver di lettura dovrà gestire queste situazioni di overflow o underflow.
Come leggere la posizione del motore
Al fine di realizzare un driver che funzioni correttamente, dobbiamo tenere in considerazione alcuni parametri fondamentali del motore. Un parametro fisico importante è il numero di passi che formano una rotazione completa. Inoltre, la periferica Timer Counter conta sempre tutti i fronti dei segnali A e B, perciò dobbiamo anche considerare un moltiplicatore, che solitamente è 4. Quindi, nel caso un motore abbia fisicamente 2000 passi per giro ed entrambi i segnali in quadratura, ci aspettiamo di leggere 8000 fronti per giro motore.
Il numero di fronti totali per giro è da considerarsi anche in funzione del metodo di lettura che intendiamo utilizzare. Infatti, in un sistema Linux, possiamo seguire principalmente due approcci per la lettura della posizione:
- Interrupt su ogni fronte dei segnali in quadratura:
- Si configurano un interrupt ed una routine di gestione nel driver. In tale routine, si incrementa poi un contatore interno ogni volta che scatta un interrupt.
- La funzione di lettura restituisce sempre l’ultima posizione.
- Lettura posizione in busy wait.
- Si implementa nel driver una lettura bloccante in busy wait, che accede ai registri CV0 e CV1 su richiesta.
- La lettura sarà sincronizzata al prossimo nuovo passo encoder in rotazione, oppure restituisce l’ultima posizione.
Ma come mai è innanzitutto utile distinguere tra questi due approcci? Non si potrebbe semplicemente accedere ai registri CV0 e CV1, al fine di recuperare in ogni momento la posizione corrente, senza attesa in busy wait? La risposta può essere affermativa, ma dipende dalla necessità o meno di avere una marcatura temporale, associata al passo encoder. La marcatura temporale è però fondamentale se, ad esempio, vogliamo calcolare la velocità del motore. Essa deve essere associata all’inizio di un passo encoder, nel modo più preciso possibile.
Entrambi gli approcci presentano vantaggi e svantaggi; però possiamo dire che, in caso di motori ad alta risoluzione, il numero di fronti può essere elevato. Di conseguenza anche il carico di interrupt potrebbe essere impegnativo. Quindi una lettura basata su interrupt è più generica e si adatta spesso a situazioni multiple. Invece, una lettura di tipo busy wait può essere utile in contesti più specifici, dove conosciamo bene quali sono i tempi e le prestazioni hardware/software del sistema, ma più complicata.
Ci sono delle differenze anche riguardo la marcatura temporale. Nel caso dell’approccio basato su interrupt, il timestamp dipende dalla latenza degli interrupt di sistema, che solitamente è dell’ordine di microsecondi, ma può essere anche maggiore a seconda del carico di sistema. Invece, il metodo busy wait risulta essere più preciso, ma come svantaggio utilizza più CPU durante la lettura.
Lettura sincronizzata al passo encoder
Entrambi gli approcci descritti in precedenza si basano principalmente sui due aspetti: lettura del passo encoder corrente e diagnostica tramite segnale di rotazione Z. Inoltre, in entrambi i casi, il driver determina la posizione assoluta del motore combinando insieme i contatori di posizione relativa (CV0) e contatore di rotazione (CV1). Quest’ultima operazione comprende anche un meccanismo di compensazione sui passi encoder eventualmente persi, a causa di difetti del motore.
