Pubblichiamo con piacere la traduzione di un articolo scritto dal nostro Lorenzo Savini, che parla di alcuni aspetti relativi alla parte di testing durante la nostra collaborazione con il cliente NextRoll.
In NextRoll, svariati team lavorano continuamente su differenti micro-frontend, i tanti piccoli mattoncini che compongono le dashboard e le altre sezioni del prodotto.
Nell’ottica di aiutare questi team a creare UI omogenee [e meravigliose], manteniamo già una libreria di UI components. Se ti interessa, trovi un approfondimento in questo blogpost.
Sempre sull’onda di questa filosofia incentrata sul DRY (don’t repeat yourself ndr) e la condivisione, abbiamo deciso di creare un tool per semplificare le operazioni di smoke testing delle nostre UI.
Un tool che doveva essere facilmente integrabile nel flow di sviluppo, in grado di funzionare sulle macchine del nostri engineer e sulle infrastrutture di CI che usiamo (Builkite e Jenkins2), e di interfacciarsi con i nostri sistemi di monitoring e gestione degli incidenti.
Smoke testing
Secondo Wikipedia gli smoke test sono test preliminari per rivelare semplici guasti abbastanza gravi da, ad esempio, rifiutare una futura versione del software.
Quindi, innanzitutto, dovevamo definire il tipo di test che volevamo eseguire con questo tool.
Il nostro obiettivo era di eseguire test semplici per rilevare fallimenti gravi al punto da degradare l’esperienza utente sulla piattaforma. Tra questi fallimenti gravi, possiamo trovare UI totalmente incapaci di caricare o sezioni business-critical non funzionanti (come la creazione di una nuova campagna pubblicitaria, ad esempio).
Chiaramente, utilizzavamo già altre modalità per assicurare il buon funzionamento dei servizi:
- Test unitari e funzionali del codice, e anche qualche test end-to-end abbastanza complesso.
- Test delle API HTTP per garantire sia la loro compatibilità, anche a seguito di aggiornamenti, che il loro funzionamento.
- Monitoraggio dei vari layer dell’infrastruttura, dal carico del database alla frequenza di errori delle API HTTP.
Ciascuno di questi metodi era già stato fondamentale nel rilevare difetti in produzione o nel prevenire il deploy di aggiornamenti problematici. Dall’altro lato, questi metodi erano responsabili nel testare o monitorare specifiche parti del sistema, senza guardare al quadro più ampio
Uno degli aspetti critici delle UI complesse è il numero di API HTTP utilizzate, e il fatto che questo set di dipendenze tende a crescere col tempo. Inoltre, alcune sezioni della UI potrebbero utilizzare altre API HTTP oppure qualcuno potrebbe attivare nuove feature tramite l’uso di feature flags (e magari aggiungere altre chiamate ad API HTTP).
A un certo punto, tenere traccia dell’impatto del deploy di un servizio backend diventa quasi impossibile.
Certo, il rischio di problemi causati dal rilascio di modifiche alle API HTTP utilizzate dovrebbe già essere minimo, grazie agli accordi che l’interfaccia dovrebbe comunque continuare a garantire (che starete già testando). In tutti i casi, avere ridondanza anche a livello di test può essere considerata una buona pratica, dato che spesso non è possibile
scoprire tutti i tipi di criticità con un tipo di test soltanto.
Trovare il framework per le nostre necessità
Come primo passo, dovevamo scegliere il framework di UI testing più in linea con i nostri obiettivi.
Volevamo un framework che non richiedesse l’apprendimento di nuovi linguaggi o con API complesse, possibilmente basato su tecnologie e librerie già familiari per noi. Un framework stabile e affidabile, con la possibilità di registrare l’esecuzione dei test per poterla rivedere in seguito.
Molti di noi avevano già avuto esperienze con Selenium e con lo sforzo richiesto a mantenere test fatti con questo tool e a garantire la loro stabilità nel tempo.
