Processi di sviluppo software di un team
In questo breve articolo ci soffermiamo su una delle competenze che valorizza il percorso di Tech Leader (TL) all’interno di Develer, ovvero la capacità di organizzare il processo di sviluppo software. In altre parole, il TL ha la responsabilità di strutturare il processo di sviluppo e gli strumenti utilizzati, per fare in modo che il team abbia ben chiari quali sono i flussi per effettuare una modifica, testarla e verificare se ci sono regressioni, venendo incontro alle necessità del cliente.
Composizione del team
Per prima cosa vediamo come solitamente è composto un team, secondo prospettive diverse. Una prima prospettiva consiste nel valutare quali sono i ruoli che ruotano attorno al progetto, che è l’elemento centrale.
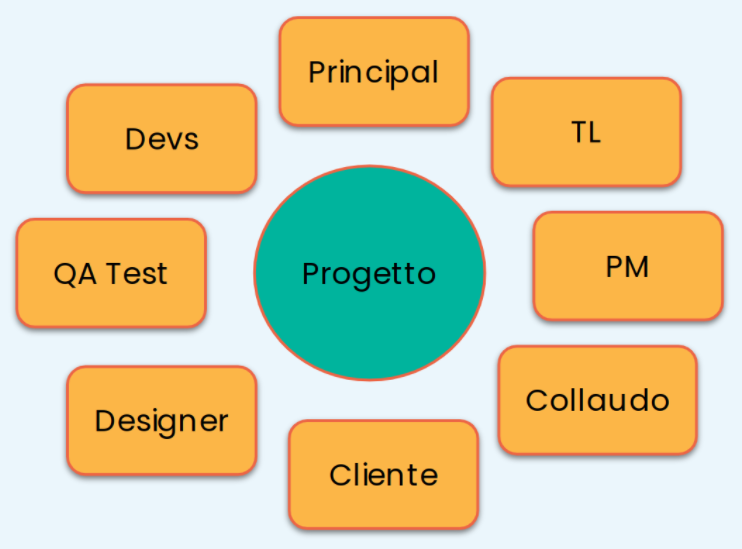
Senza entrare nel merito di altri ruoli, possiamo capire come le esigenze siano molteplici. Per esempio, le esigenze del cliente saranno diverse da quelle di uno sviluppatore. Nel primo caso è probabilmente più importante identificare in modo chiaro l’ultimo rilascio e tutti i file di installazione. Invece, nel secondo caso, si devono mettere in evidenza i dettagli di implementazione, come ad esempio l’esecuzione dei test sul codice. Per ognuno di questi ruoli, dovrebbe essere chiaro come operare sul progetto, senza interpellare o chiedere aiuto ad altre persone.
Un altro punto di vista sul progetto è relativo agli strumenti di sviluppo. Per lavorare in modo proficuo, assolvendo alle esigenze delle persone menzionate in precedenza, è sempre necessario decidere quali strumenti utilizzare e configurare sul progetto.
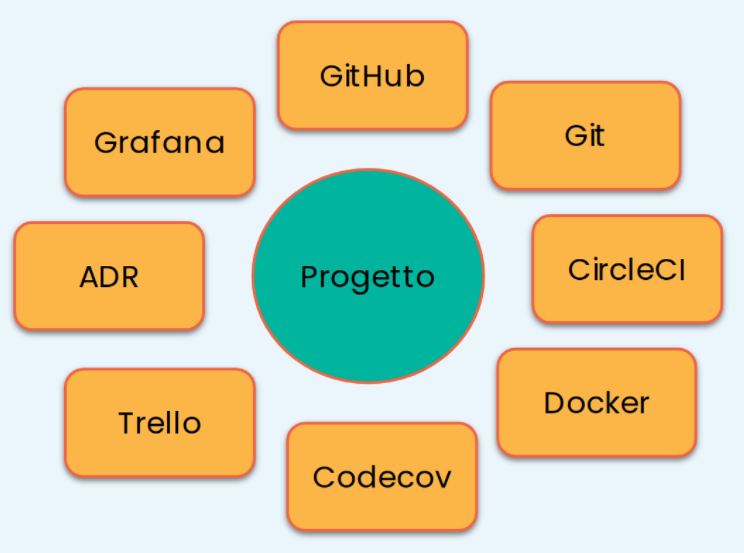
Assumendo di gestire il codice sorgente tramite il sistema di configurazione git, ormai da tempo si sono affermati una serie di strumenti che ne arricchiscono le funzionalità. Parliamo di GitHub, GitLab, ma anche applicazioni di terze parti come Codecov, Trello e così via. Tuttavia questi strumenti non sono stabiliti a priori. Il punto chiave è che la loro scelta dipende dagli obiettivi che vogliamo ottenere e quindi essi sono del tutto flessibili.
