AVL – Localizzazione automatica di un treno
Lo scopo di questo articolo è quello di fornire una panoramica di un algoritmo di localizzazione automatica di veicolo (AVL), con riferimento in particolare ad un’applicazione ferroviaria, ovvero un veicolo treno. Vorrei presentare alcune considerazioni e problemi che sono emersi durante la fase di studio e come sono stati affrontati nel sistema su cui ho lavorato.
Un sistema AVL può essere utilizzato in molti settori differenti e le problematiche, nonché le scelte architetturali, possono variare notevolmente, anche a fronte dell’hardware a disposizione e dei vincoli di progetto. L’obiettivo della localizzazione automatica è quello del tracciamento di veicoli d’interesse, come ad esempio quelli di trasporto pubblico, ma anche in caso di trasporto merci speciali, monitoring ed altro ancora.
Nel caso dell’applicazione ferroviaria su cui ho lavorato, le funzionalità principali derivate dalla localizzazione sono:
- Gestione delle rotte (numerazione, destinazione, prossima stazione, etc…).
- Informazioni sul ritardo o anticipo del servizio.
- Richiesta segnale semaforico di priorità.
- Invio comandi al sistema di interlocking, per cambiare direzione.
- Annunci al pubblico tramite altoparlanti.
- Visualizzazioni di informazioni testuali sui pannelli di bordo.
Dispositivi di localizzazione treno
Il sistema AVL per il treno su cui ho lavorato era basato principalmente su una localizzazione discreta, tramite dispositivi RFID (Radio-Frequency Identification), in aggiunta ad un sottosistema odometrico che fornisce un’informazione continua di spostamento e velocità.
Lungo i binari vengono installate delle boe/tag e a bordo treno ci sono dei lettori tag. Quando un lettore tag passa sopra ad una boa, esso ne legge il suo codice identificativo. Questo meccanismo fornisce un sistema di localizzazione discreto, in quanto è possibile localizzare il veicolo in un punto preciso. Inoltre è conosciuta anche la distanza tra le varie boe, lungo una rotta.
L’odometro è un componente complesso e molto importante che solitamente è presente a bordo treno. Esso, tramite sensori, è in grado di fornire stime molto precise di velocità e lo spazio percorso dal treno. Le informazioni dell’odometro, opportunamente combinate con le letture dei tag, permettono di avere una localizzazione continua del treno lungo la rotta, con un dettaglio sufficientemente preciso a fini delle applicazioni ferroviarie.
Come informazione aggiuntiva di backup è anche possibile utilizzare un segnale GPS. Esso richiede un trattamento speciale per avere una precisione adeguata, al fine di essere correlata ad un punto valido sulla rotta. Tuttavia non approfondirò questo argomento in questo articolo.
Un altro dettaglio importante per conoscere la posizione di un treno è sapere qual è la cabina di guida, ovvero la cabina di testa rispetto a quella di coda. Infatti le cabine di un treno sono intercambiabili, dato che il movimento può avvenire in entrambi i versi lungo una stessa direzione. Questa informazione è resa disponibile da un input digitale (DIGIO), che risulta essere attivo quando il macchinista inserisce le chiavi nella cabina di guida.
Infine, la posizione calcolata dal sistema AVL può essere comunicata all’esterno in vari modi. Il sistema su cui ho lavorato faceva uso di un’antenna TETRA (Terrestrial Trunked Radio), connessa col centro di controllo, ma esistono anche soluzioni basate su IP. Non entrerò però nel merito di questa parte.