Oltretutto, avevamo già provato anche servizi come New Relic Synthetics e il prodotto concorrente creato da DataDog. Sicuramente risultavano molto più stabili di un test scritto in Selenium ed erano pure corredati di feature interessanti. Dall’altro lato, non eravamo particolarmente contenti di scrivere i test utilizzando gli editor presenti sulle loro UI web, senza alcuna possibilità di salvare il codice dei test all’interno delle nostre repository Git.
Questi aspetti rendevano più complessi i deploy, dato che dovevamo modificare manualmente i test tramite il loro editor. Dopo questa esperienza, abbiamo capito che, per semplificare le operazioni intorno a un deploy ed evitare grattacapi inutili, dovevamo utilizzare il nostro sistema di versionamento anche per il codice dei test e avere la possibilità di aggiornare automaticamente la suite di test a ogni deploy.
Dopo un po’ di analisi, abbiamo finalmente trovato il candidato vincente: Cypress!
Cypress.io
Cypress è un framework open-source, per test end-to-end. Lo puoi trovare nel sito Cypress.
Ha una brillante architettura che non si basa su Selenium: Cypress viene eseguito dallo stesso loop della tua applicazione. Questo approccio permette un accesso diretto al DOM, alla window, alla tua UI, oltre a dare la possibilità di intercettare richieste HTTP e connettere Cypress allo store Redux della propria applicazione.
In questa pagina puoi trovare maggiori informazioni in merito al funzionamento di Cypress.
Cypress permette di scrivere test in JavaScript oppure TypeScript, e fornisce alcune delle più famose librerie per testing frontend, come Mocha, Chai e Sinon.
Un’altra funzionalità particolarmente utile per il nostro obiettivo è il supporto ai Mocha reporters, che permette di utilizzare reporters come Mochawesome in maniera molto semplice:
{
"reporter": "mochawesome",
"reporterOptions": {
"reportDir": "output/reports",
"overwrite": false,
"html": false,
"json": true
}(estratto del nostro file cypress.json)
La ciliegina sulla torta, però, è la capacità di Cypress di registrare automaticamente l’esecuzione di ciascun test e generare file MP4 che possono essere riprodotti in qualunque momento.
Scrivere un test
Le API di Cypress sono molto intuitive. Ad esempio, non dovresti neanche aver bisogno di studiare la sua documentazione per capire questo test:
describe("An example", () => {
before(() => {
// Here you can setup your tests.
// As example, you could log in to your application.
prepareYourTest();
});
it("Should load", () => {
cy.visit(
`${Cypress.env('HOST')}/test-url`
);
// After .visit(), we want to check if the next page H1
// contains "Hi!".
// As you can see, we don't need to wait for
// the page to be ready, this is on Cypress which
// will automatically wait for your H1 to be visible
// (or, if your H1 doesn't appear, it will fail after a timeout).
cy.get("h1").should("contain", "Hi!");
// Let's also confirm that we are on the right URL.
cy.url().should("include", "test-url");
// Now, let's find an entry on our navbar,
// and let's click on it.
cy.get("div.main-navbar")
.contains("Section 1")
.click();
// Here too, we don't need to write code to
// wait for our application to be
// ready: Cypress will take care of it.
cy.get("di
v.main-page>h2").should(
"contain",
"It works!"
);
});});Visto? Nessun comando per attendere il caricamento della pagina o di specifici componenti
Distribuire il tool ai vari team
Chiaramente, trovare il framework giusto non era che l’inizio del nostro percorso. Distribuirlo a svariati team significava anche rendere il setup più facile possibile, astraendo alcune complessità di Cypress.
One Docker image to rule them all
Abbiamo deciso di distribuire il tool tramite una immagine Docker, così da nascondere parte dell’installazione e del setup di Cypress.