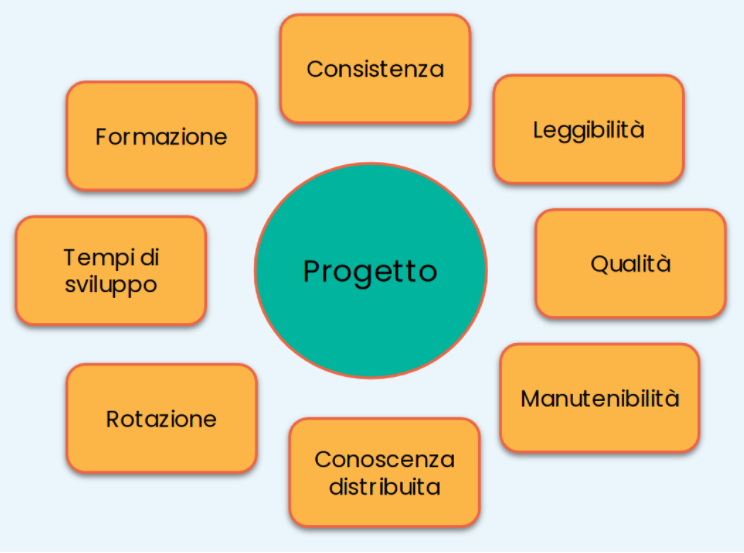
Quindi gli strumenti servono a garantire il raggiungimento di alcuni obiettivi ritenuti importanti per il progetto. Infatti, il progetto dovrebbe essere consistente nelle scelte architetturali, anche su componenti diversi del codice. Questo ne semplifica la comprensione. Inoltre risulterà anche più leggibile, per merito anche dello stile di programmazione utilizzato, che dovrebbe essere più uniforme possibile. Questi aspetti aumentano il livello generale di qualità del codice, anche per mezzo dei test di copertura. Di conseguenza il codice diventa più manutenibile e si accorciano i tempi di sviluppo, a regime. Le persone che lavorano sul progetto possono quindi apprendere meglio e più velocemente e ciò consente anche la rotazione tra i membri del team.
Pertanto, la posizione di TL serve principalmente ad analizzare quali sono tutte queste esigenze di ruoli e progetto, scegliendo le giuste procedure ed i giusti strumenti per facilitare lo sviluppo. Inoltre, non si tratta di una posizione di “comando” ed imposizione, bensì è tutt’altra cosa ed abbraccia il principio di servant leadership. Questo significa che il TL è al servizio del team, al fine di renderlo più produttivo ed autonomo. Il TL avrà svolto il suo compito quando il team sarà in grado di auto organizzarsi nelle scelte e nella gestione.
Workflow di sviluppo
Una scelta fondamentale che coinvolge tutti i progetti è quella dei passi necessari per portare a compimento una certa funzionalità. In questo articolo daremo per assunto lo sviluppo basato su rami, come distinzione rispetto alla base di codice principale, qualunque sia la metodologia di branching scelta. Inoltre, i passi e gli strumenti devono essere sempre tarati in base alla tipologia di progetto e a quello che si vuole ottenere.