Modello semplificato di un treno
L’algoritmo AVL che è stato realizzato si basa su un modello treno semplificato, che tiene in considerazione solo gli aspetti che sono stati brevemente menzionati nei paragrafi precedenti e che si può osservare nella figura seguente:
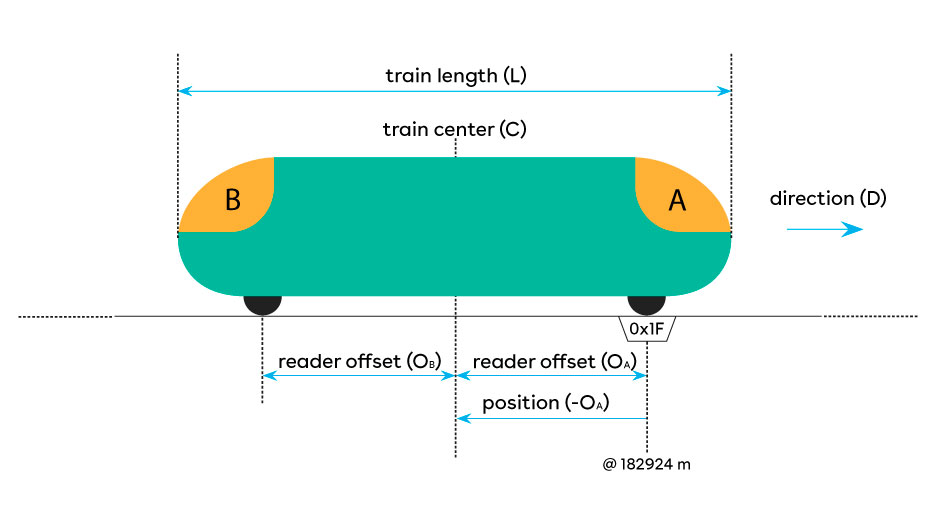
Il veicolo è modellato come due cabine simmetriche, chiamate A e B, con una lunghezza fissa di L metri. La localizzazione è sempre fornita come una distanza dal centro del treno, in metri, rispetto ad una determinata boa posizionata sul percorso. Sotto il veicolo sono installati uno o più lettori di tag RFID. Il numero di lettori non è vincolato e se ne possono usare più di uno. Ogni lettore è assegnato in modo fisso ad una delle due cabine e si trova ad un certo scostamento, in metri, rispetto al centro. Ogni lettore può essere posizionato ad una qualsiasi distanza dal centro ed assegnato ad una qualsiasi cabina. Nel progetto su cui ho lavorato i lettori erano posizionati alle estremità opposte del treno e ad una distanza simmetrica rispetto al centro.
Localizzazione continua
Il funzionamento base di localizzazione si basa sulla sincronizzazione della posizione discreta rispetto ad un certo tag e la successiva unione con lo spostamento odometrico, in modo da avere una localizzazione continua:
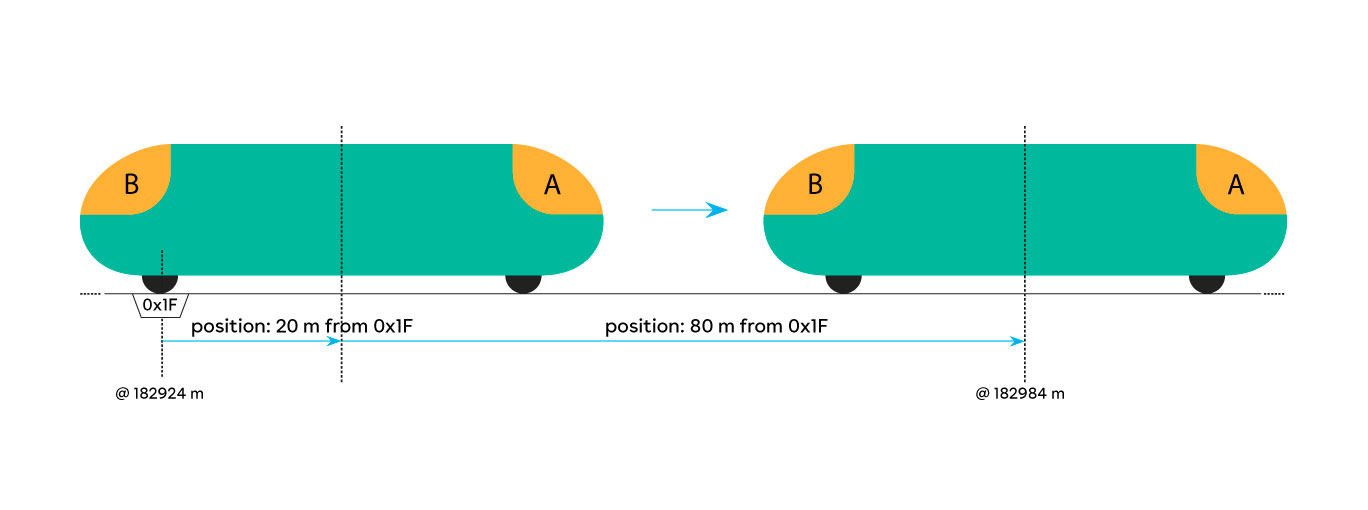
I valori odometrici vengono misurati in modo continuo, in modo da calcolare l’incremento di spostamento (delta). Questo incremento è sempre applicato alla più recente posizione discreta, aggiornata ogni volta che si incontra un nuovo tag. Quindi si verifica un movimento nel verso di marcia, in accordo alla cabina di guida. Si assume che il treno si muova sempre nel verso della cabina di guida. Questa assunzione porta al seguente comportamento, dove O è l’offset del reader e T è l’identificativo del tag letto:
- La posizione del treno è -O metri da T, quando il lettore è associato alla cabina di testa.
- La posizione del treno è +O metri da T, quando il lettore è associato alla cabina di coda.
Questo significa che la posizione viene mantenuta in riferimento al tag incontrato più recente.
