Loop di eventi asincroni con Zig
Mi sono recentemente cimentato in dei test con il linguaggio di programmazione Zig (versione 0.9.1), in particolare su una caratteristica del linguaggio che riguarda il concetto di async/await. Ho ritenuto interessante provare ad implementare un semplice event loop per la gestione di eventi asincroni. Si sente parlare spesso di loop di eventi oppure di async/await in molti altri contesti, ma caliamo questi concetti nel linguaggio Zig.
Cos’è un loop di eventi
Un loop di eventi è un costrutto ed uno stile di programmazione per cui un algoritmo centrale si occupa di smistare eventi a componenti. Ogni componente spesso gestisce uno specifico evento, per cui il codice sorgente risulta ben organizzato e più facile da mantenere. Inoltre, il loop di eventi si appoggia spesso a primitive del sistema operativo, da cui riceve notifiche. Questa combinazione può condurre ad uno stile di programmazione asincrona, dove ogni componente reagisce all’evento specifico, quando quest’ultimo si verifica.
Con questo principio di funzionamento possiamo quindi identificare operazioni concorrenti tra loro, senza però specificare necessariamente il grado di parallelismo. In alcuni framework (come Qt), le operazioni concorrenti “girano” per default su singolo thread, rappresentando quindi una soluzione efficace di sincronizzazione tra questi diversi componenti software. Ciò significa che non si possono verificare accessi contemporanei alle stesse aree di memoria (data race), con un chiaro vantaggio di robustezza del codice. In questo articolo infatti non parlerò di multi-threading, bensì mi focalizzerò su operazioni concorrenti sempre su singolo thread, nonostante si possano implementare anche meccanismi più complessi su più thread.
Programmazione asincrona
Zig ammette l’esecuzione di codice “asincrono” utilizzando le parole chiave async e await. In generale la programmazione asincrona si può basare su callback, su meccanismi async/await oppure altri sistemi di message passing.
Quando programmiamo ad eventi, ad esempio in C, l’opzione a cui giungiamo frequentemente è quella di introdurre callback. Questa metodologia però rende il codice più difficile da comprendere, sia dal punto di interfacce API, sia perché la stessa business logic deve essere divisa in passi separati su funzioni diverse. Ciò costringe anche il programmatore a mantenere uno stato da qualche parte, da condividere tra le varie callback. In altri linguaggi, invece, possiamo lasciar fare questo lavoro al compilatore o alla sua libreria standard. A volte utilizzare async/await è invasivo perché potenzialmente dobbiamo dichiarare una funzione come tale, modificare la sua interfaccia e poi attenderne il suo completamento utilizzando pattern speciali. Ad esempio, in Go dobbiamo avere alcune accortezze, senza criticare la flessibilità di questo approccio:
- Una funzione asincrona deve essere chiamata con la parola chiave go.
- Non è possibile utilizzare un valore di ritorno, il che ci costringe a passare per esempio un channel tra i suoi argomenti.
- Non c’è una parola chiave per attendere il completamento, quindi una possibilità è passare un Context e poi attendere con un WaitGroup.
Queste regole fanno sì che una funzione asincrona debba seguire una gestione speciale, rispetto ad ogni altra funzione bloccante.
In Zig queste differenze sono meno accentuate, nonostante sia sempre necessario avere in mente che una funzione asincrona per sua natura segue un flusso diverso da una bloccante. Più precisamente, si può continuare ad esprimere la concorrenza tra componenti per mezzo di aysnc/await, indipendentemente dal tipo di esecuzione che scegliamo, ovvero bloccante o ad eventi. Il compilatore permette l’utilizzo di funzioni asincrone da parte di funzioni non asincrone. Tale proprietà rende possibile la realizzazione di librerie che lavorano su codice asincrono o bloccante, in modo trasparente.
Da notare che non c’è niente di male nel definire astrazioni complicate a piacere, per ottenere certi risultati in termini di concorrenza e parallelismo. Tuttavia, nella filosofia Zig, un linguaggio “di sistema” dovrebbe sempre mostrare in modo chiaro il flusso di controllo, senza nasconderne dettagli e allocazioni e senza mai ignorare gli errori.