Un possibile workflow è mostrato nella figura successiva. Si parte da una card/task in cui è descritta l’attività che deve essere fatta. Ciò fa partire uno sviluppo che si distacca rispetto alla codeline principale, che quindi prosegue in maniera indipendente su di un ramo parallelo. Vedremo più avanti quali sono le strategie per gestire questi rami e come integrarli successivamente nella base di codice principale. Una volta che la funzionalità risulta implementata, lo sviluppatore può aprire una pull request (PR), cioè una procedura per richiederne l’approvazione e la successiva integrazione nel ramo principale. Questo processo di approvazione è guidato da principi di code review, che non tratteremo qui. Tuttavia, al di là di come viene revisionato il codice, a livello di processo di sviluppo è molto importante utilizzare degli strumenti per effettuare controlli aggiuntivi automatici sul codice della pull request. Un primo controllo automatico è rappresentato dall’esecuzione dei test di unità e integrazione, che devono essere sempre forniti a corredo della nuova funzionalità. Tali test si possono eseguire manualmente, però è più vantaggioso se sono lanciati in automatico, mostrandone il risultato. Uno strumento famoso per l’esecuzione dei test è CircleCI, ma non è il solo. Ad esempio possiamo anche scegliere di utilizzare GitHub Actions, Bitbucket Pipelines oppure altro ancora. L’esecuzione dei test porta ad esercitare delle parti di codice che quindi risulteranno “coperte” dai test. Per visualizzare questa copertura, ci sono altri strumenti o applicazioni che forniscono un valore in percentuale. La copertura è anche fondamentale per verificare che le parti di codice aggiunte siano state effettivamente testate. Oppure al contrario, se ci sono delle zone che non possono essere testate perché inutili. Di solito, un buon obiettivo è raggiungere una copertura generale di progetto dell’80% (non tutto è testabile). Però, a livello di pull request, è utile controllare che invece tutto il codice aggiunto sia coperto e poi valutare insieme al team se ci sono delle eccezioni. La gestione della pull request fino a questo punto, così come è stata descritta, richiede quasi sicuramente di fare un setup di uno strumento di continuous integration (CI), quale GitHub, GitLab, Bitbucket o altri. Quindi ci riferiamo a continuous integration come uno strumento per eseguire azioni in automatico sulla pull request. Vedremo più avanti che lo stesso termine è anche associato ad una strategia di sviluppo con git basata su rami. È comunque corretto che questi due aspetti condividano lo stesso nome, dal momento che sono legati tra loro.
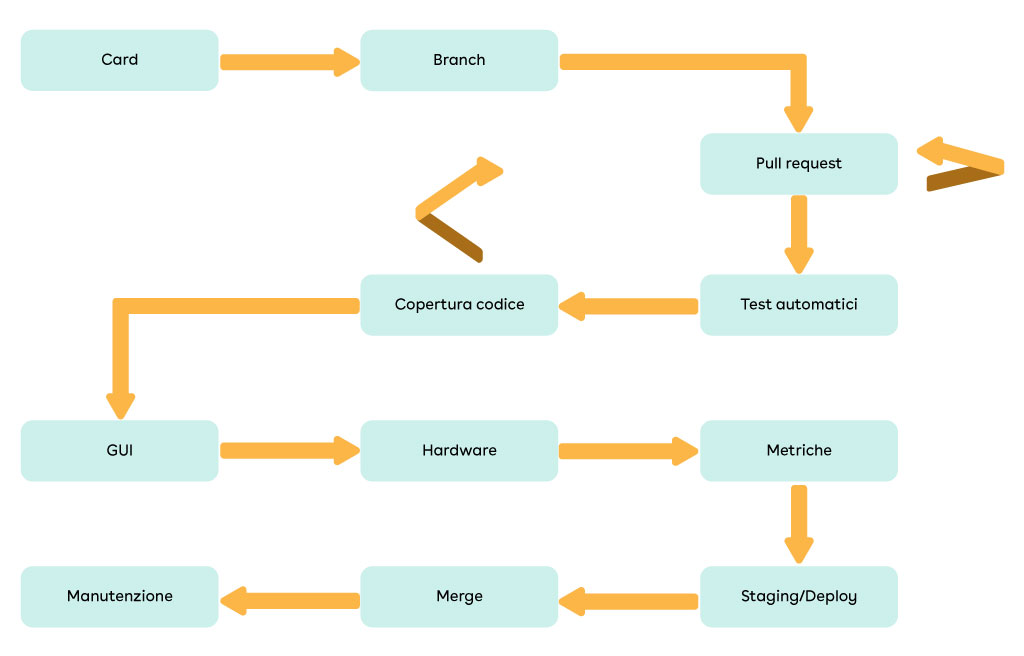
Oltre alle verifiche automatiche sul codice sorgente, si possono identificare anche attività manuali, a seconda del tipo di PR. Ad esempio, una funzionalità può apportare modifiche ad una GUI, quindi l’interfaccia utente dovrà essere provata in qualche modo (in questo caso i test automatici sono difficili da implementare). Inoltre può essere coinvolto un hardware che necessita test specifici. Se il progetto deve anche rispettare delle prestazioni di esecuzione, allora dovremo garantire la non regressione, mettendo in piedi un sistema di metriche con strumenti come Grafana/Prometheus o