Nel caso il veicolo dovesse muoversi senza una cabina attiva (di guida), allora la localizzazione sarà inaccurata, ma comunque possibile.
Lo stesso delta descritto in precedenza può causare un movimento all’indietro, nel caso in cui la retromarcia sia attivata (altra informazione fornita dal sottosistema odometrico).
C’è però un limite affinché questo delta possa essere considerato valido (ad es. al massimo 500 m), al fine di evitare sbalzi eccessivi. Se uno sbalzo del genere dovesse accadere, allora soltanto il passaggio al di sopra di una nuova boa potrà ristabilire il meccanismo di localizzazione continua del treno. Un delta eccessivo potrebbe essere causato, ad esempio, da qualche sorta di problema di comunicazione con l’odometro (che comunque è anche un errore rilevabile a livello diagnostico).
L’unione dell’informazione odometrica con quella proveniente dalle boe è soggetta ad un errore, a causa delle misurazioni discrete. Infatti, supponiamo che il sottosistema odometrico fornisca dati ogni 250 millisecondi e che il treno abbia una velocità massima di 72 km/h. Con questi dati, il massimo spostamento E che il veicolo può assumere, proprio in un lasso di tempo di 250 ms è:
E = 72000 [m] / 3600 [s] / 4 = 5 [m]
Ovvero il treno potrà trovarsi al più 5 metri lontano rispetto alla sua ultima posizione letta 250ms fa e questo vuol dire che, sotto queste condizioni, l’errore odometrico E è al più 5 metri.
Inoltre, siccome l’offset di un lettore tag è specificato anch’esso in metri (come risulta dal modello semplificato), allora possiamo al più avere un altro metro di scarto. L’ultima sorgente di approssimazione è data dall’errore di arrotondamento da decimetri a metri, che occorre quando i valori odometrici espressi in decimetri sono convertiti in metri, dato che tutte le misure sono sempre tracciate in metri.
Calcolo delle distanze su una rotta
L’algoritmo AVL mantiene una rappresentazione di un percorso sul quale ci aspettiamo che il treno si muova. Questa rappresentazione è composta da una lista di coppie <T, D> dove T è il codice della boa e D è la distanza (in metri) rispetto alla boa precedente. La lista di tutte queste coppie forma quella che si definisce una rotta e spesso si identifica con un numero, come potrebbe essere 10301.