La nostra immagine sfrutta una delle immagini ufficiali per Cypress, cypress/browsers:node12.19.0-chrome86-ff82. Qui puoi trovare tutte le immagini Docker mantenute direttamente dal team Cypress: https://github.com/cypress-io/cypress-docker-images
Adesso, diamo un sguardo al lifecycle dell’esecuzione di un test:
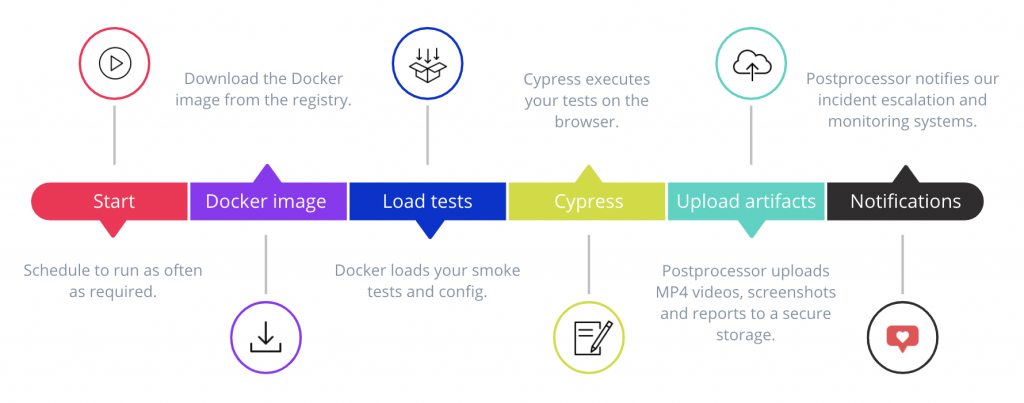
Questo approccio richiede ai team un piccolo boilerplate:
- Un Dockerfile, per utilizzare la nostra immagine e copiare i test all’interno del container;
- 2 docker-compose.yml, uno per la macchina di sviluppo e l’altro per l’infrastruttura di CI (le maggiori differenze tra i 2 file sono dovute alla presenza di ipc:host e un volume nel docker-compose pensato per l’uso sulle macchine di sviluppo)
- Un JSON file che contiene la configurazione del progetto, che può cambiare a seconda dell’environment di esecuzione – per permettere, tra le altre cose, di modificare l’host soggetto ai test o le politiche di escalation di un incidente (per evitare un page di notte se l’errore avviene durante i test su Staging, ad esempio).
- I file contenenti i test stessi.
Questo approccio permette di ottenere facilmente alcuni dei benefici a cui puntavamo all’inizio: il codice dei test è all’interno della stessa repository che contiene il codice dell’applicazione, versionato, e la nostra CI può facilmente utilizzare la versione dei test corretta per l’environment del caso.
Un altro beneficio è dato dalla capacità di estendere l’immagine Docker con facilità, copiando altri file nei percorsi giusti del nostro container. Questo permette ai vari team di sperimentare plugin e task prima di aggiungerli direttamente all’immagine base.
Test utilities
Per ridurre ulteriormente la ridondanza di codice tra le varie installazioni del nostro tool, abbiamo anche pubblicato un pacchetto NPM sul nostro registro privato. Il pacchetto, scritto in TypeScript, fornisce i typings di Cypress e alcune utility per i test, come i metodi per eseguire il login in automatico, integrati con il keyring standard per evitare password in chiaro.
Monitoraggio e gestione degli incidenti
Un tool di smoke testing non integrato con i servizi che utilizziamo tutti i giorni sarebbe stato piuttosto inutile.
Per questo motivo, abbiamo usato Mochawesome per generare dei report file e scritto un piccolo script Python per post-processare i risultati dei test:
- Fare upload dei vari screenshot e video generati da Cypress sul nostro storage;
- Emettere metriche a DataDog (rappresentando la durata dei test e il loro risultato);
- Avviare, se necessario, un’incident escalation tramite PagerDuty;
- Inviare un messaggio Slack:
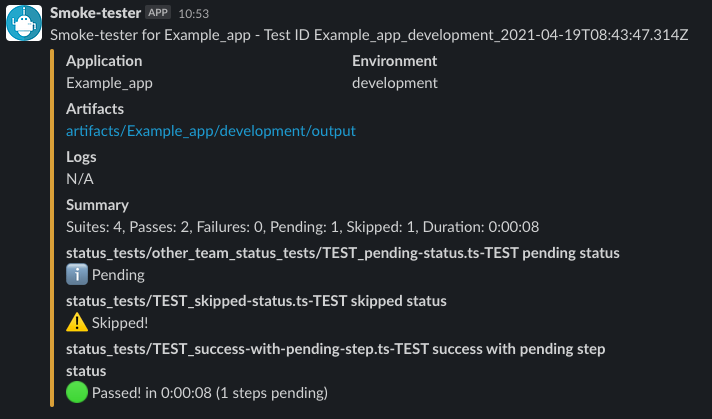
Monitorare lo stesso Smoke test
Come ogni servizio critico ospitato dalla propria infrastruttura, anche lo Smoke tester stesso è soggetto a monitoraggio, per garantire un costante test delle nostre UI, tramite DataDog.