Ad ogni modo, in poche parole, con Zig una funzione asincrona si esegue attraverso la parola chiave async e ne attendiamo successivamente il risultato con await. La stessa funzione, se chiamata direttamente senza questa coppia di parole chiave, si comporterà come se fosse una funzione bloccante. Due funzioni chiamate con async una dopo l’altra, eseguiranno in modo concorrente e con await possiamo attenderne il loro completamento.
Il comportamento appena descritto si ottiene da una sinergia tra il codice generato dal compilatore e la libreria standard. Per il primo punto, una funzione asincrona Zig si comporta come una stackless coroutine. Per il secondo punto, esiste un elemento std.event.Loop della libreria standard che gestisce chiamate asincrone e sfrutta la capacità di sospensione e ripresa di queste coroutine. La suddetta separazione consente flessibilità nell’utilizzo di un loop di eventi completamente personalizzato, come il semplice esempio di questo articolo.
Strategia di sospensione e ripresa
Supponiamo di voler realizzare un programma che reagisca ad uno o più timer che scattano in modo indipendente. Vogliamo realizzare ciò sfruttando eventi asincroni gestiti attraverso un loop principale. Per prima cosa dobbiamo capire come utilizzare l’infrastruttura di notifiche I/O fornite dal sistema operativo e poi come organizzare le coroutine.
Notifiche su eventi di I/O
Facciamo riferimento al sistema operativo GNU/Linux, che dispone di API epoll che fanno al caso nostro (invece per MacOS e Windows esistono rispettivamente kevent e iocp). Più in dettaglio, un processo user space può ricevere notifiche dal kernel relative ad eventi a cui si è registrato. Uno di questi eventi può essere proprio lo scatto di un timer creato tramite le API timerfd e gestito interamente dal kernel. Quindi il loop di eventi può essere scritto come un ciclo che aspetta eventi dal kernel:
fn mainLoop() !void {
const epoll_fd = blk: {
const rc = linux.epoll_create1(linux.EPOLL.CLOEXEC);
if (linux.getErrno(rc) != .SUCCESS) {
return error.FailureEpoll;
}
break :blk @intCast(i32, rc);
};
defer {
_ = linux.close(epoll_fd);
}
...
while (true) {
var events: [1]linux.epoll_event = undefined;
const rc = linux.epoll_wait(epoll_fd, events[0..], events.len, -1);
const err = std.os.linux.getErrno(rc);
if (err != .SUCCESS) {
return error.FailedEpollWait;
}
for (events[0..rc]) |ev| {
...
}
}
...
}Le fondamenta del ciclo di eventi sono state già scritte, non c’è molto altro da inventare! In effetti, questo ciclo può risultare simile a ciò che scriveremmo in linguaggio C. Però, la differenza principale è l’organizzazione del codice. Infatti, in C questo solo ciclo non sarebbe sufficiente. Generalmente ci sarebbe una parte di codice volta a decodificare il tipo di evento, per poi chiamare le funzioni appropriate per la sua presa in carico, passando loro lo stato attuale. Al contrario, con l’uso di coroutine questa struttura risulta più semplice e pulita.