Ogni punto lungo il percorso ha anche una distanza rispetto ad uno stesso punto di riferimento, che è solitamente l’ultima boa incontrata. Tutte le distanze vengono di volta in volta aggiornate rispetto al nuovo punto di riferimento, rappresentato dal tag 0x2B nella figura seguente:
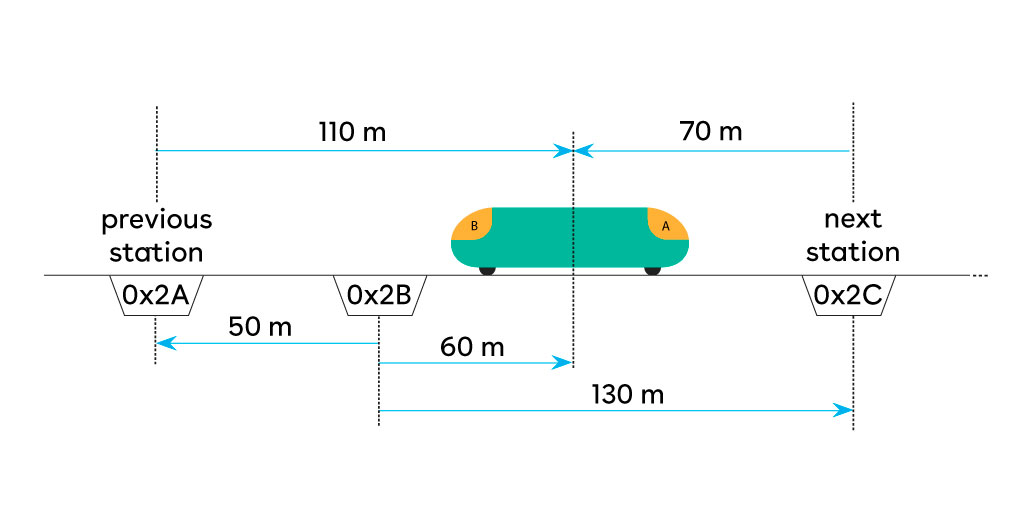
Si nota come il treno abbia rilevato il tag 0x2B e come tutti gli altri elementi facciamo di conseguenza riferimento a quest’ultimo per il calcolo della distanza. Siccome le distanze sono vettori, la distanza effettiva della stazione 0x2A dal punto di riferimento 0x2B è -50 metri. La posizione del centro del veicolo è essa stessa un punto di localizzazione che, in questo esempio, ha una distanza di 60 metri dal riferimento 0x2B (chiamata “distanza treno” per semplicità).
Altri due punti di localizzazione importanti sono a stazione precedente e successiva. Esse servono soprattutto per distribuire informazioni ad altri utilizzatori, come i passeggeri ed il macchinista, rispettivamente attraverso annunci al pubblico o display e l’interfaccia grafica di guida. Sempre in riferimento a questo esempio, la distanza dalla stazione precedente è 110 metri, mentre la distanza dalla stazione successiva è -70 metri.
Nel momento in cui una nuova rotta viene assegnata al sistema di bordo, la sua definizione viene recuperata dal database interno e le seguenti operazioni prendono atto:
- La destinazione ed il numero del servizio sono visualizzate sui pannelli al pubblico.
- Le distanze dalle stazioni precedente e successiva sono calcolate.
- Comandi di richiesta semaforica sono eventualmente richiesti, in base alla posizione corrente del treno.
- Comandi di interlocking sono eventualmente inviati, per pilotare gli scambi ferroviari.
- Si effettua una diagnostica per identificare eventuali boe mancanti lungo la rotta.
- La nuova posizione del treno viene calcolata in accordo alla nuova rotta.
