Attività di I/O su dispositivi a blocchi in Linux
Introduzione
Dai primi calcolatori elettronici ad oggi, la capacità di storage è aumentata vertiginosamente. Se è vero però che la capacità delle memorie rappresenta raramente un problema, altrettanto non si può dire per le loro prestazioni.
Negli ultimi anni, il gap di performance tra processori e memorie è aumentato sempre di più, a sfavore di queste ultime: ad un aumento di prestazione dei processori è sempre corrisposto un aumento di prestazione delle memorie nettamente inferiore.
Questo gap diventa chiaramente più marcato man mano che scendiamo nei livelli della memory hierarchy. Per dare un’idea, consideriamo che il tempo medio impiegato per leggere 1KB da un SSD moderno è di circa 50 µs, mentre un accesso alla memoria centrale impiega mediamente 100 ns. Una differenza pari ad un fattore 500!
Da questi numeri si capisce l’esigenza di analizzare l’efficienza del pattern di I/O delle nostre applicazioni. Questo tipo di analisi risulta sicuramente indispensabile per DBA e DevOps che devono monitorare l’efficienza dei loro server in produzione. Ma non solo. Nell’ambito dei sistemi embedded, troviamo spesso schede che si affidano a MMC per lo storage non volatile. Le MMC, in Linux, sono gestite come dispositivi a blocchi e il loro tempo di vita dipende dal tasso di scritture che effettuiamo su di esse (e dalla loro composizione).
Saper analizzare il pattern di I/O delle nostre applicazioni ci permette quindi di ottenere, in diversi ambiti, migliori performance e maggiore affidabilità.Per poter effettuare questa analisi in maniera consapevole, è necessario capire prima come si arriva da una richiesta di lettura o scrittura, nel codice delle nostre applicazioni, ad un’analoga operazione eseguita dal dispositivo di storage.
Linux I/O Stack
Iniziamo chiedendoci: cosa succede quando eseguiamo una lettura o una scrittura da un dispositivo a blocchi nel nostro codice?
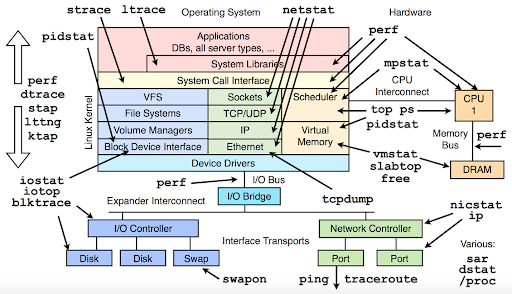
Per interagire con un dispositivo a blocchi, lo sviluppatore esegue delle chiamate di libreria (libcall), ma queste non si traducono immediatamente in analoghe attività di I/O sul device.
Un primo livello di buffering e aggregazione lo abbiamo proprio all’interno delle librerie standard del linguaggio utilizzato.
In user space, però, è piuttosto immediato vedere cosa succede: su Linux possiamo utilizzare il tool strace per vedere come le libcall si traducono in chiamate di sistema al kernel (syscall). Grazie ad strace, possiamo capire come le librerie standard manipolano le nostre richieste di I/O nel tentativo di renderle più efficienti.
Di seguito, mostriamo un estratto dell’output di strace, che riporta le syscall read e write effettuate da un run di dd:
$ strace dd if=/dev/urandom of=/tmp/test.tmp bs=512K count=8
...
write(1, "5\10\303h\2178>\275\0\254\352\r\202\6\36:\205\345\00258'\37HL\270\244^\374{\24\304"..., 524288) = 524288
read(0, "\245\367\304\215\200\20\304\21\273\241[u\214\324\265\256(V\31\6\31\341\212+z\341\247\205Hq\235R"..., 524288) = 524288
write(1, "\245\367\304\215\200\20\304\21\273\241[u\214\324\265\256(V\31\6\31\341\212+z\341\247\205Hq\235R"..., 524288) = 524288
...Per ciascuna syscall effettuata, possiamo vedere il numero di byte letti o scritti.
Entrando in kernel space, le cose si complicano. Una richiesta di I/O deve attraversare diversi strati prima di raggiungere il dispositivo fisico:
- Virtual File System e Page Cache
- File System
- Block I/O layer
- Device driver
Vediamo quindi lo scopo di ciascun layer, e quali sono gli effetti che si possono avere sulle richieste di I/O effettuate in user space.
Virtual File System
Il kernel Linux fornisce un layer di astrazione sopra alle implementazioni dei vari file system. Questo strato prende il nome di Virtual File System e serve proprio per uniformare l’API che i vari file system presentano agli strati superiori. Secondo la filosofia UNIX “everything is a file”, in user-space dobbiamo poter operare con ogni oggetto attraverso le classiche syscall open, close, read, write, e ioctl. Il VFS si occupa di smistare queste richieste al file system specifico dove risiede il file oggetto della syscall.