Lettura dei segnali A e B
Vediamo una possibile implementazione del metodo di lettura in busy-wait, dal momento che risulta essere più complicato. La lettura del passo encoder viene effettuata “on demand”, ovvero solo quando è davvero necessaria. Il metodo di lettura dell’impulso corrente è illustrato nelle figura seguente:
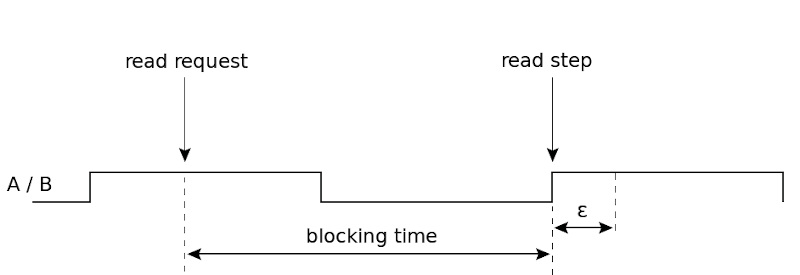
La richiesta di lettura può avvenire in qualsiasi momento. Siccome è necessario applicare un timestamp ad ogni passo encoder, associamo tale marcatura temporale all’istante di inizio di ogni impulso. Per questo motivo, ogni lettura impiega un po’ di tempo per essere espletata. In particolare, il processo chiamante sarà messo in attesa fino a che il primo fronte di salita del segnale in quadratura A viene rilevato. Ciò significa che l’attesa durerà fino a che il contatore di posizione CV0 non cambierà il proprio valore fino al prossimo multiplo di 4 (con un divisore pari a 4). Come esempio, se un encoder gira ad una velocità di 1666 passi/secondo, ogni passo encoder completo dura circa 600 us (4 impulsi da 150 us), che sarà anche il tempo massimo di attesa a regime. Se la velocità diminuisce, il tempo di attesa può aumentare, quindi in generale dovrà essere previsto un timeout per l’attesa.
La fase di attesa nella syscall read può essere espletata attraverso un loop attivo, che controlla il contatore CV0. Tuttavia è possibile avere un’imprecisione di lettura ε sulla marcatura temporale, data dal fatto che il sistema continua ad eseguire altre operazioni sotto interrupt, schedulare processi e così via. Perciò, al fine di considerare come valido un fronte dei segnali in quadratura, esso deve essere rilevato prontamente, limitando l’errore di timestamping. Questa imprecisione può essere quantificata in decine di microsecondi. La precisione della marcatura temporale ha impatto sul calcolo della velocità in passi encoder/secondo. Il driver quindi può anche calcolare l’entità della pausa (in termini di tempo) che c’è stata tra un polling ed il successivo.
Per evitare una lettura bloccante, possiamo utilizzare l’approccio basato su interrupt su ogni impulso. Tuttavia anche in questo caso, dovremmo comunque tenere in considerazione un’imprecisione di lettura. Infatti Linux non è un sistema operativo real-time, perciò anche gli interrupt possono essere soggetti ad una certa latenza, soprattutto quando il carico di sistema è elevato.
Lettura del segnale Z
Per entrambi gli approcci di implementazione, la lettura del segnale Z avviene sotto interrupt. Nel caso dell’approccio busy-wait, questo meccanismo serve anche ad aggiornare internamente il valore dei registri CV0 e CV1 al fine di gestire le situazioni di overflow quando si calcola la posizione assoluta.
Inoltre si possono anche mantenere alcune informazioni relative all’impulso zero, ad esempio la posizione del motore. In questo modo è possibile calcolare quanti passi encoder sono intercorsi tra un impulso Z ed il successivo, cioè il numero di passi encoder per giro. Questo valore è molto importante per la diagnostica del motore, perché in caso di corretto funzionamento ad ogni giro dovrà essere letto sempre lo stesso numero di passi encoder.
Infine, il segnale Z è utile in fase di avvio. Infatti il conteggio inizia sempre da un punto casuale, quindi il posizionamento assoluto non è immediatamente possibile. Di conseguenza, è importante iniziare a contare non appena viene ricevuto l’impulso di giro.
Confronto tra i due approcci
Ho eseguito delle prove su un sistema GNU/Linux reale, con un motore encoder avviato ad una velocità di circa 1666 step/secondo. Analizzando le acquisizioni dei dati di timestamp e posizione, possiamo confrontare i dati di velocità.