Ridurre il rumore
Per noi, uno degli aspetti più importanti di questo tool è l’affidabilità delle notifiche, prevenendo falsi allarmi che potrebbero ridurre la fiducia dei team nei confronti del tool stesso.
Uno dei metodi più semplici che abbiamo applicato è ovviamente il retry automatico dei test.
Un altro tipo di rumore che abbiamo cercato di ridurre è quello causato da fallimenti dovuti ad altri team, per i quali sarebbe inutile la nostra presenza online, magari alle 2 di notte.
Questo avviene spesso in caso di architetture a microservizi gestiti da vari team, e ancora più spesso quando un servizio ha un ownership multipla (nel nostro caso, ogni applicazione ha un owner principale, ma possono esserci sezioni specifiche gestite da altri team).
Per ridurre le probabilità di ricevere una chiamata notturna da PagerDuty, abbiamo deciso di implementare un modello gerarchico che previene l’escalation di un incidente ai figli di un nodo fallito.
Gerarchia dei test
Vediamo adesso un esempio che spiega come funziona il modello gerarchico per la gestione degli incidenti.
Prendiamo un’applicazione con la seguente ownership condivisa:
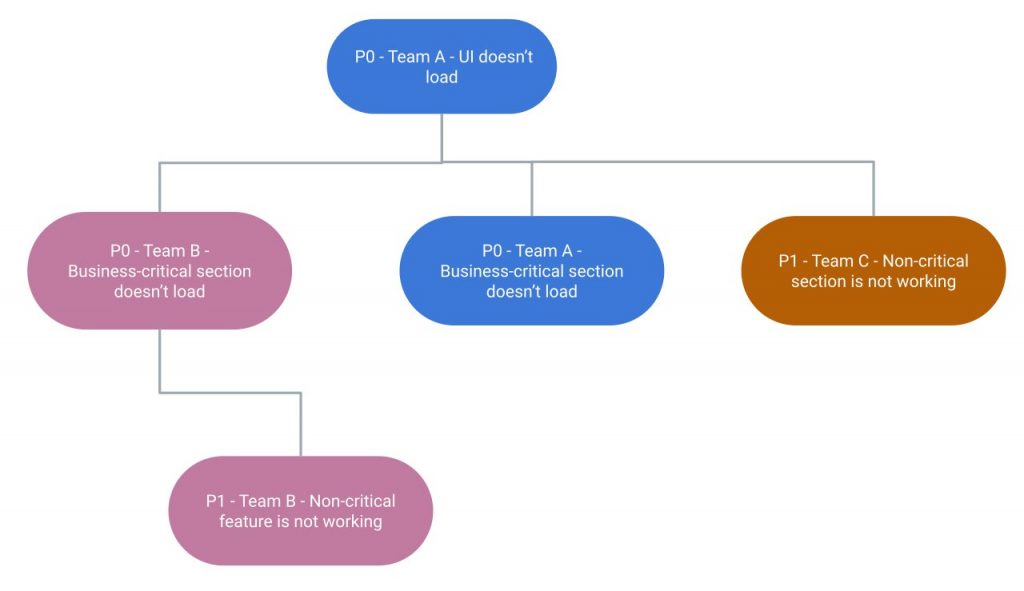
Come si può vedere, abbiamo 3 team:
- Team A, owner principale dell’app e responsabile di ogni incidente grave al punto da impedire il caricamento dell’applicazione (come, ad esempio, un fallimento infrastrutturale)
- Team B e C, responsabili di diverse sotto-sezioni delle applicazioni, critiche e non.