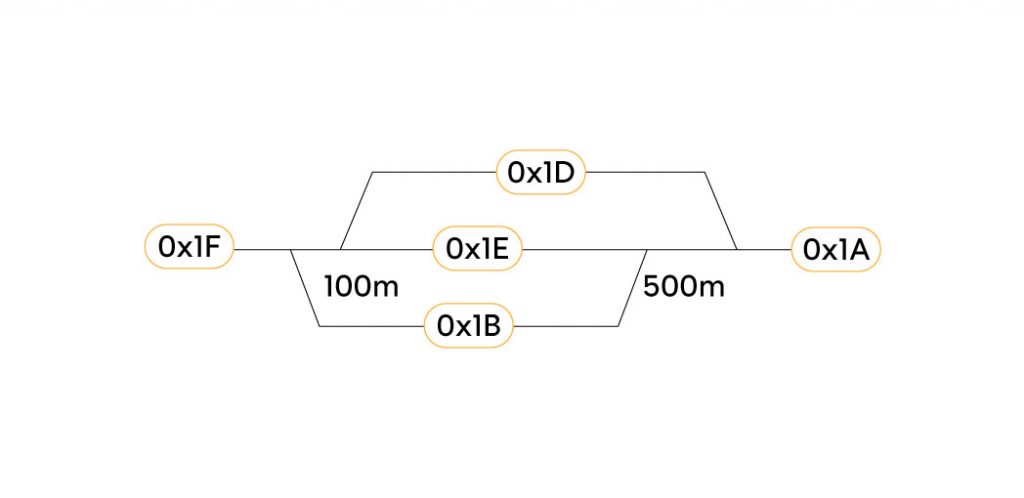
Lo stesso insieme di identificativi tag si può utilizzare per definire una serie di rotte. In riferimento alla figura seguente, potremmo definire le rotte:
- 10301: 0x1F – 0x1E – 0x1A
- 10401: 0x1F – 0x1B – 0x1A
- …etc.
Associazione del verso di movimento
Come abbiamo visto, una rotta è una sequenza di tag e viene percorsa con l’assunzione che il primo tag debba essere incontrato per primo, poi il secondo e così via, seguendo la sequenza definita. Quindi implicitamente il verso è definito dalla sequenza stessa. Ma quand’è che questa informazione risulta davvero utile? Serve in particolare quando si confrontano due rotte diverse, per sapere se i loro versi sono concordi oppure opposti.
Ecco un esempio di due rotte con verso concorde:
- 20101: …, 0x1F, 0x1E, 0x1A
- 20301: 0x1E, 0x1A, 0x1D, 0x1B, …
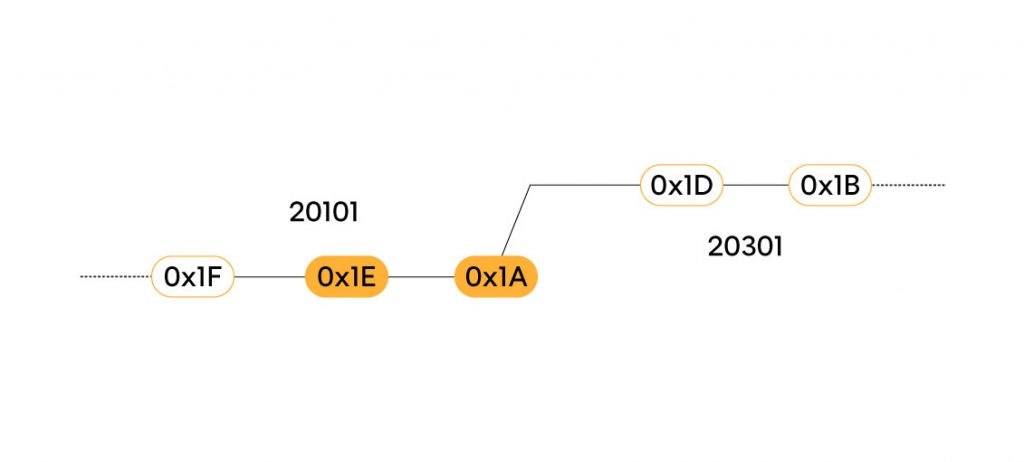
L’algoritmo di AVL analizza la sequenza di tag in entrambe le rotte e capisce che hanno due punti in comune, ovvero 0x1E e 0x1A. Inoltre questi due punti sono ordinati nello stesso modo (prima 0x1E e dopo 0x1A). Per questa ragione le rotte 20101 e 20301 hanno verso concorde (non è comunque necessario che la sequenza sia esattamente la stessa, ma qualsiasi coppia trovata sarà sufficiente).