altri. Il sistema di CI può addirittura creare degli artefatti per facilitare un eventuale deploy del progetto, in modo che possa essere provato più facilmente. Quando tutti questi test sono conclusi con successo, arriva il momento di integrare la nuova funzionalità dentro la codeline principale. A seconda della strategia di branching utilizzata, questa fase di merge può prevedere la risoluzione di conflitti su codice sorgente, che si generano con le nuove modifiche introdotte nel codice principale. Infine, ogni volta che il ramo principale riceve nuove modifiche, potrebbe essere necessaria una fase di manutenzione. Questo significa che eventuali altri branch che sono mantenuti in vita prima di essere integrati, potrebbero a loro volta aver bisogno di essere aggiornati con le nuove modifiche.
Tracciamento delle funzionalità
Durante questi passi di sviluppo, ci sono una miriade di sfaccettature e dettagli che bisogna tenere in considerazione, al fine di facilitare la gestione del progetto. Però un aspetto che quasi sempre risulta utile è il tracciamento delle funzionalità. Questa operazione dipende dal tipo di strumento utilizzato. Ad esempio, alcune volte una PR può essere collegata ad una issue/task. In questo modo, ogni PR può essere riconducibile alle sue specifiche. Però nel caso si utilizzi Trello oppure altri strumenti altrettanto flessibili, questo non è automatico. Quindi possiamo rafforzare la tracciabilità con alcune buone pratiche:
- Utilizzare un formato standard per i nomi delle card di Trello. Ad esempio si può includere il numero della card stessa, la milestone, fase/sottofase.
- Collegare alla issue/card tutte le informazioni necessarie, come PR, allegati ma anche link alla conversazione Slack che ha causato l’apertura della card, se esiste.
- Aggiungere alla card una checklist di massima per indicare i passi svolti, ma anche i test manuali che s’intendono fare. Questo dà visione del lavoro svolto anche per i meno addetti ai lavori. Inoltre si capisce meglio quali ulteriori prove sono state fatte, a parte i soliti test di unità.
- Creare un ramo git il cui nome ha un formato standard. Ad esempio si può includere il numero card di Trello, numero PR, oppure altri dettagli menzionati prima.
- Utilizzare un suffisso/prefisso speciale per i rami git, al fine di istruire la CI a svolgere operazioni speciali. Ad esempio, se un ramo finisce col suffisso “-installer”, allora la CI potrebbe eseguire un passo di creazione di un eseguibile per installare la nostra applicazione Qt.
- Associare alle PR una checklist che lo sviluppatore controlla, prima di avviare la procedura di code review. Ad esempio, un buon elemento di questa checklist potrebbe essere quello di aggiornare della documentazione.
Strategie di sviluppo e git flow
Lo strumento principale per lo sviluppo del codice a cui ho fatto riferimento finora è git, che è uno strumento per il controllo di versione del codice sorgente (SCM). Non è il solo, bensì ce ne sono molti altri come SVN, Mercurial, etc. Tuttavia il concetto di sviluppo a rami è più astratto, indipendentemente dall’implementazione di un SCM. Con git non abbiamo questo problema, dal momento che i rami sono supportati in modo molto efficiente e questo forse è stato un punto fondamentale per affermare la sua forza.