Ipotizziamo un fallimento infrastrutturale, con conseguente fallimento nel caricare l’intera UI:
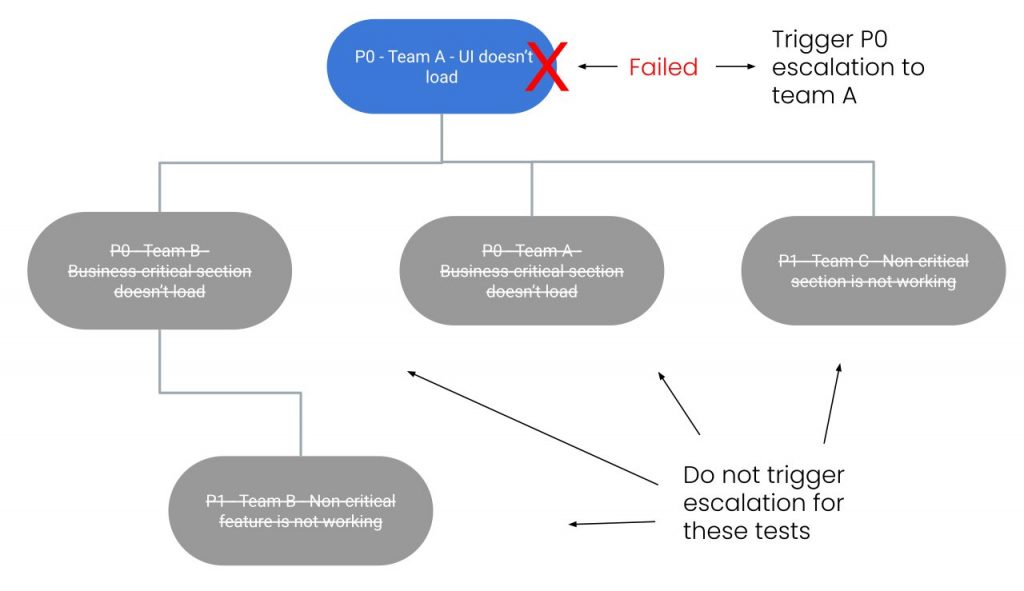
Dato che il test principale è fallito, il team A verrà allertato mentre i team B e C potranno continuare a dormire tranquilli.
Case study: testare il flusso di verifica email utente
Vediamo adesso un caso specifico che abbiamo iniziato a testare recentemente con il nuovo tool: il flusso di verifica email (classico flusso che invia un’email all’utente, contenente un link che permette di confermare la proprietà dell’indirizzo email fornito).
In questo caso abbiamo utilizzato il pacchetto NPM gmail-tester per connettere Cypress direttamente all’account Gmail-powered.
Conclusioni
Cypress è stata una buona scelta?
Tutto sommato sì, per varie ragioni:
- La sua integrazione nel nostro flusso di lavoro è stata molto semplice;
- Altri team stanno adottando il tool con minimo sforzo, e alcuni di loro hanno pure contribuito all’immagine principale;
- I nostri test sono semplici, e soprattutto stabili!
- La capacità di poter rivedere l’esecuzione dei test grazie ai video generati da Cypress si è rivelata fondamentale nel semplificare l’investigazione di incidenti, soprattutto notturni.
Useresti Cypress per altre tipologie di test?
Adesso stiamo utilizzando il tool soltanto per semplici smoke test e no, non prevediamo di utilizzarlo per test end-to-end complessi o acceptance test.
Il motivo principale è legato a Cypress, che si presenta indubbiamente più stabile e semplice di Selenium, ma che ancora non è pronto per realizzare test complessi.
Nel nostro caso abbiamo quindi deciso di seguire la test pyramid e creare test soltanto per le parti critiche delle nostre UI.
Qui la versione originale in inglese dell’articolo nel blog NextRoll.