Ecco invece un esempio di due rotte con verso opposto:
- 20401: …, 0x1F, 0x1E, 0x1A
- 20501: 0x1A, 0x1E, 0x1B, 0x1D, …
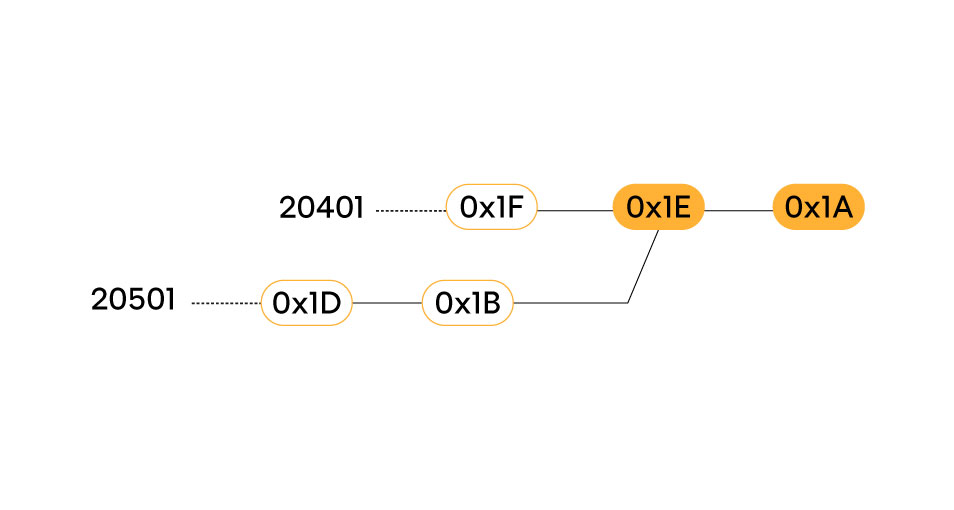
In questo caso la coppia di punti (0x1E, 0x1A) ha ordine inverso, confrontando le due rotte, quindi 20401 e 20501 hanno verso opposto.
Ma quando viene effettuata davvero questa analisi di cui abbiamo parlato ed a cosa serve? Il calcolo viene fatto quando al sistema di bordo viene assegnata una nuova rotta e serve ad effettuare una correzione della posizione corrente del treno.
Ad esempio, supponiamo che il treno sia posizionato a -10 metri dal tag 0x1A sulla rotta 20101 e che la nuova rotta 20301 sia stata selezionata. Dal momento che le due rotte hanno verso concorde, il treno sarà ancora a -10 metri da 0x1A sulla rotta 20301.
Al contrario, supponiamo che il treno sia a -10 metri da 0x1A sulla rotta 20401 e che sia selezionata la nuova rotta 20501. Dal momento che queste due rotte sono opposte, la nuova posizione del treno sarà definita da una distanza di 10 metri da 0x1A.
La regola generale è che, qualora due rotte siano opposte, il segno della distanza treno è ogni volta invertito, senza effettuare ulteriori calcoli. Per questa ragione il database delle rotte deve essere costruito in modo che ci siano sempre almeno due tag in comune, in modo che l’algoritmo descritto possa funzionare correttamente.