Sviluppo parallelo
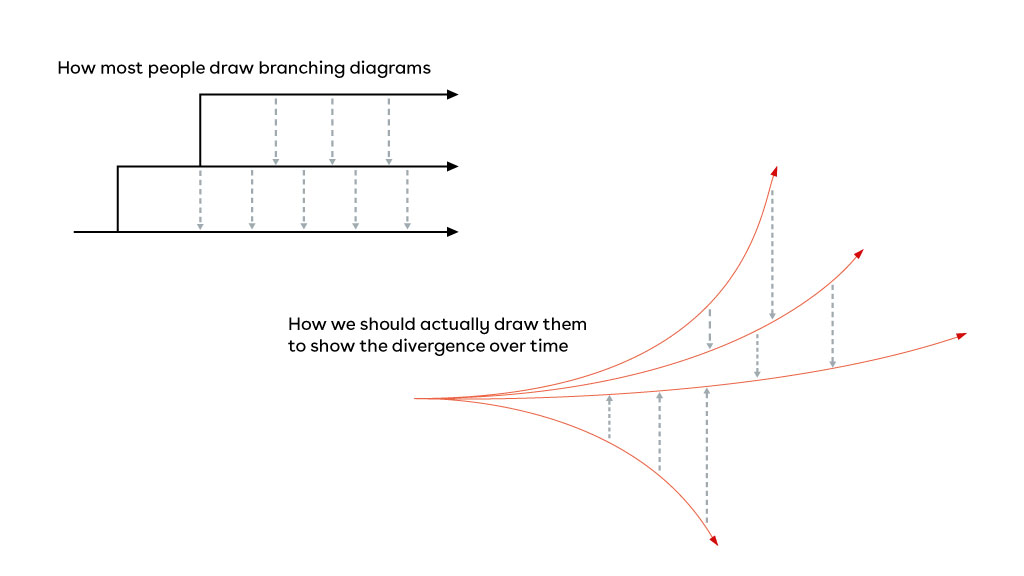
Quando parliamo di sviluppo parallelo spesso immaginiamo i rami come rette parallele che proseguono il loro cammino all’unisono. In realtà la rappresentazione più corretta è quella di curve che si distanziano sempre più tra di loro. In effetti è realmente così e ciò porta ad una certa “paura del merge”, dovuta ai molti conflitti sul codice sorgente che lo sviluppatore è costretto a risolvere tutte le volte che deve integrare rami diversi tra di loro. Tali conflitti possono essere testuali (la stessa riga di codice è modificata in modo diverso) oppure semantici (aggiungo un parametro ad una funzione). Nel primo caso git viene in soccorso, mostrando il conflitto in modo evidente. Nel secondo, invece, il conflitto verrà fuori solo quando si cerca di compilare o eseguire il codice e quindi sono conflitti più insidiosi. Per questa ragione è importante avere delle strategie di sviluppo al fine di semplificare il lavoro in team.
Modello git flow
Il git flow è un modello di branching che è ampiamente descritto in un famoso articolo ormai di qualche anno fa. Possiamo fare riferimento alla seguente immagine per la descrizione:
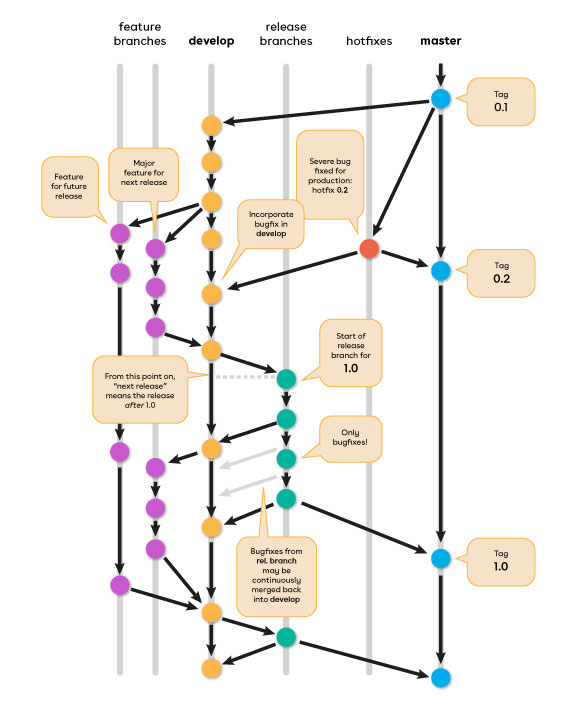
I punti chiave di questa strategia sono:
- Il ramo master è considerato production ready.