Attività cooperative tramite coroutine
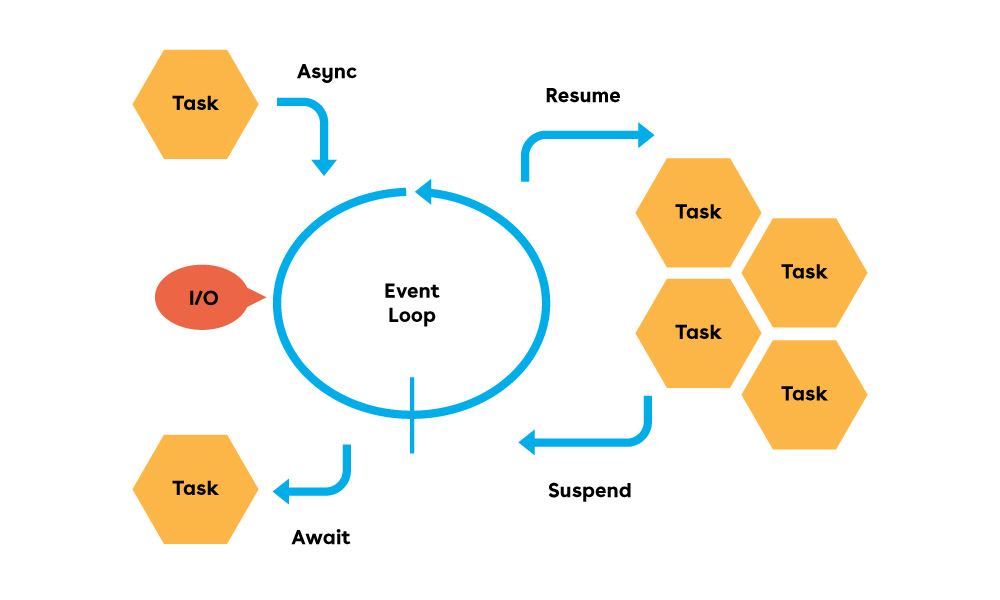
Una funzione chiamata attraverso la keyword async opera come una coroutine. Questo significa che il flusso di controllo può rimbalzare più volte tra il chiamante e la funzione stessa, prima dell’istruzione finale di ritorno. Il chiamante dovrà salvare il frame della funzione su cui poi effettuare l’operazione di await. L’istruzione di await rappresenta un punto di sospensione, che si sblocca solo quando il risultato finale sarà disponibile. A loro volta, i mattoncini su cui si basano async/await sono le keyword suspend e resume. In ogni momento una funzione si può sospendere, causando il ritorno del flusso di controllo al chiamante. Allo stesso modo, il chiamante può far ripartire la funzione dal punto successivo a dove era stata sospesa in precedenza.
Vediamo una possibile implementazione del timer asincrono, da integrare nel loop di eventi.
var tick_count: u64 = 0;
const max_tick_count = 10;
fn waitForTick(epoll_fd: i32, timeout_ms: u64) !void {
const timer_fd = try createTimer(timeout_ms);
defer {
_ = linux.close(timer_fd);
}
var ev = linux.epoll_event{
.events = linux.EPOLL.IN | linux.EPOLL.ET,
.data = linux.epoll_data{ .ptr = @ptrToInt(@frame()) },
};
const rc = linux.epoll_ctl(epoll_fd, linux.EPOLL.CTL_ADD, timer_fd, &ev);
if (linux.getErrno(rc) != .SUCCESS) {
return error.FailureEpollCtlAdd;
}
defer {
_ = linux.epoll_ctl(epoll_fd, linux.EPOLL.CTL_DEL, timer_fd, null);
}
while (tick_count < max_tick_count) {
// wait for timer...
suspend {}
// timer is expired
var exp_count: [@sizeOf(u64)]u8 = undefined;
const rn = linux.read(timer_fd, &exp_count, exp_count.len);
if (linux.getErrno(rn) != .SUCCESS) {
return error.FailureTimerFdRead;
}
// increment tick count
tick_count += 1;
}
}La funzione waitForTick crea inizialmente un timer per mezzo di createTimer, che a sua volta utilizzerà la syscall timerfd_create, impostando il corretto intervallo di timeout. Successivamente, il file descriptor del timer si può registrare nell’infrastruttura epoll tramite la chiamata epoll_ctl a cui viene passato il puntatore all’evento ev. Le risorse sono allocate nel frame della coroutine e grazie alle istruzioni defer si procede al loro rilascio al momento del completamento definitivo. Particolare attenzione va posta all’istruzione suspend, la quale restituisce il controllo al ciclo principale. Questa operazione rientra nel più ampio argomento dello scheduling cooperativo e le coroutine hanno quindi la caratteristica di portare avanti le proprie attività rilasciando volontariamente il controllo al loro scheduler. Il vantaggio consiste nell’avere dei punti di sincronizzazione ben definiti in modo programmatico e con cambi di contesto leggeri, guadagnando in termini di prestazioni. Al contrario, i thread classici sono gestiti dallo scheduler di sistema, portando spesso alla necessità di protezione delle zone di dati condivise. In altre parole, facendo riferimento a questo esempio, si possono avviare timer molteplici richiamando più volte la funzione waitForTick, senza necessità di proteggere la variabile condivisa tick_count.