Avvicinamento in banchina
Una funzionalità molto importante dell’algoritmo AVL è quella dell’avvicinamento in banchina, che rappresenta un parte essenziale del servizio offerto dal trasporto ferroviario. Siccome AVL mantiene sempre la distanza del treno dalle stazioni precedente e successiva, è in grado di calcolare il tempo di arrivo ed anche la distanza mancante. Questi dati sono forniti principalmente al centro di controllo ed all’interfaccia grafica di guida, in modo che il macchinista possa allinearsi (ma può essere usata anche da sistemi senza conducente driverless). Questi calcoli si basano sul modello di banchina illustrato qui di seguito:
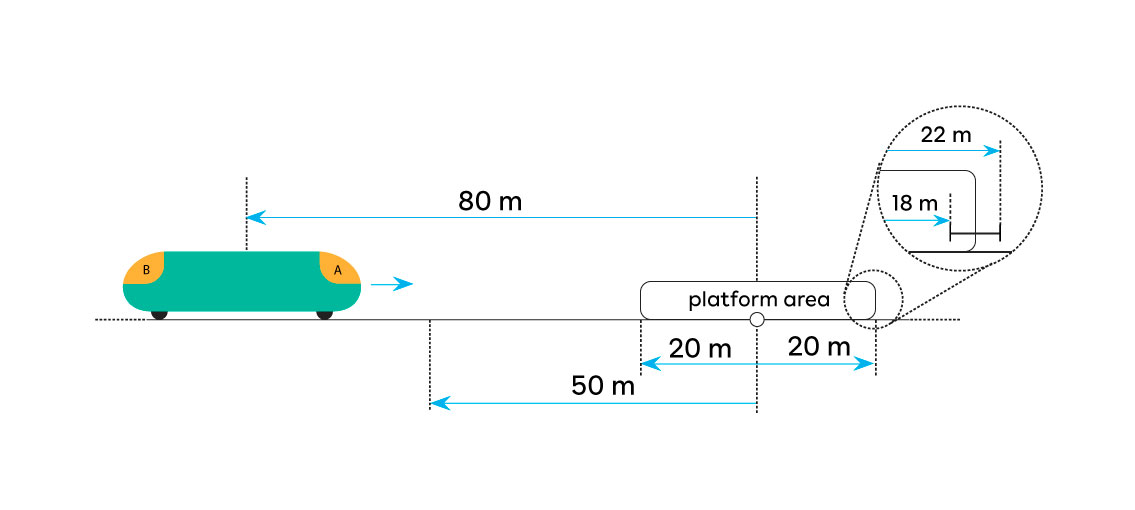
Ogni qual volta la posizione treno subisce uno spostamento, l’algoritmo AVL aggiorna i dati di avvicinamento alla prossima stazione, confrontando la distanza corrente (80 metri nell’esempio) con due parametri:
- Una soglia per definire la funzionalità di avvicinamento (50 metri in figura).
- La lunghezza della banchina (20 metri in figura).
Il primo parametro è utile per definire quando il veicolo è ancora lontano dalla banchina, ma si sta comunque avvicinando. L’algoritmo AVL inizia allora a pubblicare la distanza di avvicinamento a tutti gli altri componenti interessati a tale informazione. La notifica si interrompe immediatamente se la retromarcia viene inserita, dato che il treno in questo caso non si sta più avvicinando, anche se si trova entro la soglia di avvicinamento.
Il secondo parametro invece serve a capire quando il treno risulta essere entrato già nell’area di banchina. In questa situazione la distanza dalla banchina viene sempre notificata, anche se il treno va leggermente in retromarcia. Infatti il macchinista potrebbe essere “andato lungo” e quindi voler correggere la sua posizione tornando leggermente indietro. Per questa ragione è sempre interessato a valutare l’allineamento con il centro banchina. D’altro canto però, nel momento in cui il treno supera completamente la banchina (20 metri dopo il centro banchina), allora tale notifica viene interrotta immediatamente. La tabella seguente riassume tutte le condizioni per cui la notifica di avvicinamento viene inviata:
| Posizione rispetto alla banchina | Retromarcia | Entro soglia di avvicinamento | Entro soglia di banchina | Invio notifica di avvicinamento |
| avvicinamento | sì | sì | no | no |
| avvicinamento | no | sì | no | sì |
| allontanamento | sì | sì | no | sì |
| allontanamento | no | sì | no | no |
| * | * | sì | sì | sì |
| * | * | no | no | no |
Arrivo in stazione e partenza
I dati di avvicinamento in banchina sono anche necessari per generare due importanti eventi di servizio, che sono l’arrivo in stazione e la partenza da stazione. Le condizioni per cui l’arrivo è rilevato sono le seguenti:
- Il treno si deve trovare nell’area di banchina (ovvero nell’intervallo [-20m, +20m] in figura).
- La velocità del treno deve essere 0 km/h.
- Il treno non si è già fermato alla stazione corrente.