- Il ramo develop mantiene la prossima release.
- Quando la release è stabile, allora può essere integrata su master.
- I merge su master danno luogo all’aggiunta di tag, per marcare la versione.
- I rami feature derivano e si integrano su develop.
- Tutte le funzionalità per una certa release devono essere aggiunte a develop.
- Le dipendenze tra funzionalità devono essere stabilite in fase di pianificazione.
- I rami di release servono a stabilizzare un rilascio.
- All’inizio del ramo si assegna un numero di rilascio, come release-1.2.
- Partono da develop e si integrano su master.
- Necessario allineare le modifiche anche all’indietro su develop.
- Il branch di release si cancella una volta che è stato integrato.
- I rami di hotfix servono a risolvere bug in produzione.
- Le modifiche devono essere riportate sia su master che su develop.
- Anche i vari release branch attualmente aperti devono essere allineati.
Questo modello ha gettato le basi dei principi dello sviluppo di funzionalità, ma possiamo capire come queste molte regole siano a volte complicate e la gestione di tutti questi rami può essere onerosa. Il modello si basa sostanzialmente su feature branch e su molteplici rami primari.
Continuous Integration
Con l’avvento di applicazioni e servizi di CI, la strategia di sviluppo che tendenzialmente è ritenuta più flessibile è quella che evita i feature branch, detta continuous integration oppure trunk-based.
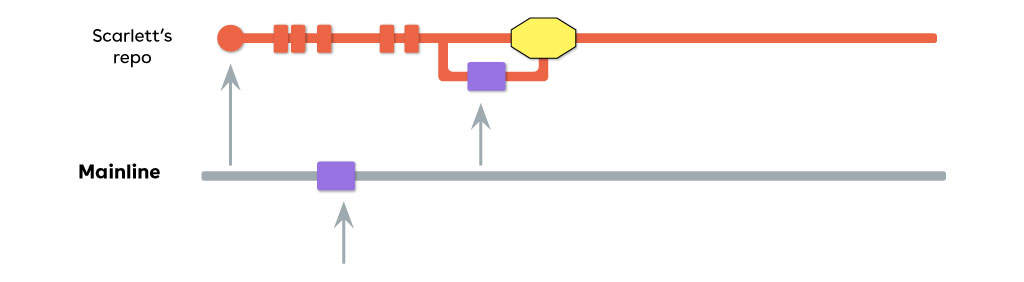
Questa strategia può essere riassunta così:
- C’è un unico ramo mainline condiviso, che rappresenta lo stato del prodotto.
- Non ci sono feature branch.
- I rami hanno una durata breve.
- Ogni ramo ha pochi commit.
- È possibile creare dei release branch temporanei per stabilizzare un rilascio.
- L’integrazione dei release branch sulla mainline dà luogo a un tag di versione.
Lavorare secondo questa metodologia è vantaggioso perché limita la complessità di gestione, mentre il progetto ed il team aumentano di dimensioni. Infatti, siccome i rami sono più corti, la risoluzione dei conflitti diventa molto più facile.
Ovviamente ci sono anche degli aspetti da tenere in considerazione:
- È necessario strutturare bene il codice sorgente, con molti test.
- È necessario mettere in piedi strumenti di CI per effettuare controlli ogni volta che si integrano nuove modifiche nella mainline.
- Se i test sono lunghi, può diventare oneroso eseguirli per ogni ogni merge.
- Funzionalità diverse saranno aggiunte tutte insieme, quindi potrebbero interferire tra loro.
- È più difficile garantire che le funzionalità già implementate non subiscano regressioni.
Ci sono quindi anche delle varianti di continuous integration puro, oppure best practice, principalmente legate a come si gestiscono i rilasci delle nuove funzionalità.
