Quanti di voi hanno dovuto risolvere uno di questi problemi?
“Dato un campo di testo libero, implementare la ricerca dei prodotti di un catalogo per nome o categoria, mostrando per primi i risultati corrispondenti al nome e fornendo un autocompletamento all’utente.”
“Implementare un campo di ricerca di articoli con cui sia possibile ricercarli per nome tollerando eventuali errori di battitura.”
“Dato un database di prodotti venduti, individuare le 10 categorie più vendute dell’anno solare in corso e per ognuna restituire il prezzo medio.”
Se siete uno di loro o avete affrontato problemi similari, Elasticsearch è lo strumento che fa per voi!
Introduzione
Elasticsearch è un search engine distribuito, utilizzato per fare ricerche full-text search e analisi sui dati. Ad esempio, Wikipedia utilizza Elasticsearch per effettuare la ricerca instantanea degli articoli e fornire i relativi suggerimenti, mentre GitHub lo utilizza per ricercare il codice e Stack Overflow per la ricerca e per mostrare le domande correlate.
Tecnicamente parlando Elasticsearch è un software scritto in Java e basato su Apache Lucene, una libreria Java che implementa in modo molto efficiente la ricerca full-text search. Ma Lucene è solamente una libreria e per utilizzarla è necessario scrivere la propria applicazione in Java ed integrarsi direttamente con essa. Ancora peggio, Lucene è molto complesso da utilizzare e scrivere un’applicazione che ne fa uso richiede una profonda conoscenza della teoria della ricerca full-text search.
Elasticsearch usa internamente Lucene, ma espone una semplice API RESTful che ne astrae la complessità e che può essere utilizzata direttamente oppure attraverso uno dei client scritti in numerosi linguaggi (Javascript, Python, Ruby, Java, .NET, Perl, ecc..).
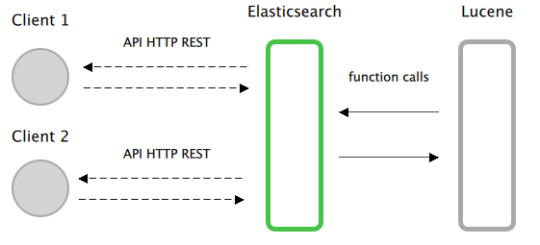
Ma Elasticsearch è anche un database orientato ai documenti, serializzati come JSON, capace di memorizzare documenti complessi, di ricercarli e con una struttura distribuita che permette di scalare facilmente fino ad avere centinaia di server e contenere petabyte di dati.
La struttura di un cluster
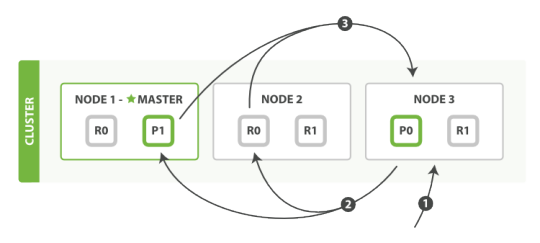
La classica configurazione di Elasticsearch è quella di un cluster con uno o più nodi dove ciascun nodo, corrispondente alla singola istanza di elasticsearch, è installato su un server o su una macchina virtuale.
Un concetto ortogonale è quello dell’index, che fa riferimento a una collezione di documenti aventi uno o più tipi (immaginabile quindi come un database in termini di database relazionali). Ogni index è composto da uno o più shard, corrispondenti ciascuno ad una singola istanza di Lucene, e che possono essere di due tipi:
- primari, nei quali i documenti possono essere inseriti o ricercati;
- replica, che possono essere usati per la sola ricerca e che possono essere promossi a primari in caso di necessità.
I documenti che fanno parte di un index verranno suddivisi in modo equo fra tutti gli shard primari che compongono l’index.
Elasticsearch distribuisce automaticamente gli shard configurati all’interno del cluster in modo da ottimizzarne robustezza e performance. Infatti, quando un client interroga un nodo del cluster quel nodo agirà come coordinatore interrogando tutti gli shard coinvolti nella ricerca, anche appartenenti ad altri nodi, e combinando le varie risposte in una unica, applicando logiche di aggregazione se presenti.
Grazie a questa struttura distribuita e flessibile Elasticsearch può gestire in modo efficiente un numero limitato di documenti ma scalare con facilità fino a gestirne milioni.
La ricerca
Se è possbile ricercare documenti in Elasticsearch con poco sforzo usando una semplice query string capace di supportare i più comuni operatori, la vera potenza di Elasticsearch emerge usando il suo query DSL. In questa seconda variante è possibile non solo cercare i vari documenti che soddisfano dei requisiti, ma anche influenzare l’algoritmo di scoring usato da Elasticsearch premiando alcuni documenti piuttosto che altri oppure filtrando alcuni risultati della ricerca secondo criteri più o meno complessi.
In aggiunta a questo, Elasticsearch permette di evidenziare i risultati della ricerca, fare aggregazioni sui risultati ottenuti o implementare logiche avanzate, come il “more like this” o il “did you mean?”.
La prima esecuzione
Installare e lanciare Elasticsearch è facile quanto bere un bicchiere d’acqua. Essendo scritto in Java, Elasticsearch richiede una virtual machine Java (Oracle o OpenJDK, nelle versioni 7 o 8) ed è capace di girare senza problemi su un gran numero di distribuzioni Linux, su Windows Server e su Solaris.
Dopo aver scaricato Elasticsearch (dal sito o dai repository ufficiali tramite apt o yum) ed estratto l’archivio per avviare Elasticsearch sarà sufficiente eseguire su sistemi *nix:
$ /bin/elasticsearchmentre su sistemi Windows:
$ /bin/elasticsearch.bate iniziare a sperimentare!
$ curl -X GET http://localhost:9200/
{
"status" : 200,
"name" : "Xemu",
"cluster_name" : "elasticsearch",
"version" : {
"number" : "1.7.3",
"build_hash" : "05d4530971ef0ea46d0f4fa6ee64dbc8df659682",
"build_timestamp" : "2015-10-15T09:14:17Z",
"build_snapshot" : false,
"lucene_version" : "4.10.4"
},
"tagline" : "You Know, for Search"
}Per approfondire:
- guida definitiva: https://www.elastic.co/guide/en/elasticsearch/guide/current/index.html
- reference: https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html