Per ogni stazione, l’evento di arrivo è generato una sola volta. Affinché possa essere generato un nuovo evento, il veicolo deve abbandonare la stazione e rientrarci nuovamente. Quindi se il treno effettua degli aggiustamenti di posizione in banchina, non si generano eventi multipli di arrivo. Altri componenti di bordo possono agganciarsi all’evento di arrivo in stazione, ad esempio per mostrare un conto alla rovescia di attesa, aprire le porte, annunciare il nome della stazione e così via.
L’evento opposto è quello di partenza e viene generato dall’algoritmo di AVL quando il treno lascia definitivamente l’area di banchina (in qualsiasi verso). Il caso comune è che il treno si muoverà verso la prossima stazione, quindi il meccanismo di avvicinamento non entrerà in azione fino a che la soglia di avvicinamento non sarà nuovamente superata. L’evento di partenza da stazione è generato anche in casi in cui il treno passi da una stazione senza fermarsi. L’unico vincolo per la generazione di una partenza è che il treno si trovi entro l’area di avvicinamento/allontanamento. Questo controllo serve a prevenire eventi di partenza falsi, soprattutto quando si opera il veicolo in scenari degradati, come guidare nel verso della cabina inattiva.
Il modello di banchina mostra anche un dettaglio importante riguardo la lunghezza della banchina stessa. In particolare è stato necessario applicare una soglia con isteresi, centrata sul valore della lunghezza (20 metri nell’esempio). Lo scostamento dell’isteresi dipende dall’errore atteso sull’odometria (caratteristica del sottosistema odometrico), che nell’esempio risulta essere 2 metri. Per questa ragione il valore di 20 metri è modificato in modo tale da ottenere una soglia interna di 18 metri ed una esterna di 22 metri. Quindi per affermare che il treno si trova dentro l’area di banchina, la sua distanza deve essere sotto i 18 metri, se al momento della valutazione si trova all’esterno. Al contrario, per dire che il treno si trova fuori dall’area di banchina, allora la sua distanza deve superare i 22 metri, se al momento si trova in banchina. Questo calcolo è valido in entrambi i versi. La soglia con isteresi è utile per evitare glitch sulla rilevazione di arrivo e partenza. Infatti, siccome la localizzazione continua è soggetta ad un errore di misura, come descritto nei paragrafi precedenti, la sincronizzazione con una boa potrebbe far saltare la posizione leggermente indietro oppure in avanti. Questo piccolo salto, seppur minimo, potrebbe causare l’uscita, nonché l’immediata entrata, causando poi un falso evento di partenza. Un problema del genere si può evitare tarando correttamente i valori della soglia con isteresi, in base alla precisione dei sensori di posizionamento.
Conclusioni
Un algoritmo di localizzazione deve tener conto di molti scenari che spesso sono specifici di una certa tipologia di veicolo. Anche se alcuni concetti possano essere generalizzati, ci sono molti dettagli che influenzano l’algoritmo e quindi la soluzione finale. Nel caso del settore ferroviario, molte considerazioni si basano infatti su un movimento vincolato lungo una certa rotta e direzione, che può avvenire solo in due versi. Molto diverso sarebbe il caso di localizzare un mezzo su strada.
Tuttavia ci sono anche altre problematiche che, pur non essendo state affrontate in questo articolo, sono state considerate per la soluzione treno e che richiedono la definizione di altri modelli, come le seguenti:
- Definizione di aree di infotainment per gli annunci al pubblico: AVL può definire altre aree di interesse al fine di generare eventi di tipo diverso, ma che servono per espletare un corretto servizio al pubblico.
- Operazioni di segnalamento ferroviario: comunicazione con un sistema di interlocking di terra, al fine di pilotare gli scambi ferroviari.
- Operazioni di priorità semaforica: comunicazione con un sistema esterno per la richiesta del semaforo verde, al passaggio del treno.
- Diagnostica per rilevare e gestire l’assenza boe.
- Gestione di ridondanza delle informazioni, per non perdere il posizionamento acquisito.
Tutto questo però sarebbe sicuramente materiale per un altro articolo!