Intercalare le attività
Dal momento che una coroutine si può sospendere, bisogna sempre pensare ad una strategia di ripresa. Nel caso specifico di questo esempio, si è deciso di salvare il frame della coroutine nell’evento epoll, attraverso l’istruzione @frame. Così facendo, quando il kernel risveglierà il loop principale, quest’ultimo sarà in grado di riprendere la coroutine sospesa, passando il suo frame all’istruzione resume. Questo algoritmo rappresenta in definitiva un meccanismo di scheduling molto semplice.
fn mainLoop() !void {
...
var frame1 = async waitForTick(epoll_fd, 1, 500);
var frame2 = async waitForTick(epoll_fd, 2, 500);
while (!stopCondition()) {
var events: [2]linux.epoll_event = undefined;
const rc = linux.epoll_wait(epoll_fd, events[0..], events.len, -1);
const err = std.os.linux.getErrno(rc);
if (err != .SUCCESS) {
return error.FailedEpollWait;
}
for (events[0..rc]) |ev| {
const frame = @intToPtr(anyframe, ev.data.ptr);
resume frame;
}
}
try nosuspend await frame1;
try nosuspend await frame2;
}Possiamo vedere l’avvio di due timer separati, entrambi con timeout di 500ms. Il ciclo di scheduling risulta di fatto indipendente dalla tipologia di attività che gestisce. Infatti, si possono agevolmente definire attività completamente differenti tra loro (ad esempio, un server TCP in attesa di connessioni), con l’accortezza però di rispettare il formato comune per l’evento epoll. In definitiva, l’algoritmo di scheduling non contiene codice di decodifica dell’evento, né tantomeno lo stato delle varie attività.
Questo esempio è stato pensato specificatamente per GNU/Linux, perciò non può funzionare su altri sistemi operativi. Potrebbe essere molto utile avere un loop di eventi multipiattaforma. Vediamo cosa mette a disposizione la libreria standard.
Loop di eventi da libreria standard
Nella libreria standard di Zig esiste un loop di eventi che si configura automaticamente quando scegliamo di utilizzare I/O ad eventi, attraverso la variabile io_mode. Inoltre, dal momento che vogliamo far uso di un solo thread, dobbiamo specificare il valore appropriato per la variabile event_loop_mode, ovvero .single_threaded. Sfruttando il loop di eventi fornito dalla libreria standard, possiamo anche ridurre le righe di codice da scrivere. Questo perché altre funzioni della libreria standard faranno uso di questa infrastruttura, in modo trasparente. Si veda infatti l’implementazione della funzione std.time.sleep, che va ad utilizzare il loop di eventi standard se abbiamo scelto la modalità I/O asincrono (.evented), piuttosto che bloccante (.blocking), tramite la variabile io_mode.
Di seguito l’esempio completo, riscritto sfruttando ciò che ci mette a disposizione la libreria standard.
const std = @import("std");
const print = std.debug.print;
const sleep = std.time.sleep;
const tid = std.Thread.getCurrentId;
const net = std.net;
pub const io_mode = .evented;
pub const event_loop_mode = .single_threaded;
const the_loop = std.event.Loop.instance orelse
@compileError("event-based I/O loop is required");
pub fn main() !void {
try mainLoop();
}
var tick_count: u64 = 0;
const max_tick_count = 10;
fn waitForTick(id: i32, timeout_ms: u64) !void {
printInfo(id, "ticker start", null);
while (tick_count < max_tick_count) {
// wait for timer...