Feature flags
L’aggiunta delle nuove funzionalità avviene in dei code path isolati oppure inattivi. L’attivazione di questo codice avverrà in un secondo momento, quando si decide di effettuarne il rilascio. Ad esempio, un’applicazione web potrebbe avere dentro di sé il codice per una nuova pagina, tuttavia se l’utente non è in grado di raggiungerla tramite un link, essa sarà di fatto nascosta e non utilizzabile. Alternativamente la configurazione può avvenire a compile time oppure a run time per mezzo di file di configurazione.
Release train
Questa strategia prevede il rilascio di nuove funzionalità ad intervalli di tempo pianificati. Ad esempio, mensilmente si crea un nuovo branch su cui rilasciare tutte le funzionalità pianificate per quel mese.
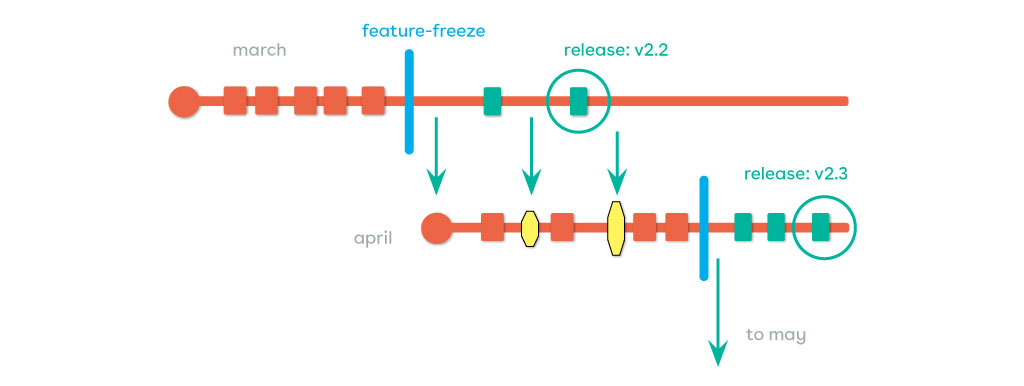
Si decide quale “treno” ogni feature dovrà prendere. Alla fine di questo slot di tempo, non è possibile far entrare nuove modifiche, ma esse dovranno aspettare il prossimo treno. Anche in questo caso, al momento del “feature freeze”, si può creare un release branch per stabilizzare tutte le feature pianificate. Il release branch sarà poi integrato come partenza per il prossimo release train. Per applicare questa strategia è necessaria una pianificazione strutturata delle funzionalità e accettare che alcune modifiche dovranno attendere il prossimo treno.
Automatismi
Oltre a decidere il flusso di lavoro più consono per il progetto, quest’ultimo deve anche disporre di una serie di automatismi per renderlo più riproducibile. Questa caratteristica è importante quando sopraggiunge un nuovo sviluppatore (onboarding), quando si fa formazione per i junior, per risolvere più velocemente bug e fare testing, ma anche quando si interagisce col cliente. Al primo approccio col progetto, l’obiettivo è quello di installare manualmente il meno possibile e successivamente avvalersi di script o strumenti opportunamente configurati, per svolgere le operazioni più comuni. Una convenzione ampiamente utilizzata è quella di aggiungere un file README. Esso non rappresenta una documentazione architetturale del progetto, bensì è rivolto ad uno sviluppatore e contiene semplici step per configurare il progetto.
Ma quali sono le operazioni più comuni? Ovviamente dipende dal tipo di progetto, però possiamo certamente elencarne alcune:
- Configurazione ambiente di sviluppo.
- Compilazione: Build, Clean, Run,
- Test e Copertura.
- Deploy: Flash di dispositivi, Staging o Artefatti.
- Versionamento: Rilascio, Nuova versione, Changelog.
Alcuni strumenti che possiamo menzionare per implementare queste automatizzazioni sono Makefile, Script, Docker, Foreman, Doxygen, etc… Anche gli editor sono strumenti fondamentali per gestire il software, tuttavia ognuno dovrebbe essere in grado di scegliere quello che preferisce. L’importante è la configurazione dell’editor, ad esempio per formattare il codice sorgente tutte le volte che un file viene salvato.