Interrupt
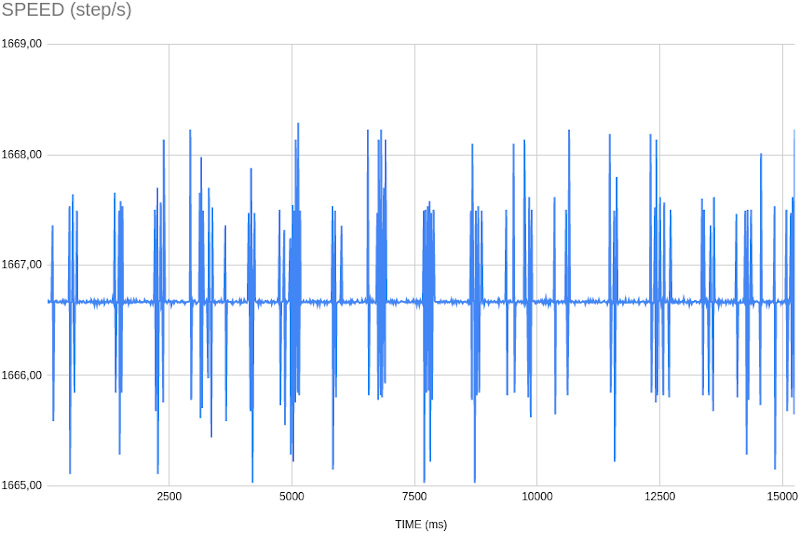
| AVG | MIN | MAX | STDDEV | 95% |
| 1666,68 | 1665,03 | 1668,29 | 0,43 | 1668 |
Busy wait
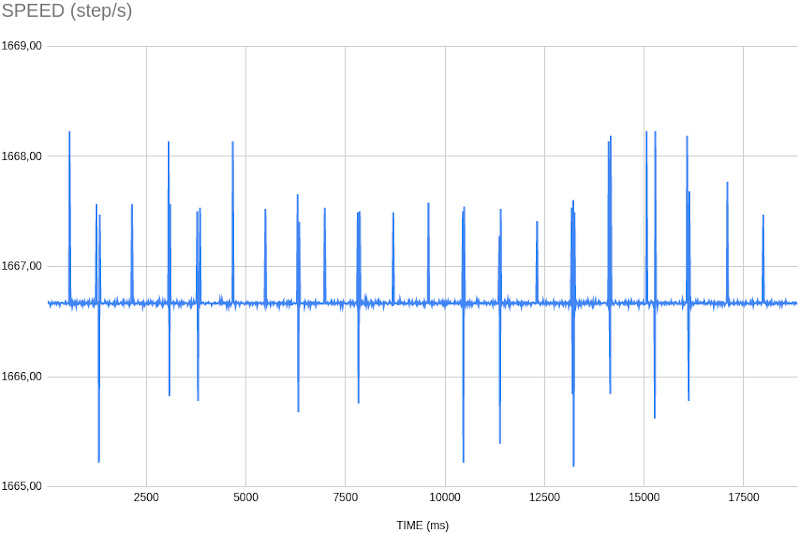
| AVG | MIN | MAX | STDDEV | 95% |
| 1666,69 | 1665,18 | 1668,23 | 0,22 | 1667 |
Possiamo notare come entrambi i metodi abbiano risultati simili, per quanto riguarda l’assegnazione del timestamp e quindi il calcolo della velocità istantanea. Il metodo busy-wait sembra ottenere un risultato forse più preciso per la velocità, osservando i valori di deviazione standard e percentile 95%.
Inoltre, in termini di prestazioni di sistema, senza nessun altro processo in esecuzione, non ci sono sostanziali differenze a livello di utilizzo di risorse di sistema.
Conclusioni
In questo articolo abbiamo visto due diversi approcci per rendere accessibile un motore stepper ad un sistema GNU/Linux. Entrambi i metodi hanno pregi e difetti che possiamo riassumere qui di seguito:
- Metodo Interrupt
- PROS
- La posizione del motore è sempre disponibile “istantaneamente”.
- La lettura non è bloccante.
- Implementazione semplice.
- Si adatta a situazioni più generiche.
- CONS
- Difficile gestire il caso di retromarcia.
- Difficile gestire la perdita di passi encoder.
- Alto carico di interrupt.
- Interruzioni a livello di sistema (possono interrompere altre operazioni).
- Precisione timestamp dipendente dalla latenza degli interrupt (non real-time).
- Metodo busy-wait
- PROS
- Non occupa risorse quando non si legge la posizione.
- Ha un solo interrupt configurato sul segnale Z.
- Più preciso nell’assegnazione del timestamp.
- È configurabile rispetto alla precisione che vogliamo ottenere.
- Possibile compensare passi encoder otturati.
- CONS
- Lettura bloccante.
- Euristiche per non usare troppa CPU su lettura a velocità bassa.
- Si deve impostare un timeout di lettura.
- Gestione della precisione per sincronizzazione col fronte di salita.
- Driver più complesso.
Per questo motivo, l’approccio basato su interrupt è il metodo da preferire quando si vuole realizzare un driver non troppo complesso e, solo successivamente, implementare una versione più complessa.