sleep(timeout_ms * std.time.ns_per_ms);
// increment tick count
tick_count += 1;
printInfo(id, "ticker fired", tick_count);
}
printInfo(id, "ticker stop", null);
}
fn acceptConnection(server: *net.StreamServer, id: i32) !void {
const localhost = try net.Address.parseIp("127.0.0.1", 15000);
try server.listen(localhost);
printInfo(id, "listening on 127.0.0.1:15000", null);
while (true) {
var conn = server.accept() catch |err| switch (err) {
error.SocketNotListening => return,
else => return err,
};
defer conn.stream.close();
var buf: [1024]u8 = undefined;
const nr = try conn.stream.reader().read(&buf);
printInfo(id, buf[0..nr], nr);
_ = try conn.stream.writer().write("thank you for chatting! :)\n");
}
printInfo(id, "listening stop", null);
}
fn mainLoop() !void {
printInfo(0, "mainLoop: start", null);
const NTICKS = 2;
var id: i32 = 1;
var tick_frame: [NTICKS]@Frame(waitForTick) = undefined;
while (id <= NTICKS) : (id += 1) {
tick_frame[@intCast(usize, id - 1)] = async waitForTick(id, 500);
}
var server = net.StreamServer.init(.{
.reuse_address = true,
});
defer server.deinit();
var server_frame = async acceptConnection(&server, id + 1);
for (tick_frame) |*frame| {
try await frame;
}
try std.os.shutdown(server.sockfd.?, .recv);
try await server_frame;
printInfo(0, "mainLoop: end", null);
}
fn printInfo(id: i32, msg: []const u8, val: ?u64) void {
print("[{d}][{d}] {s}", .{ tid(), id, msg });
if (val) |value| {
print(": {d}", .{value});
}
print("\n", .{});
}È stata aggiunta anche la gestione di una connessione TCP, oltre ai due timer. Si vede come la funzione mainLoop sia adesso molto diversa, esprimendo in modo chiaro quali attività eseguono in concorrenza tra loro, attraverso la parola chiave async. Rispetto alla versione precedente, adesso tutto si riduce all’attesa del completamento delle funzioni concorrenti, tramite le istruzioni di await. Tuttavia il principio di funzionamento è lo stesso, ovvero le 3 attività eseguiranno in concorrenza su singolo thread. Ad esempio, la funzione std.net.StreamServer.accept() farà in modo che la coroutine acceptConnection() sia sospesa in attesa di una connessione, spostando il flusso d’esecuzione sulle altre attività. Nel momento in cui arriva una connessione, la coroutine acceptConnection() riprenderà da dove era rimasta sospesa. Allo stesso modo, anche la funzione std.net.Stream.read() eseguirà in modalità I/O ad eventi, causando ancora una volta la sospensione fino a che non ci saranno dati da leggere via rete. Ecco l’output del programma precedente:
[35408][0] mainLoop: start
[35408][1] ticker start
[35408][2] ticker start
[35408][4] listening on 127.0.0.1:15000
[35408][1] ticker fired: 1
[35408][2] ticker fired: 2
[35408][1] ticker fired: 3
[35408][2] ticker fired: 4
[35408][1] ticker fired: 5
[35408][2] ticker fired: 6
[35408][1] ticker fired: 7
[35408][2] ticker fired: 8
[35408][1] ticker fired: 9
[35408][2] ticker fired: 10
[35408][2] ticker stop
[35408][1] ticker fired: 11
[35408][1] ticker stop
[35408][0] mainLoop: endDa notare che lo stesso programma compila e funziona anche in modalità bloccante, seppur con un comportamento diverso. Questo si può ottenere per mezzo della variabile io_mode:
pub const io_mode = .blocking;Naturalmente, se eseguiamo il programma in modalità bloccante, sia i timer che la gestione della comunicazione TCP si tradurranno in syscall bloccanti verso il kernel. Ciò implica che, ad esempio, la funzione di sleep si comporti proprio come un’attesa “vecchio stile”, imponendo una sequenza ben precisa nell’esecuzione delle funzioni successive, ovvero una dopo l’altra. Questo comportamento, da una parte altera il flusso di esecuzione, ma in certe situazioni potrebbe essere ancora corretto. Si pensi, ad esempio, al download di dati via rete, che possono avvenire concettualmente sia in parallelo che in sequenza. Il risultato finale sarà valido in entrambe le situazioni. Ciò che cambia è il tempo totale di esecuzione.
Conclusioni
Per chi come me avesse avuto esperienza con linguaggi di sistema per costruire backend per schede embedded, che generalmente non hanno grosse potenze di calcolo, troverà il linguaggio Zig come una versione evoluta del C, rendendo lo stile di programmazione molto più moderno e piacevole. Infatti, mi è capitato di dover spendere molte energie per rendere un software C mantenibile e testabile in modo adeguato. Invece, Zig mette a disposizione molti strumenti in più, come la possibilità di fare test, meccanismi per migliorare l’organizzazione del codice, package manager, capacità di sfruttare l’I/O asincrono, cross compilazione e molto altro ancora. Tutto questo grazie al compilatore, alla libreria standard e ovviamente alla community.
Vuoi saperne di più su Zig? Leggi anche l’articolo compilazione statica di codice C++ con Zig