Il VFS, inoltre, integra una cache denominata Page Cache. Si tratta di un meccanismo di caching dove pagine di memoria principale vengono utilizzate per mantenere dati provenienti dai dispositivi a blocchi sottostanti, accelerando le operazioni di lettura e scrittura. A questo livello, quindi, il kernel lavora con la granularità di una pagina di memoria. In caso di cache hit, la richiesta di I/O non giunge allo strato di file system vero e proprio, ma viene servita direttamente dalla Page Cache.
È possibile bypassare la Page Cache aprendo un file con il flag O_DIRECT.
Proviamo a vedere in azione la Page Cache, per capire i vantaggi che porta.Utilizzando free possiamo vedere, sotto la colonna “Cache”, la quantità di memoria utilizzata dalla Page Cache:
$ free -w -h
total used free shared buffers cache available
Mem: 31Gi 4,4Gi 25Gi 519Mi 1,0Mi 1,2Gi 26Gi
Swap: 31Gi 0B 31GiUsiamo dd per generare un file con contenuto pseudo-casuale di 512 MB:
$ dd if=/dev/urandom of=/tmp/test.tmp bs=512K count=1024
1024+0 record dentro
1024+0 record fuori
536870912 bytes (537 MB, 512 MiB) copied, 8,71077 s, 61,6 MB/sCome si vede, il contenuto del file appena creato è stato portato in cache, infatti questa è aumentata di una dimensione pari al file creato:
$ free -w -h
total used free shared buffers cache available
Mem: 31Gi 4,4Gi 25Gi 530Mi 3,0Mi 1,8Gi 26Gi
Swap: 31Gi 0B 31GiUtilizziamo sync per chiedere al kernel di fare un flush della cache, dopodiché eliminiamo il contenuto attuale della page cache:
$ sync; echo 1 > /proc/sys/vm/drop_cachesLa porzione di memoria occupata dalla cache è infatti diminuita:
$ free -w -h
total used free shared buffers cache available
Mem: 31Gi 4,4Gi 25Gi 522Mi 1,0Mi 1,3Gi 26Gi
Swap: 31Gi 0B 31GiProviamo adesso a leggere il contenuto del file, scartando il risultato della lettura:
$ time dd if=/tmp/test.tmp of=/dev/null
1048576+0 record dentro
1048576+0 record fuori
536870912 bytes (537 MB, 512 MiB) copied, 0,452967 s, 1,2 GB/s
real 0m0,459s
user 0m0,087s
sys 0m0,316sAdesso che la Page Cache è hot, leggiamo nuovamente e valutiamo l’impatto sulle performance di un cache hit:
$ time dd if=/tmp/test.tmp of=/dev/null
1048576+0 record dentro
1048576+0 record fuori
536870912 bytes (537 MB, 512 MiB) copied, 0,358469 s, 1,5 GB/s
real 0m0,359s
user 0m0,096s
sys 0m0,263sIl tempo impiegato per effettuare la lettura è notevolmente inferiore. In particolare, la differenza risiede nel tempo speso per eseguire codice in kernel space, cioè il codice relativo alle letture: grazie alla Page Cache risultano più veloci.
File System
Il File System si occupa principalmente di organizzare i dati su disco, in maniera strutturata. In questo layer, l’unità fondamentale è il blocco. È possibile vedere la dimensione del blocco di un certo file system (tipicamente 4 KB), usando tune2fs e indicando il device di interesse:
$ tune2fs -l /dev/mapper/bullseye--vg-home | grep -i "block size"
Block size: 4096Per organizzare in modo strutturato i blocchi di dati, il file system vi associa dei metadati, che hanno lo scopo di descrivere diverse proprietà dei dati stessi, come permessi di accesso, ultima data di modifica, ecc. In Linux, uno dei file system più diffusi è sicuramente ext4. In ext4, i metadati sono conservati negli inode. Una trattazione approfondita di ext4 va oltre gli scopi di questo articolo, ma è importante ricordare che file system diversi utilizzano schemi diversi per allocare i blocchi su disco: questo ha delle ripercussioni sulla quantità di scritture che avvengono sul device fisico. Oltre al tipo di file system adottato, anche alcune opzioni di configurazione di uno stesso file system determinano un’attività diversa per i layer sottostanti. Con riferimento ad ext4, consideriamo, ad esempio, il journaling.
Il journal è un’area dedicata del disco dove viene salvato un log delle operazioni da eseguire, insieme ai dati e metadati oggetto di queste operazioni. Utilizzando il full journaling, prima di apportare effettivamente le modifiche ai file sul file system principale, è necessario che dati e metadati vengano scritti sul journal. In questo modo, in caso di shutdown improvviso della macchina, al successivo riavvio è possibile replicare quanto descritto nel journal, completando le operazioni interrotte e riportando il file system in uno stato consistente. Il journaling riduce il throughput di scrittura, ma garantisce una maggiore affidabilità.
ext4 fornisce 3 impostazioni per il journaling:
- “data=journal”: tutti i dati sono salvati sul journal prima di effettuare modifiche su disco.
- “data=ordered”: solo i metadati sono scritti nel journal. Inoltre, ogni scrittura fa sì che i dati vengano scritti sul file system principale prima che i relativi metadati siano scritti nel journal.