Vediamo adesso brevemente alcuni di questi strumenti.
Makefile
Un Makefile può essere un valido strumento per accedere agli script. Quindi non si stratta di scrivere un Makefile a mano per compilare un progetto. Per quello ci sono i sistemi di build, che faranno un lavoro molto migliore. Un Makefile, invece, è utile per fornire comandi di alto livello (come `make test`, `make all`, etc…), per cross compilare la nostra applicazione, per utilizzare gli stessi target anche nel sistema di CI e così via. Come il README, usare il Makefile è una convenzione nota e rappresenta anche una forma di documentazione per lo sviluppatore.
Foreman
Consente l’esecuzione multipla di più componenti, fornendo un output integrato in una sola console. Si pensi, ad esempio, ad un progetto organizzato a micro servizi. Tutti i processi si fermano quando almeno uno fra di essi si interrompe. La configurazione avviene con un Procfile testuale. Non richiede una conoscenza elevata e può essere usato e modificato da chiunque.
Docker
Le funzionalità fornite da Docker sono ampie e questo software è decisamente più complicato, rispetto agli altri strumenti menzionati. Introdurre Docker vuol dire avere necessità di supportare più piattaforme di sviluppo, potendo quindi vendorizzare l’intero sistema di sviluppo. Si configura attraverso un Dockerfile, ma in questo caso dovremmo fornire degli script “Docker-aware”, ovvero che supportino la modalità di esecuzione all’interno di un container Docker.
Vendorizzare il progetto
In ambito industriale è fondamentale essere in grado di ripristinare un progetto anche dopo che sia passato del tempo. Gli strumenti cambiano, le dipendenze esterne progrediscono di versione ed i nostri script ed il software potrebbero non compilare più. Quindi il concetto del vendoring è quello di integrare all’interno del repository software tutto ciò che serve alla compilazione del progetto. Con Docker possiamo addirittura vendorizzare l’intero sistema di sviluppo. Però possiamo anche decidere di vendorizzare il solo codice sorgente e linguaggi moderni come Go e Rust già si basano su questo principio, mettendo a disposizione comandi adeguati. Oppure la vendorizzazione può anche essere ottenuta con git stesso. Infatti, la strategia git subtree consente di integrare una copia di un modulo esterno all’interno del nostro progetto. Questo si contrappone alla strategia `git submodule`, la quale prevede di tenersi un riferimento verso il modulo esterno. Ovviamente questo riferimento potrebbe diventare invalido nel futuro. Utilizzare `git subtree` semplifica anche l’utilizzo di altri comandi git, come ad esempio `git bisect`. Ovvero, durante la ricerca binaria di un bug, facendo il checkout di un certo commit nel passato, saremo sicuri che il nostro codice compilerà correttamente e che i test continueranno a funzionare, senza dover fare ulteriori operazioni di allineamento dei moduli esterni.
Conclusioni
Come abbiamo visto, fare delle scelte sull’organizzazione di un progetto software coinvolge molte sfaccettature. Un aspetto importante è quello di supportare e facilitare lo sviluppo di tutti i giorni, senza però dimenticarsi delle altre figure che ruotano intorno al progetto. Sicuramente ogni tanto il cliente chiederà di rilasciare una nuova versione software, oppure di fornire Changelog tra una versione ed un’altra. Mettendo in piedi un processo strutturato, un’operazione manuale come la costruzione del Changelog può essere ottenuta in modo automatico anche con un solo comando, ad esempio:
$> git log --merges v10.0..v.11.0
Questo perché si è deciso di tracciare ogni ramo di merge verso una certa card/issue e di integrare tutte le funzionalità sulla stessa codeline condivisa. Ne consegue che sia possibile risalire immediatamente alla descrizione di alto livello di ogni modifica effettuata al codice.
Per questi motivi, strutturare il progetto permette di ottenere una maggiore velocità e flessibilità nella risoluzione dei problemi, variazioni al team di sviluppo e venire incontro a nuove richieste. Gli strumenti e le piattaforme per ottenere ciò sono le più disparate e non c’è nessun obbligo di utilizzo, ma solo buone pratiche da seguire.