- “data=writeback”: come in ordered mode, solo i metadati sono salvati sul journal. La differenza risiede nell’ordinamento relativo tra la scrittura dei dati e dei relativi metadati: non c’è alcuna garanzia che i primi siano scritti sul file system principale prima che i secondi siano stati committati nel journal. In caso di shutdown improvviso della macchina, per tutti i file modificati recentemente, è possibile che il processo di recovery esponga dati vecchi associati però a metadati nuovi: in alcuni casi, questo può portare a problemi di sicurezza. Dei metadati, infatti, fanno anche parte i permessi del file.
La modalità writeback garantisce le performance più elevate, mentre la modalità journal garantisce l’affidabilità massima. Di default, un filesystem ext4 utilizza la modalità ordered.
Block I/O Layer
A questo livello, il kernel deve gestire una coda di richieste per operazioni di lettura e scrittura su blocchi. In Linux, ciascun blocco è rappresentato da un’istanza della struct bio. Queste strutture vengono incapsulate in una struct request, che rappresenta una richiesta da portare a termine.
Per gestire in maniera efficace le richieste, il kernel utilizza un apposito scheduler di I/O.
L’I/O scheduler ha lo scopo di massimizzare il throughput totale da e verso il dispositivo a blocchi, senza introdurre una latenza eccessiva (starvation) per singole richieste di I/O.
Per raggiungere questi obiettivi, lo scheduler può effettuare reordering, merge e split delle richieste di I/O accodate.
In Linux, anche questo componente è configurabile: la strategia di scheduling può cambiare per cercare di ottimizzare l’una o l’altra metrica.
Gli scheduler I/O più comuni sono:
- deadline: cerca di limitare picchi di latenza, assegnando a ciascuna richiesta una deadline entro la quale portare a termine la richiesta stessa. Le letture sono prioritizzate rispetto alle scritture.
- cfq: le richieste vengono allocate in code distinte per ciascun processo e a ciascuna coda viene allocato un time slice basato sull’I/O priority del processo associato. L’obiettivo è garantire fairness a livello globale, cioè garantire che non esistano richieste che risultino particolarmente svantaggiate e che possano subire latenze eccessive prima di essere servite.
- mq-deadline: versione multiqueue dello scheduler deadline. I moderni device a blocchi supportano, a livello hardware, più code di I/O distinte. Insieme ai moderni processori multicore, è possibile parallelizzare l’attività di I/O.
- noop: non effettua alcun riordino delle richieste, solo merging. È indicato per dispositivi a blocchi con controller avanzati che effettuano già internamente un eventuale riordino delle operazioni di I/O sui settori, oppure in ambienti virtualizzati, dove è preferibile che sia l’I/O scheduler dell’host a ottimizzare globalmente le richieste di I/O.
- none: versione multiqueue dello scheduler noop, ideale per device NVME.
Mediante sysfs possiamo vedere il Block I/O scheduler selezionato per un dato device:
$ cat /sys/block/nvme0n1/queue/scheduler
[none] mq-deadlineSe vogliamo modificare l’I/O scheduler, ad esempio con mq-deadline:
# echo "mq-deadline" > /sys/block/nvme0n1/queue/scheduler
$ cat /sys/block/nvme0n1/queue/scheduler
none [mq-deadline]Per rendere permanente la modifica, è però necessario modificare il file di configurazione del bootloader.
Device Driver
Il Device Driver del supporto di storage si occupa principalmente di tradurre le richieste I/O per i blocchi in corrispondenti richieste I/O per settori. Utilizzando fdisk possiamo valutare la dimensione dei settori del nostro supporto fisico, riportata alla voce Sector size:
$ fdisk -l /dev/nvme0n1
Disk /dev/nvme0n1: 931,53 GiB, 1000204886016 bytes, 1953525168 sectors
Disk model: Sabrent Rocket 4.0 1TB
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
...Oltre al mapping da blocchi a settori, il device driver si occupa di inviare gli opportuni comandi di basso livello al supporto fisico, per servire effettivamente le varie richieste. La maggior parte della volte, l’analisi del pattern di I/O non riguarda questo strato: i driver sono considerati affidabili e, pur essendo il loro codice open source, la loro comprensione necessita delle specifiche di basso livello del supporto di storage, non sempre facilmente reperibili.
Pertanto, questo layer viene solitamente trattato come una “black box”.
Conclusioni
Analizzando l’I/O stack di Linux, possiamo capire l’importanza del Block I/O Layer. Il supporto di storage ”vede” in ingresso ciò che il suo device driver gli invia, ma questo dipende strettamente da quello che succede nel layer immediatamente superiore, cioè nel Block I/O Layer. Per effettuare un’analisi precisa, diventa rilevante, quindi, capire le caratteristiche del pattern di I/O a livello di blocco, e come possiamo migliorarlo in funzione dei nostri obiettivi: migliori performance, maggiore affidabilità, ecc.
Nella seconda parte dell’articolo vedremo quali strumenti possiamo utilizzare per analizzare l’attività del Block I/O layer, in risposta alle operazioni di I/O in user space delle nostre applicazioni.